4.0 KiB
4.0 KiB
12月5日科研工作进展
目前进度
1.继续进行超参数调整
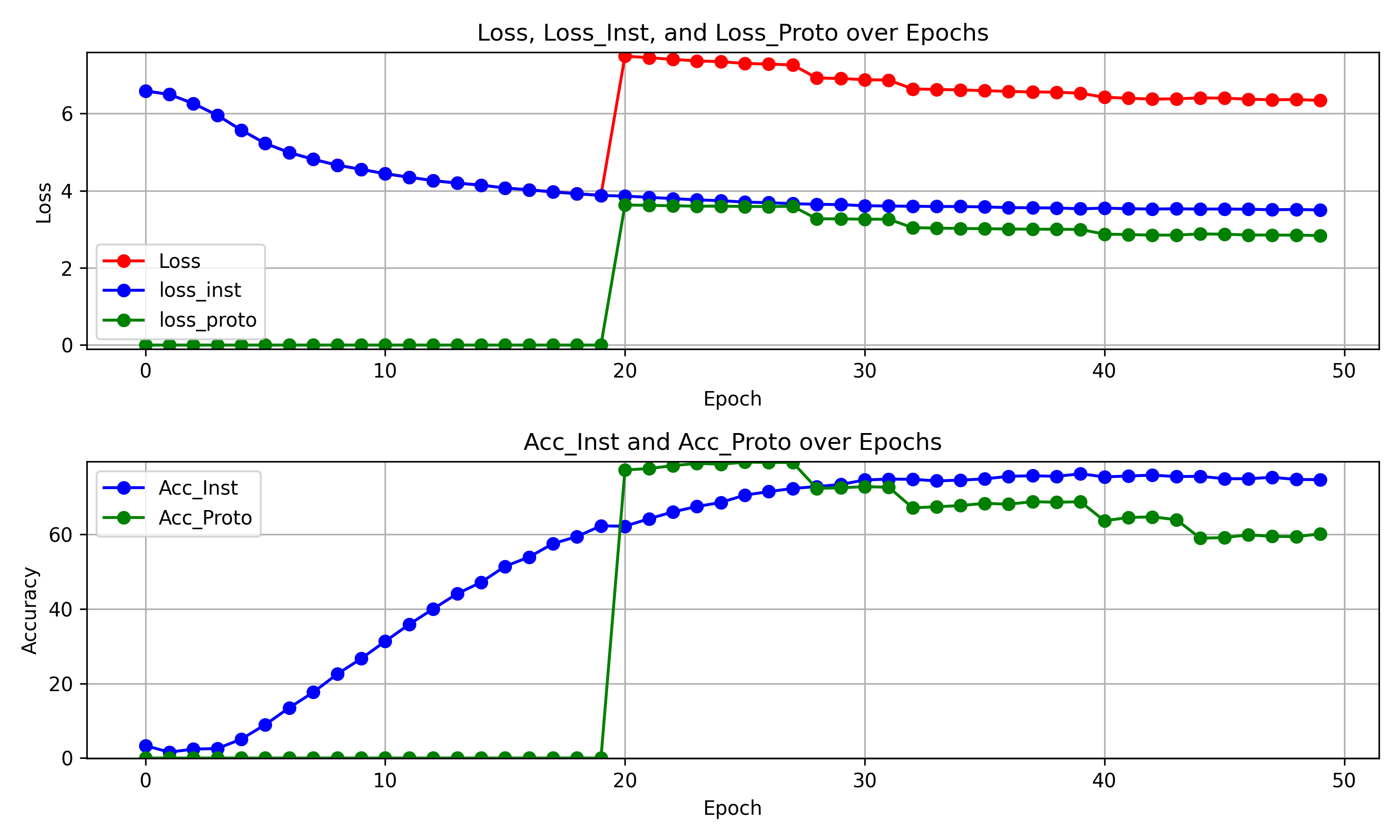
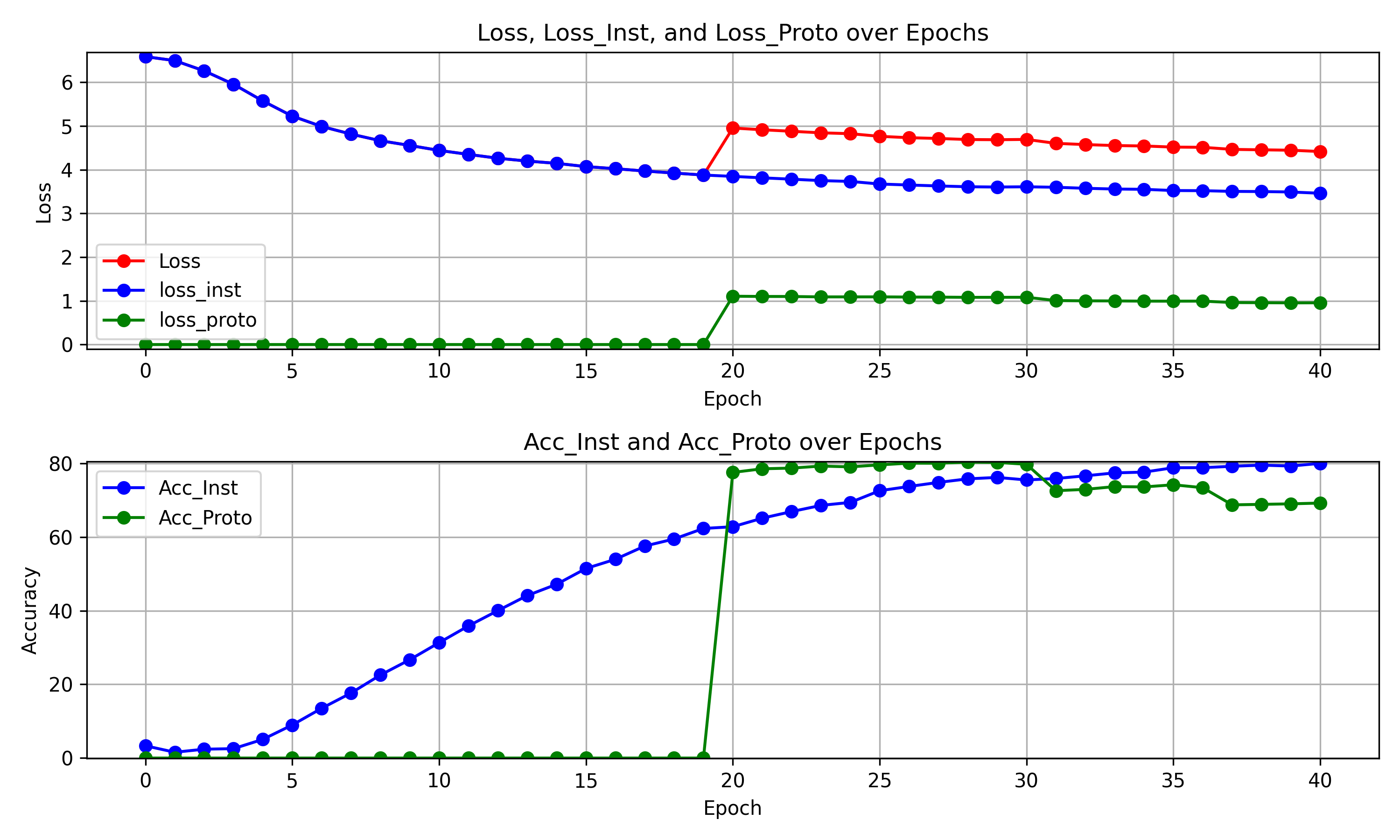
超参数:
# 批次大小
parser.add_argument('--batch-size', default=64, type=int)
# 学习率
parser.add_argument('--lr', default=0.03, type=float)
# 聚类数量
parser.add_argument('--num-cluster', default='2,5,10,20,33,50,100,200,400,800,1600,2400,3200', type=str)
# 负样本队列大小
parser.add_argument('--pcl-r', default=1024, type=int)
# MoCo动量
parser.add_argument('--moco-m', default=0.999, type=float, )
# softmax温度
parser.add_argument('--temperature', default=0.2, type=float)
目前问题:
(1)存在过拟合的情况
(2)存在原型聚类损失不能很好引导两个精度的提升的问题
2.使用了软化标签的方式解决低聚类问题中的不确定影响
调用了nn.CrossEntropyLoss中的label_smoothing功能缓解硬标签对初期模型的破坏,目前设定上限为0.2
def cac_smoothing_factor(cluster_result, args):
# 获取当前聚类数
cluster = int(cluster_result['centroids'][-1].shape[0])
# 计算平滑因子,使得聚类数越少,平滑因子越大,最大为0.2
smoothing_factor = min(0.2, ((args.max_cluster - cluster) / args.max_cluster) ** 0.5 * 0.2)
return smoothing_factor
3.改用了自行设计聚类数组而非直接翻倍的方式决定聚类数目
根据之前的实验,聚类数在100左右时对训练提升最大,这是因为使用的mini-imagenet数据集拥有100个类别的原因。使用直接翻倍的情况可能会导致跳过n倍数类别或1/n类别的聚类数,导致计算损失时存在误差。
parser.add_argument('--num-cluster', default='2,5,10,20,33,50,100,200,400,800,1600,2400,3200', type=str)
# 改变聚类数逻辑
if should_change:
# 取 num_clusters 的最后一个数字,与 all_clusters 比较
last_cluster = num_clusters[-1]
if last_cluster in all_clusters:
index = all_clusters.index(last_cluster)
if index + 1 < len(all_clusters): # 确保不会超出范围
next_cluster = all_clusters[index + 1]
# 更新 num_clusters:移除第一个,添加新数字到末尾
num_clusters.pop(0)
num_clusters.append(next_cluster)
print(f"Epoch {epoch}: 聚类数改变.")
print(f"num_clusters 更新为: {num_clusters}")
else:
print("all_clusters 已用完,无法改变.")
else:
print("当前 num_clusters 的最后一个数字未在 all_clusters 中找到")
sliding_window.reset(epoch) # 重置窗口并更新init_threshold
elif should_change_threshold:
print(f"Epoch {epoch}: 增加inst阈值")
else:
print("滑动窗口未达到条件,不改变聚类数.")
4.增加了cos学习率衰减以控制更新以及防止过拟合
def adjust_learning_rate(optimizer, epoch, args):
"""Decay the learning rate based on schedule"""
lr = args.lr
if args.cos: # cosine lr schedule
lr *= 0.5 * (1. + math.cos(math.pi * epoch / args.epochs))
else: # stepwise lr schedule
for milestone in args.schedule:
lr *= 0.1 if epoch >= milestone else 1.
for param_group in optimizer.param_groups:
param_group['lr'] = lr
5.采用凝聚型层次聚类作为一次聚类任务的方式
避免出现样本a在细聚类时属于小原型1.1,小原型1.1属于大原型1中,但样本a却在粗聚类时被分配到大原型2中的问题,提升聚类的可靠性。
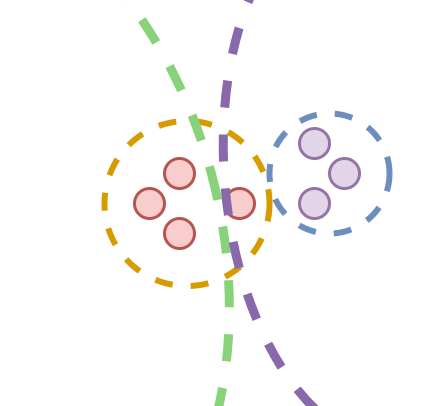
6.改用聚类数从高到低的方式引导训练流程
在模型刚开始训练时,较粗的聚类可能导致边缘样本的错误分配,导致错误的累计。故引导聚类的方法从细到粗更可靠,最近邻和过度聚类通常更能被接受的;同时,凝聚聚类是一个循环过程,可以自然地在循环框架中进行解释;随着学习到更好的表示,这些聚类可以被合并。