3.7 KiB
11月8日本周科研工作进展
1.修改模型设计,对每个任务增加不同的独立参数空间
原设计:
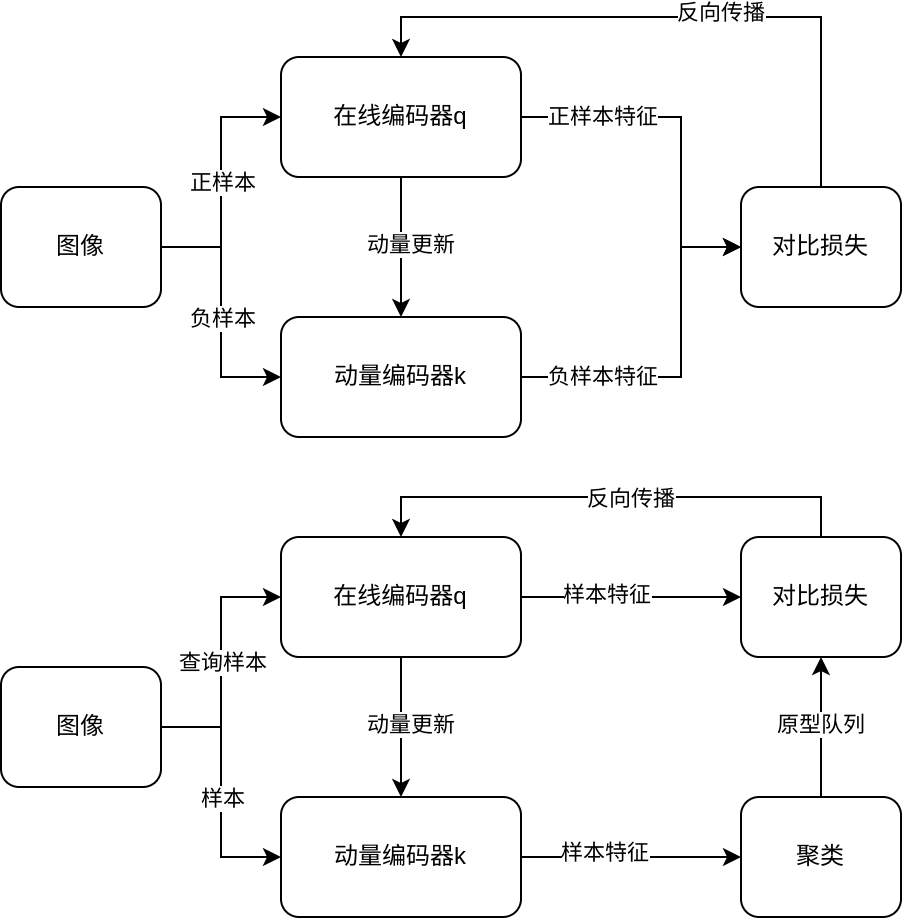
正如上图所示,两个对比任务共享所有的参数,但Info_NCE是直接计算两组编码器生成的特征的相似度,而Proto_NCE是计算样本特征和原型特征(特征簇的中心)之间的相似度。同时,在设置目的层面,两个任务之间也有差异。Info_NCE是实例驱动的,主要目的是实现对实例级物体的区分,而Proto_NCE则是对原型级物体进行区分,原型粒度越粗,二者区别越大。
在SimCLR和moco_v2中都有一个创新,即在编码器后不是简单地输出特征,而是加入了一个非线性的投影头,以提升训练效果。这个思路同样可以用到PCL中,如果我们需要在对聚类前动量编码器提取到的特征做一些修正,以让它们得到更有特点的原型,同时不影响原模型的特征提取能力的话,可以考虑在训练过程中增加针对任务的MLP,以非共享的参数促进不同任务的进行。
新设计:
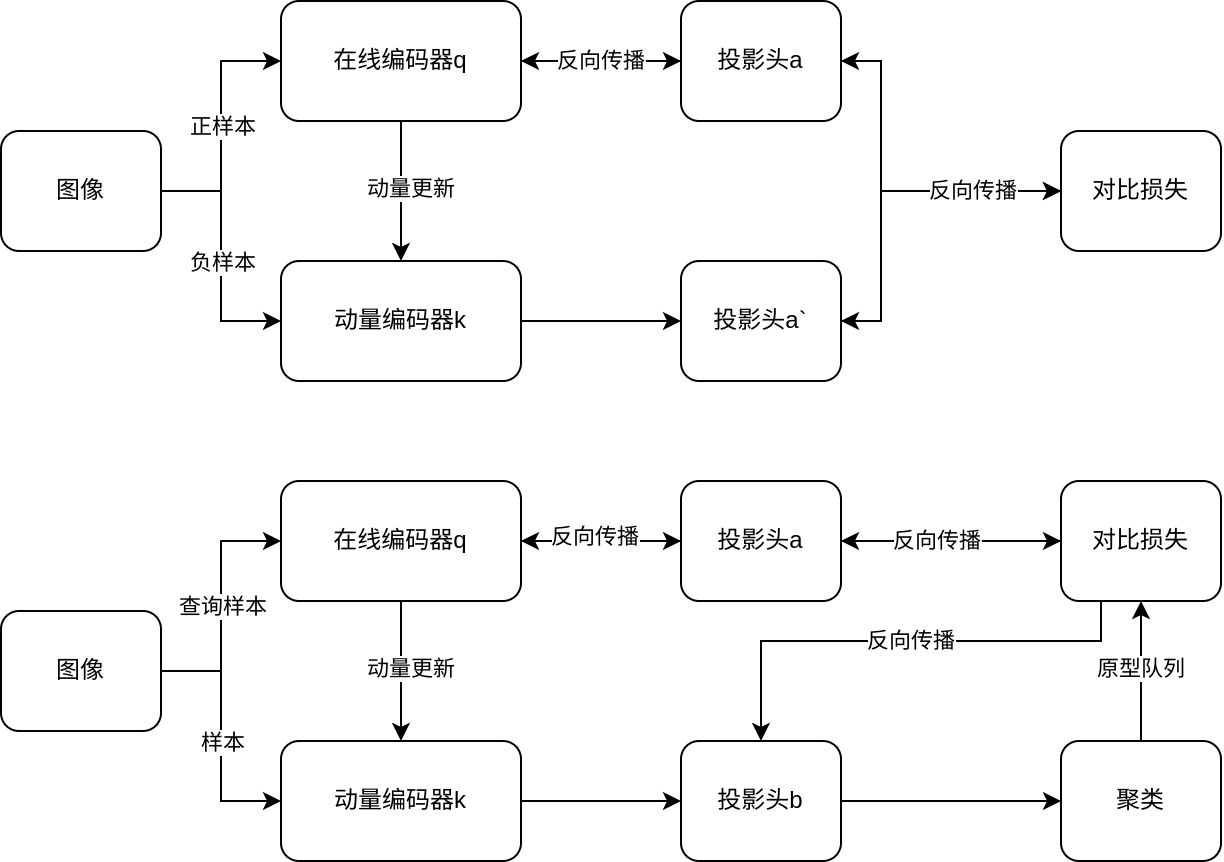
投影头a与a~均为一个128✖️128的全连接层与relu层的设计,投影头b在投影头a~的基础上额外增加了128✖️128的全连接层以及一个relu层,以提供对聚类任务的额外支持。
self.encoder_q.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc)
self.encoder_k.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc)
self.v = nn.Sequential(nn.Linear(128, 128), nn.ReLU())
...
if cluster_result is not None:
k = self.v(k)
效果:
训练速度降低,尤其是acc_inst在warmup阶段,可能与启用了颜色抖动的数据增强效果有关,正在排查。
可能的改进:
设置更多的warmup轮数,以在编码器有一定特征提取能力的基础上再进行投影头的训练,以避免训练无法找到方向。
2.改进训练细节
1.改用混合精度(autocast),增大batch_size
理由:
提升训练速度,部分论文指出较大的batch_size能提升训练效果和稳定loss(Training Deep Neural Networks with Large Mini-Batches、ResNet strikes back: An improved training procedure in timm)
问题:
计算特征出现内存不足报错。
修改:
修改compute_features,逐批计算特征并保存,每批次保存一个文件以避免内存溢出。
# 遍历数据加载器中的每个批次
for i, (images, index) in enumerate(tqdm(eval_loader)):
with torch.no_grad():
images = images.cuda(non_blocking=True)
feat = model(images, is_eval=True)
# 将每个批次的特征保存到文件中
feature_filename = os.path.join(feature_save_dir, f'batch_{i}_features.pt')
torch.save(feat.cpu(), feature_filename)
del feat # 计算完后释放内存
效果:
训练速度提升。
2.改用lamb优化器取代SGD
理由:
lamb优化器有着自动调整学习率的能力,对于更高的epoch效果更好
问题:
出现acc_inst异常升高甚至在较低epoch下达到100的情况,同时出现loss:nan。排查可能为梯度爆炸。
解决办法:
使用梯度裁剪的方式避免梯度爆炸:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
效果:
仍存在acc_inst异常升高和loss:nan的问题,暂时放弃lamb,改用SGD优化器+cos学习率下降模式,后续考虑lamb或者adam优化器。