4.7 KiB
自适应分层聚类的原型对比学习
1.相关研究与思路来源
主要参考了**《Prototypical Contrastive Learning of Unsupervised Representations》** (ICLR 2021),即原型对比学习的相关内容。该论文以“原型”驱动,缓解了以实例驱动的无监督学习中模型忽略了负样本对之间的语义相似性导致的性能下降的问题。但原型对比学习仍然存在缺陷,以“原型”为驱动的无监督学习也忽略了原型之间的语义相似性,同时聚类的不准确性可能导致不同粒度的原型进行对比,这导致学习不能很好得到准确的语义信息。
2.基本思路
通过多层的自适应聚类将数据的语义结构逐步编码到嵌入空间中,以缓解推离原型导致的语义信息损失。具体而言,通过建立一个自适应聚类数计算模块来控制每轮epoch下期望最大化算法(EM)中E步中寻找原型分布的聚类数目,由粗至细地逐步构建不同粒度的原型,并在同层级间构建对比损失,以推动模型得到的样本表征与其原型更为接近,与同层其他原型差异更大。同时通过调整密度的均衡性,保证上层聚类对下层聚类拥有更为直接的指导作用,加强不同层级之间的关联性。
3.实现细节
1.训练框架
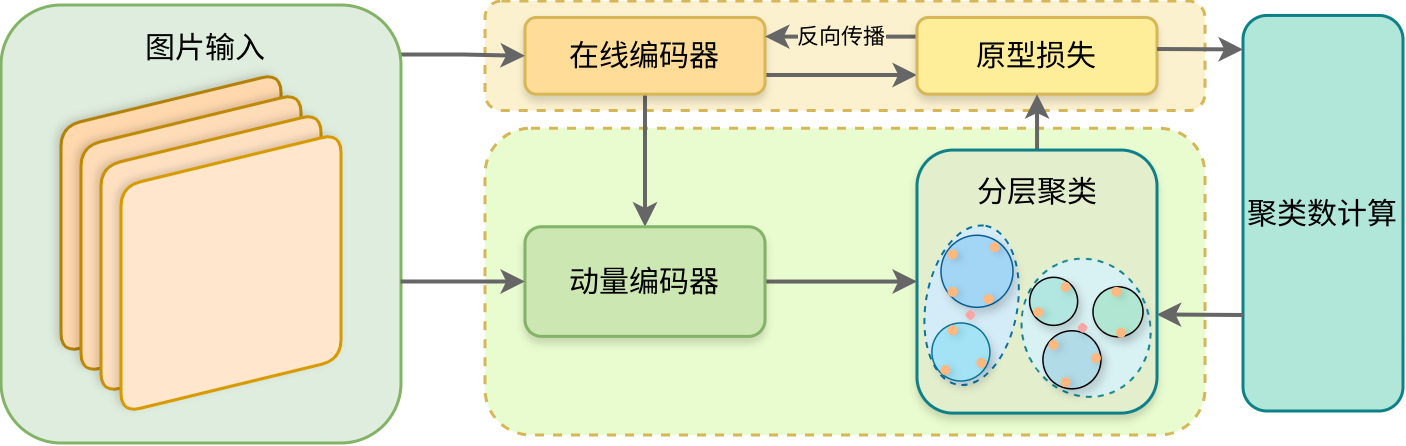
待补充
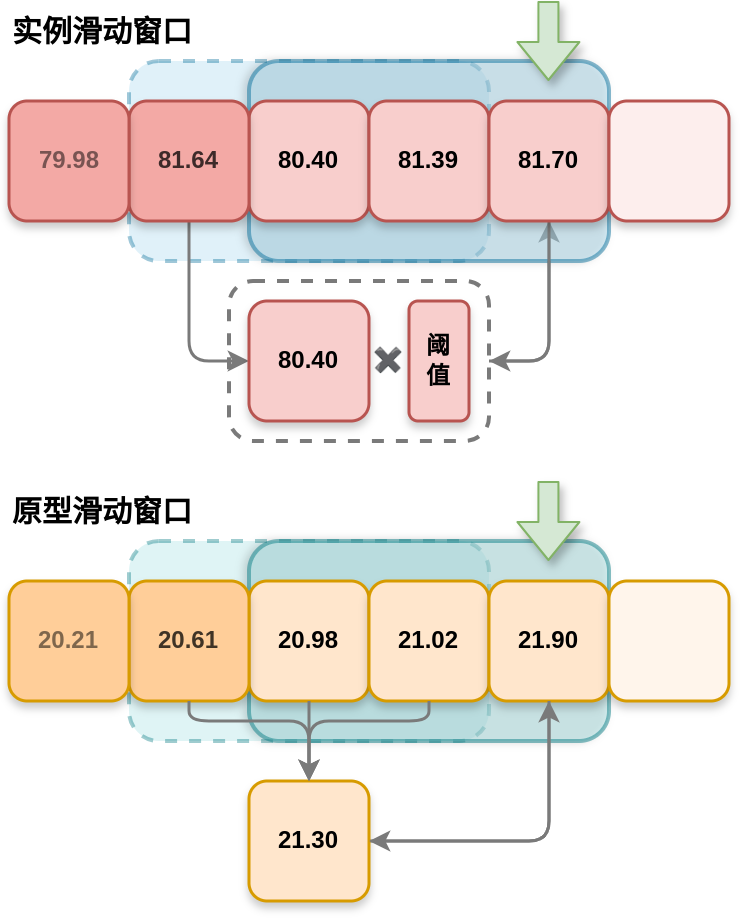
2.聚类数计算模块(滑动窗口模块)
4.试验记录/现象与改进
(1)PCL基础上增加层次聚类,完整训练1
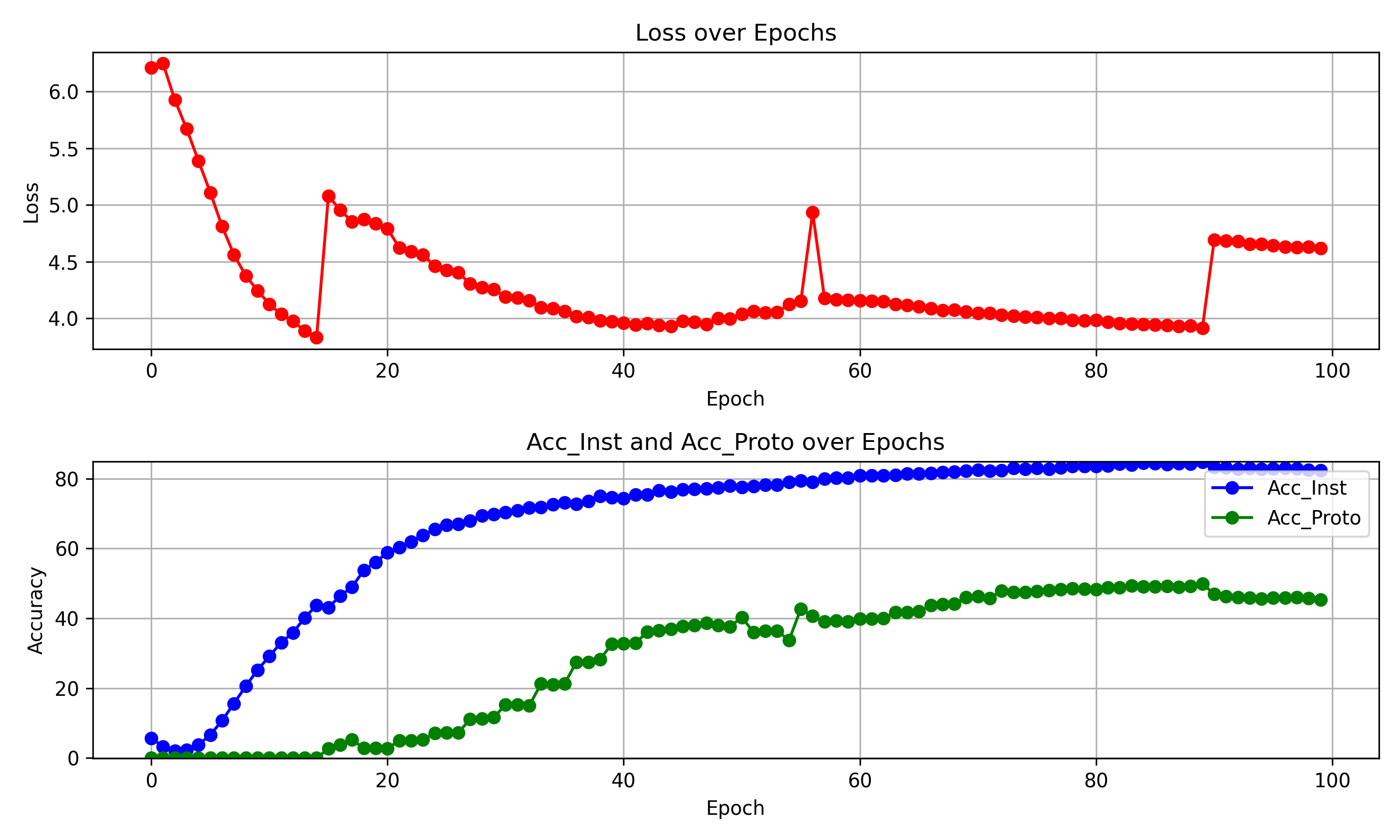
现象:
聚类数在114-172时,acc-proto的数值降低,此后每次聚类数量增加时,acc-proto的数值都会降低,随着同级反复聚类又逐渐回升。
思考:
可能是mini-imagenet的类别正好为100类,超过100类后原型构建更加不稳定。
改进方法:
在聚类数目较多的层数,可以考虑使用更多迭代次数帮助模型构建稳定的原型预测。
现象:
在acc-proto未提高甚至降低的时候,acc-inst依旧在逐步提高。
思考1:
虽然层次原型构建不稳定,但依旧能确定出该推远的原型和拉近的原型,由此帮助模型进步。
思考2:
证明在一定数量的聚类层次中,该层次区分原型的能力未发挥到极限,如果该层级区分原型的能力达到极限,应该两个acc在多个循环次数中不再有明显进步。
改进方法:
每层训练结束时取得平均acc-proto,若acc-proto的数值在多次训练后进步较小(提升率<1%),说明原型构建相对稳定。同时acc-inst也进步较小,说明在该原型聚类下已经很难获得进步,再考虑增加聚类数目。
(2)在(1)的基础上增加了增加聚类数目的判定方法,以两种acc提升与否作为聚类增加条件,完整训练2
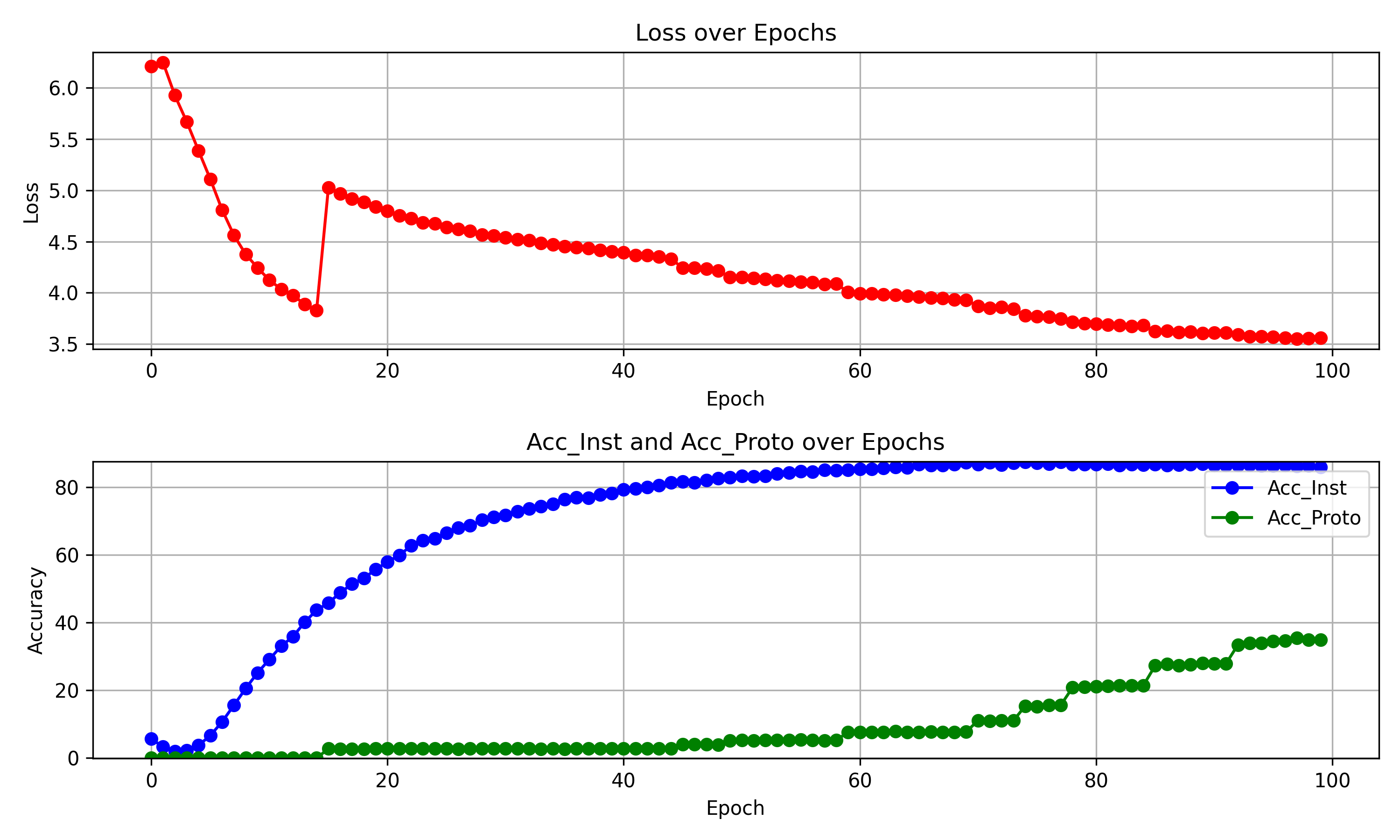
现象:
训练到55epoch时,acc_inst 平均为 84.7266, acc_proto 平均为 5.3151。可以看出虽然acc_proto很低,但acc_inst却远超同期水平。同时,稳定性很难突破限制,聚类数目长时间停留在2、4上,这与预期不符。
思考1:
怀疑在训练过程中,InfoNCE损失可能占据主导,但稳定的原型依旧为性能提升给予了很大帮助。
思考2:
如果长时间不增加聚类数目,很可能导致训练时过多以实例为驱动,影响最终性能。
思考3:
在训练的前期,由于模型不稳定,acc_inst的提升可能很明显;而到了训练后期,acc_inst的提升却较为困难,在某些epoch时还可能出现下降。
思考4:
acc_proto的值在增加聚类数目时会有较大的变化(一般而言是提升),而在固定聚类数目时变化较小。
改进方法:
1.采用滑动窗口法,如果当前epoch的acc没有超过窗口长度的前几次epoch的最高acc(或对比最高acc增幅小于一定比例),则增加聚类数增加。在每次聚类数增加后,清空窗口。
2.对acc_inst采用随epoch增加更为宽松的threshold,对acc_proto可不设threshold。
3.在acc_proto能提升时,acc_inst超过窗口长度不增加聚类数目。acc_proto超过窗口长度,acc_inst增加高于threshold,提升threshold数值,不增加聚类数目。acc_proto超过窗口长度,acc_inst增加低于threshold,threshold恢复原值,增加聚类数目。
下周工作:
1.分析训练过程中各损失的占比/主导作用以及变化趋势 2.对1中可能出现的问题进行改进 3.思考选择何种跨域数据集,并对代码进行可能的改动。