Compare commits
No commits in common. "master" and "main" have entirely different histories.
|
|
@ -1,165 +0,0 @@
|
|||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
pip-wheel-metadata/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# Profiling
|
||||
*.pclprof
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
.idea
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# VSCode project settings
|
||||
.vscode/
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
mkdocs_github_authors.yaml
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# datasets and projects
|
||||
datasets/
|
||||
runs/
|
||||
wandb/
|
||||
tests/
|
||||
.DS_Store
|
||||
|
||||
# Neural Network weights -----------------------------------------------------------------------------------------------
|
||||
weights/
|
||||
*.weights
|
||||
*.pt
|
||||
*.pb
|
||||
*.onnx
|
||||
*.engine
|
||||
*.mlmodel
|
||||
*.mlpackage
|
||||
*.torchscript
|
||||
*.tflite
|
||||
*.h5
|
||||
*_saved_model/
|
||||
*_web_model/
|
||||
*_openvino_model/
|
||||
*_paddle_model/
|
||||
pnnx*
|
||||
|
||||
# Autogenerated files for tests
|
||||
/ultralytics/assets/
|
||||
|
|
@ -1,89 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Pre-commit hooks. For more information see https://github.com/pre-commit/pre-commit-hooks/blob/main/README.md
|
||||
# Optionally remove from local hooks with 'rm .git/hooks/pre-commit'
|
||||
|
||||
# Define bot property if installed via https://github.com/marketplace/pre-commit-ci
|
||||
ci:
|
||||
autofix_prs: true
|
||||
autoupdate_commit_msg: '[pre-commit.ci] pre-commit suggestions'
|
||||
autoupdate_schedule: monthly
|
||||
submodules: true
|
||||
|
||||
# Exclude directories (optional)
|
||||
# exclude: 'docs/'
|
||||
|
||||
# Define repos to run
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v4.5.0
|
||||
hooks:
|
||||
- id: end-of-file-fixer
|
||||
- id: trailing-whitespace
|
||||
- id: check-case-conflict
|
||||
# - id: check-yaml
|
||||
- id: check-docstring-first
|
||||
- id: double-quote-string-fixer
|
||||
- id: detect-private-key
|
||||
|
||||
- repo: https://github.com/asottile/pyupgrade
|
||||
rev: v3.15.0
|
||||
hooks:
|
||||
- id: pyupgrade
|
||||
name: Upgrade code
|
||||
|
||||
- repo: https://github.com/PyCQA/isort
|
||||
rev: 5.12.0
|
||||
hooks:
|
||||
- id: isort
|
||||
name: Sort imports
|
||||
|
||||
- repo: https://github.com/google/yapf
|
||||
rev: v0.40.2
|
||||
hooks:
|
||||
- id: yapf
|
||||
name: YAPF formatting
|
||||
|
||||
- repo: https://github.com/executablebooks/mdformat
|
||||
rev: 0.7.17
|
||||
hooks:
|
||||
- id: mdformat
|
||||
name: MD formatting
|
||||
additional_dependencies:
|
||||
- mdformat-gfm
|
||||
- mdformat-black
|
||||
exclude: 'docs/.*\.md'
|
||||
# exclude: "README.md|README.zh-CN.md|CONTRIBUTING.md"
|
||||
|
||||
- repo: https://github.com/PyCQA/flake8
|
||||
rev: 6.1.0
|
||||
hooks:
|
||||
- id: flake8
|
||||
name: PEP8
|
||||
|
||||
- repo: https://github.com/codespell-project/codespell
|
||||
rev: v2.2.6
|
||||
hooks:
|
||||
- id: codespell
|
||||
exclude: 'docs/de|docs/fr|docs/pt|docs/es|docs/mkdocs_de.yml'
|
||||
args:
|
||||
- --ignore-words-list=crate,nd,strack,dota,ane,segway,fo,gool,winn
|
||||
|
||||
- repo: https://github.com/PyCQA/docformatter
|
||||
rev: v1.7.5
|
||||
hooks:
|
||||
- id: docformatter
|
||||
|
||||
# - repo: https://github.com/asottile/yesqa
|
||||
# rev: v1.4.0
|
||||
# hooks:
|
||||
# - id: yesqa
|
||||
|
||||
# - repo: https://github.com/asottile/dead
|
||||
# rev: v1.5.0
|
||||
# hooks:
|
||||
# - id: dead
|
||||
|
||||
# - repo: https://github.com/ultralytics/pre-commit
|
||||
# rev: bd60a414f80a53fb8f593d3bfed4701fc47e4b23
|
||||
# hooks:
|
||||
# - id: capitalize-comments
|
||||
20
CITATION.cff
20
CITATION.cff
|
|
@ -1,20 +0,0 @@
|
|||
cff-version: 1.2.0
|
||||
preferred-citation:
|
||||
type: software
|
||||
message: If you use this software, please cite it as below.
|
||||
authors:
|
||||
- family-names: Jocher
|
||||
given-names: Glenn
|
||||
orcid: "https://orcid.org/0000-0001-5950-6979"
|
||||
- family-names: Chaurasia
|
||||
given-names: Ayush
|
||||
orcid: "https://orcid.org/0000-0002-7603-6750"
|
||||
- family-names: Qiu
|
||||
given-names: Jing
|
||||
orcid: "https://orcid.org/0000-0003-3783-7069"
|
||||
title: "YOLO by Ultralytics"
|
||||
version: 8.0.0
|
||||
# doi: 10.5281/zenodo.3908559 # TODO
|
||||
date-released: 2023-1-10
|
||||
license: AGPL-3.0
|
||||
url: "https://github.com/ultralytics/ultralytics"
|
||||
|
|
@ -1,8 +0,0 @@
|
|||
include *.md
|
||||
include requirements.txt
|
||||
include LICENSE
|
||||
include setup.py
|
||||
include ultralytics/assets/bus.jpg
|
||||
include ultralytics/assets/zidane.jpg
|
||||
include tests/*.py
|
||||
recursive-include ultralytics *.yaml
|
||||
76
README.md
76
README.md
|
|
@ -1,68 +1,8 @@
|
|||
# Sleeping-post-detection
|
||||
|
||||
# 睡岗检测
|
||||
|
||||
## 场景
|
||||
|
||||
本项目适用于一些需要持续工作的岗位或者某些重要的岗位,防止工作人员出现意外
|
||||
|
||||
## 介绍
|
||||
|
||||
本项目是基于yolov8模型制作的睡岗检测
|
||||
|
||||
## 代码思路
|
||||
|
||||
1.为人头描定数据框,并且设置中心点
|
||||
|
||||
2.只要中心点在一定时间内,一定范围内运动,或者保持不动,便判定为睡岗
|
||||
|
||||
|
||||
## 使用说明:
|
||||
|
||||
### 注意:在使用前要确认环境已经搭配好了
|
||||
|
||||
### 1.需要安装依赖(我一般使用conda安装)
|
||||
|
||||
`conda install --yes --file requirements.txt`
|
||||
|
||||
### 2.需要安装opencv库
|
||||
|
||||
`conda install -c conda-forge opencv`
|
||||
|
||||
### 3.大部分需要安装的库都可以在pycharm中直接下载(如有遗漏)
|
||||
|
||||
### 4.指定训练好的模型进行测试
|
||||
|
||||
`model_path = r'\detect\train\weights\best.pt'` # 加载训练好的模型
|
||||
|
||||
`model = YOLO(model_path) ` # model是加载后的训练模型实例
|
||||
|
||||
### 5.进行静态检测的时候我们要注意我们当前代码仅支持 .png, .jpg, .jpeg, .bmp 等常见图像格式
|
||||
|
||||
### 6.phototest文件不仅支持单张图片检测并且支持批量检测(或文件夹检测),只需要按照下面代码指定文件夹即可
|
||||
|
||||
`infer_and_draw(r'C:\path\to\your\image\folder', r'C:\ultralytics\output')`
|
||||
|
||||
### 7.以下是对动态检测的一些代码讲解
|
||||
|
||||
#### 7.1 视频输入:
|
||||
|
||||
使用 cv2.VideoCapture() 打开视频文件或 RTSP 流,同时支持本地视频文件和网络串流
|
||||
|
||||
#### 7.2 YOLO 检测:
|
||||
|
||||
每隔 `detection_interval = 10` 帧,模型会对帧进行目标检测,返回检测到的边界框(boxes)和置信度(confidences)。
|
||||
检测的边界框经过过滤和合并后保存,并且通过 cv2.TrackerKCF_create() 创建跟踪器来跟踪每个目标。
|
||||
|
||||
#### 7.3 状态检测:
|
||||
|
||||
通过历史跟踪中心位置(center_history),每个物体的中心点会被记录到一个 deque(长度为 tracking_window_size = 250)。如果该物体的中心点在一段时间内变化很小,程序会在图像上显示“睡眠”(SLEEP),表明物体处于静止状态。
|
||||
通过计算中心点的距离变化(稳定状态的判断),判断物体是否保持静止。
|
||||
|
||||
### 运行方法(以下文件均在Sleeping-post-detection-first-edition目录下)
|
||||
|
||||
phototest文件夹专门负责检测图片
|
||||
|
||||
fps01 ~ fps04 文件夹代表了测试视频和实时检测时所犯的错误和更正过程,fps04为最终优化版本
|
||||
|
||||
|
||||
# Sleeping-post-detection-first-edition
|
||||
|
||||
Sleeping-post-detection
|
||||
睡岗检测
|
||||
主要场景
|
||||
睡岗检测一般应用于需要连续值守的场所
|
||||
介绍
|
||||
本项目主要是使用yolov8来完成人头检测的
|
||||
|
|
|
|||
17
ceshi.py
17
ceshi.py
|
|
@ -1,17 +0,0 @@
|
|||
#测试训练集
|
||||
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 创建 YOLOv8 模型实例,选择适合的配置文件
|
||||
model = YOLO('yolov8n.yaml') # YOLOv8 Nano 配置文件(这个是从官网上下载的预训练模型)
|
||||
|
||||
# 配置训练参数
|
||||
model.train(
|
||||
data='data.yaml', # 数据配置文件
|
||||
epochs=150, # 训练轮数
|
||||
batch=8, # 批量大小(适合 CPU 计算)
|
||||
imgsz=320, # 图像尺寸(较小尺寸适合 CPU)
|
||||
device='cpu' # 训练设备设置为 CPU(本人用的是cpu)
|
||||
)
|
||||
|
||||
|
||||
|
|
@ -1,8 +0,0 @@
|
|||
|
||||
train: # 训练集路径
|
||||
val: # 验证集路径(如果训练集和验证集相同的话,这样写是可以的)
|
||||
|
||||
|
||||
nc: # 类别数
|
||||
|
||||
names: ['xxxx',‘xxxx’] # 类别名称
|
||||
|
|
@ -1,82 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds ultralytics/ultralytics:latest image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference
|
||||
|
||||
# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch or nvcr.io/nvidia/pytorch:23.03-py3
|
||||
FROM pytorch/pytorch:2.1.0-cuda12.1-cudnn8-runtime
|
||||
RUN pip install --no-cache nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
||||
RUN apt update \
|
||||
&& apt install --no-install-recommends -y gcc git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
||||
|
||||
# Security updates
|
||||
# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796
|
||||
RUN apt upgrade --no-install-recommends -y openssl tar
|
||||
|
||||
# Create working directory
|
||||
WORKDIR /usr/src/ultralytics
|
||||
|
||||
# Copy contents
|
||||
# COPY . /usr/src/ultralytics # git permission issues inside container
|
||||
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
||||
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
|
||||
|
||||
# Install pip packages
|
||||
RUN python3 -m pip install --upgrade pip wheel
|
||||
RUN pip install --no-cache -e ".[export]" albumentations comet pycocotools pytest-cov
|
||||
|
||||
# Run exports to AutoInstall packages
|
||||
RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
|
||||
RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
|
||||
# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
|
||||
RUN pip install --no-cache paddlepaddle==2.4.2 x2paddle
|
||||
# Fix error: `np.bool` was a deprecated alias for the builtin `bool` segmentation error in Tests
|
||||
RUN pip install --no-cache numpy==1.23.5
|
||||
# Remove exported models
|
||||
RUN rm -rf tmp
|
||||
|
||||
# Set environment variables
|
||||
ENV OMP_NUM_THREADS=1
|
||||
# Avoid DDP error "MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library" https://github.com/pytorch/pytorch/issues/37377
|
||||
ENV MKL_THREADING_LAYER=GNU
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest && sudo docker build -f docker/Dockerfile -t $t . && sudo docker push $t
|
||||
|
||||
# Pull and Run with access to all GPUs
|
||||
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
|
||||
|
||||
# Pull and Run with access to GPUs 2 and 3 (inside container CUDA devices will appear as 0 and 1)
|
||||
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
|
||||
|
||||
# Pull and Run with local directory access
|
||||
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/datasets:/usr/src/datasets $t
|
||||
|
||||
# Kill all
|
||||
# sudo docker kill $(sudo docker ps -q)
|
||||
|
||||
# Kill all image-based
|
||||
# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/ultralytics:latest)
|
||||
|
||||
# DockerHub tag update
|
||||
# t=ultralytics/ultralytics:latest tnew=ultralytics/ultralytics:v6.2 && sudo docker pull $t && sudo docker tag $t $tnew && sudo docker push $tnew
|
||||
|
||||
# Clean up
|
||||
# sudo docker system prune -a --volumes
|
||||
|
||||
# Update Ubuntu drivers
|
||||
# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
|
||||
|
||||
# DDP test
|
||||
# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
|
||||
|
||||
# GCP VM from Image
|
||||
# docker.io/ultralytics/ultralytics:latest
|
||||
|
|
@ -1,44 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds ultralytics/ultralytics:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Image is aarch64-compatible for Apple M1 and other ARM architectures i.e. Jetson Nano and Raspberry Pi
|
||||
|
||||
# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
|
||||
FROM arm64v8/ubuntu:22.04
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
||||
RUN apt update \
|
||||
&& apt install --no-install-recommends -y python3-pip git zip curl htop gcc libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
||||
|
||||
# Create working directory
|
||||
WORKDIR /usr/src/ultralytics
|
||||
|
||||
# Copy contents
|
||||
# COPY . /usr/src/ultralytics # git permission issues inside container
|
||||
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
||||
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
|
||||
|
||||
# Install pip packages
|
||||
RUN python3 -m pip install --upgrade pip wheel
|
||||
RUN pip install --no-cache -e .
|
||||
|
||||
# Creates a symbolic link to make 'python' point to 'python3'
|
||||
RUN ln -sf /usr/bin/python3 /usr/bin/python
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest-arm64 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-arm64 -t $t . && sudo docker push $t
|
||||
|
||||
# Run
|
||||
# t=ultralytics/ultralytics:latest-arm64 && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run
|
||||
# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run with local volume mounted
|
||||
# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
||||
|
|
@ -1,38 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds ultralytics/ultralytics:latest-conda image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Image is optimized for Ultralytics Anaconda (https://anaconda.org/conda-forge/ultralytics) installation and usage
|
||||
|
||||
# Start FROM miniconda3 image https://hub.docker.com/r/continuumio/miniconda3
|
||||
FROM continuumio/miniconda3:latest
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
RUN apt update \
|
||||
&& apt install --no-install-recommends -y libgl1
|
||||
|
||||
# Copy contents
|
||||
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt .
|
||||
|
||||
# Install conda packages
|
||||
# mkl required to fix 'OSError: libmkl_intel_lp64.so.2: cannot open shared object file: No such file or directory'
|
||||
RUN conda config --set solver libmamba && \
|
||||
conda install pytorch torchvision pytorch-cuda=11.8 -c pytorch -c nvidia && \
|
||||
conda install -c conda-forge ultralytics mkl
|
||||
# conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics mkl
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest-conda && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
|
||||
|
||||
# Run
|
||||
# t=ultralytics/ultralytics:latest-conda && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run
|
||||
# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run with local volume mounted
|
||||
# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
||||
|
|
@ -1,55 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
|
||||
|
||||
# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
|
||||
FROM ubuntu:mantic-20231011
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
||||
RUN apt update \
|
||||
&& apt install --no-install-recommends -y python3-pip git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
||||
|
||||
# Create working directory
|
||||
WORKDIR /usr/src/ultralytics
|
||||
|
||||
# Copy contents
|
||||
# COPY . /usr/src/ultralytics # git permission issues inside container
|
||||
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
||||
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
|
||||
|
||||
# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
|
||||
RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
|
||||
|
||||
# Install pip packages
|
||||
RUN python3 -m pip install --upgrade pip wheel
|
||||
RUN pip install --no-cache -e ".[export]" --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
|
||||
# Run exports to AutoInstall packages
|
||||
RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
|
||||
RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
|
||||
# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
|
||||
# RUN pip install --no-cache paddlepaddle==2.4.2 x2paddle
|
||||
# Remove exported models
|
||||
RUN rm -rf tmp
|
||||
|
||||
# Creates a symbolic link to make 'python' point to 'python3'
|
||||
RUN ln -sf /usr/bin/python3 /usr/bin/python
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest-cpu && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
|
||||
|
||||
# Run
|
||||
# t=ultralytics/ultralytics:latest-cpu && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run
|
||||
# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run with local volume mounted
|
||||
# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
||||
|
|
@ -1,48 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds ultralytics/ultralytics:jetson image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Supports JetPack for YOLOv8 on Jetson Nano, TX1/TX2, Xavier NX, AGX Xavier, AGX Orin, and Orin NX
|
||||
|
||||
# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch
|
||||
FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
||||
RUN apt update \
|
||||
&& apt install --no-install-recommends -y gcc git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
||||
|
||||
# Create working directory
|
||||
WORKDIR /usr/src/ultralytics
|
||||
|
||||
# Copy contents
|
||||
# COPY . /usr/src/ultralytics # git permission issues inside container
|
||||
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
||||
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
|
||||
|
||||
# Remove opencv-python from requirements.txt as it conflicts with opencv-python installed in base image
|
||||
RUN grep -v '^opencv-python' requirements.txt > tmp.txt && mv tmp.txt requirements.txt
|
||||
|
||||
# Install pip packages manually for TensorRT compatibility https://github.com/NVIDIA/TensorRT/issues/2567
|
||||
RUN python3 -m pip install --upgrade pip wheel
|
||||
RUN pip install --no-cache tqdm matplotlib pyyaml psutil pandas onnx "numpy==1.23"
|
||||
RUN pip install --no-cache -e .
|
||||
|
||||
# Set environment variables
|
||||
ENV OMP_NUM_THREADS=1
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest-jetson && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson -t $t . && sudo docker push $t
|
||||
|
||||
# Run
|
||||
# t=ultralytics/ultralytics:latest-jetson && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run
|
||||
# t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run with NVIDIA runtime
|
||||
# t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
|
||||
|
|
@ -1,52 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
|
||||
|
||||
# Use the official Python 3.10 slim-bookworm as base image
|
||||
FROM python:3.10-slim-bookworm
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
||||
RUN apt update \
|
||||
&& apt install --no-install-recommends -y python3-pip git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
||||
|
||||
# Create working directory
|
||||
WORKDIR /usr/src/ultralytics
|
||||
|
||||
# Copy contents
|
||||
# COPY . /usr/src/ultralytics # git permission issues inside container
|
||||
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
||||
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
|
||||
|
||||
# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
|
||||
# RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
|
||||
|
||||
# Install pip packages
|
||||
RUN python3 -m pip install --upgrade pip wheel
|
||||
RUN pip install --no-cache -e ".[export]" --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
|
||||
# Run exports to AutoInstall packages
|
||||
RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
|
||||
RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
|
||||
# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
|
||||
RUN pip install --no-cache paddlepaddle==2.4.2 x2paddle
|
||||
# Remove exported models
|
||||
RUN rm -rf tmp
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest-python && sudo docker build -f docker/Dockerfile-python -t $t . && sudo docker push $t
|
||||
|
||||
# Run
|
||||
# t=ultralytics/ultralytics:latest-python && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run
|
||||
# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
||||
|
||||
# Pull and Run with local volume mounted
|
||||
# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
||||
|
|
@ -1,38 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
# Builds GitHub actions CI runner image for deployment to DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
||||
# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference tests
|
||||
|
||||
# Start FROM Ultralytics GPU image
|
||||
FROM ultralytics/ultralytics:latest
|
||||
|
||||
# Set the working directory
|
||||
WORKDIR /actions-runner
|
||||
|
||||
# Download and unpack the latest runner from https://github.com/actions/runner
|
||||
RUN FILENAME=actions-runner-linux-x64-2.309.0.tar.gz && \
|
||||
curl -o $FILENAME -L https://github.com/actions/runner/releases/download/v2.309.0/$FILENAME && \
|
||||
tar xzf $FILENAME && \
|
||||
rm $FILENAME
|
||||
|
||||
# Install runner dependencies
|
||||
ENV RUNNER_ALLOW_RUNASROOT=1
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
RUN ./bin/installdependencies.sh && \
|
||||
apt-get -y install libicu-dev
|
||||
|
||||
# Inline ENTRYPOINT command to configure and start runner with default TOKEN and NAME
|
||||
ENTRYPOINT sh -c './config.sh --url https://github.com/ultralytics/ultralytics \
|
||||
--token ${GITHUB_RUNNER_TOKEN:-TOKEN} \
|
||||
--name ${GITHUB_RUNNER_NAME:-NAME} \
|
||||
--labels gpu-latest \
|
||||
--replace && \
|
||||
./run.sh'
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
# Build and Push
|
||||
# t=ultralytics/ultralytics:latest-runner && sudo docker build -f docker/Dockerfile-runner -t $t . && sudo docker push $t
|
||||
|
||||
# Pull and Run in detached mode with access to GPUs 0 and 1
|
||||
# t=ultralytics/ultralytics:latest-runner && sudo docker run -d -e GITHUB_RUNNER_TOKEN=TOKEN -e GITHUB_RUNNER_NAME=NAME --ipc=host --gpus '"device=0,1"' $t
|
||||
102
docs/README.md
102
docs/README.md
|
|
@ -1,102 +0,0 @@
|
|||
# Ultralytics Docs
|
||||
|
||||
Ultralytics Docs are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com).
|
||||
|
||||
[](https://github.com/ultralytics/docs/actions/workflows/pages/pages-build-deployment) [](https://github.com/ultralytics/docs/actions/workflows/links.yml)
|
||||
|
||||
### Install Ultralytics package
|
||||
|
||||
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
||||
|
||||
To install the ultralytics package in developer mode, you will need to have Git and Python 3 installed on your system. Then, follow these steps:
|
||||
|
||||
1. Clone the ultralytics repository to your local machine using Git:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/ultralytics/ultralytics.git
|
||||
```
|
||||
|
||||
2. Navigate to the root directory of the repository:
|
||||
|
||||
```bash
|
||||
cd ultralytics
|
||||
```
|
||||
|
||||
3. Install the package in developer mode using pip:
|
||||
|
||||
```bash
|
||||
pip install -e '.[dev]'
|
||||
```
|
||||
|
||||
This will install the ultralytics package and its dependencies in developer mode, allowing you to make changes to the package code and have them reflected immediately in your Python environment.
|
||||
|
||||
Note that you may need to use the pip3 command instead of pip if you have multiple versions of Python installed on your system.
|
||||
|
||||
### Building and Serving Locally
|
||||
|
||||
The `mkdocs serve` command is used to build and serve a local version of the MkDocs documentation site. It is typically used during the development and testing phase of a documentation project.
|
||||
|
||||
```bash
|
||||
mkdocs serve
|
||||
```
|
||||
|
||||
Here is a breakdown of what this command does:
|
||||
|
||||
- `mkdocs`: This is the command-line interface (CLI) for the MkDocs static site generator. It is used to build and serve MkDocs sites.
|
||||
- `serve`: This is a subcommand of the `mkdocs` CLI that tells it to build and serve the documentation site locally.
|
||||
- `-a`: This flag specifies the hostname and port number to bind the server to. The default value is `localhost:8000`.
|
||||
- `-t`: This flag specifies the theme to use for the documentation site. The default value is `mkdocs`.
|
||||
- `-s`: This flag tells the `serve` command to serve the site in silent mode, which means it will not display any log messages or progress updates. When you run the `mkdocs serve` command, it will build the documentation site using the files in the `docs/` directory and serve it at the specified hostname and port number. You can then view the site by going to the URL in your web browser.
|
||||
|
||||
While the site is being served, you can make changes to the documentation files and see them reflected in the live site immediately. This is useful for testing and debugging your documentation before deploying it to a live server.
|
||||
|
||||
To stop the serve command and terminate the local server, you can use the `CTRL+C` keyboard shortcut.
|
||||
|
||||
### Building and Serving Multi-Language
|
||||
|
||||
For multi-language MkDocs sites use the following additional steps:
|
||||
|
||||
1. Add all new language *.md files to git commit: `git add docs/**/*.md -f`
|
||||
2. Build all languages to the `/site` directory. Verify that the top-level `/site` directory contains `CNAME`, `robots.txt` and `sitemap.xml` files, if applicable.
|
||||
|
||||
```bash
|
||||
# Remove existing /site directory
|
||||
rm -rf site
|
||||
|
||||
# Loop through all *.yml files in the docs directory
|
||||
mkdocs build -f docs/mkdocs.yml
|
||||
for file in docs/mkdocs_*.yml; do
|
||||
echo "Building MkDocs site with configuration file: $file"
|
||||
mkdocs build -f "$file"
|
||||
done
|
||||
```
|
||||
|
||||
3. Preview in web browser with:
|
||||
|
||||
```bash
|
||||
cd site
|
||||
python -m http.server
|
||||
open http://localhost:8000 # on macOS
|
||||
```
|
||||
|
||||
Note the above steps are combined into the Ultralytics [build_docs.py](https://github.com/ultralytics/ultralytics/blob/main/docs/build_docs.py) script.
|
||||
|
||||
### Deploying Your Documentation Site
|
||||
|
||||
To deploy your MkDocs documentation site, you will need to choose a hosting provider and a deployment method. Some popular options include GitHub Pages, GitLab Pages, and Amazon S3.
|
||||
|
||||
Before you can deploy your site, you will need to configure your `mkdocs.yml` file to specify the remote host and any other necessary deployment settings.
|
||||
|
||||
Once you have configured your `mkdocs.yml` file, you can use the `mkdocs deploy` command to build and deploy your site. This command will build the documentation site using the files in the `docs/` directory and the specified configuration file and theme, and then deploy the site to the specified remote host.
|
||||
|
||||
For example, to deploy your site to GitHub Pages using the gh-deploy plugin, you can use the following command:
|
||||
|
||||
```bash
|
||||
mkdocs gh-deploy
|
||||
```
|
||||
|
||||
If you are using GitHub Pages, you can set a custom domain for your documentation site by going to the "Settings" page for your repository and updating the "Custom domain" field in the "GitHub Pages" section.
|
||||
|
||||
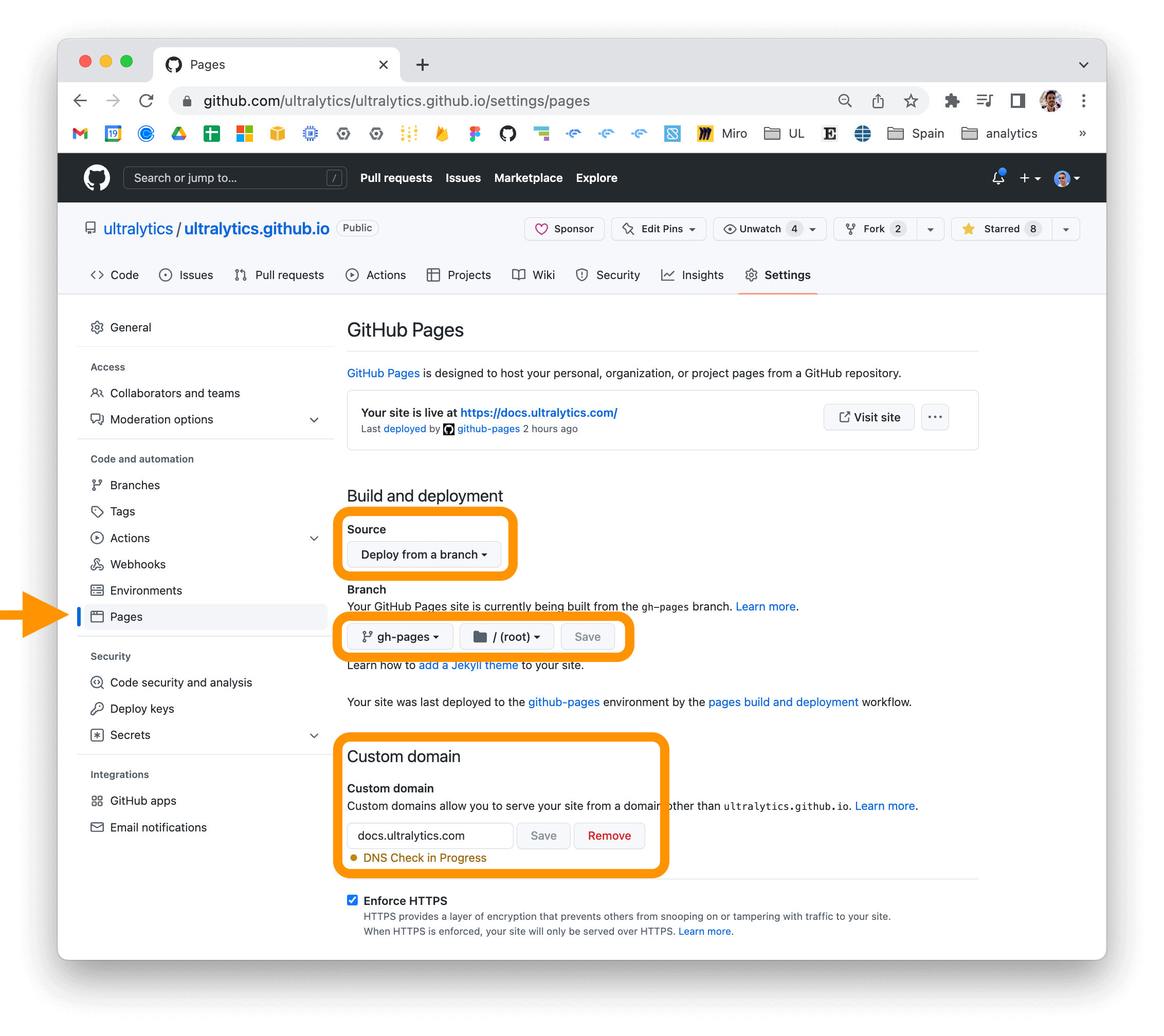
|
||||
|
||||
For more information on deploying your MkDocs documentation site, see the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
||||
|
|
@ -1,82 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف دليل كامل لـ Ultralytics YOLOv8 ، نموذج كشف الكائنات وتجزئة الصور ذو السرعة العالية والدقة العالية. تثبيت المحررة ، والتنبؤ ، والتدريب والمزيد.
|
||||
keywords: Ultralytics، YOLOv8، كشف الكائنات، تجزئة الصور، التعلم الآلي، التعلم العميق، الرؤية الحاسوبية، YOLOv8 installation، YOLOv8 prediction، YOLOv8 training، تاريخ YOLO، تراخيص YOLO
|
||||
---
|
||||
|
||||
<div align="center">
|
||||
<p>
|
||||
<a href="https://yolovision.ultralytics.com" target="_blank">
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/banner-yolov8.png" alt="Ultralytics YOLO banner"></a>
|
||||
</p>
|
||||
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml"><img src="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml/badge.svg" alt="Ultralytics CI"></a>
|
||||
<a href="https://codecov.io/github/ultralytics/ultralytics"><img src="https://codecov.io/github/ultralytics/ultralytics/branch/main/graph/badge.svg?token=HHW7IIVFVY" alt="Ultralytics Code Coverage"></a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv8 Citation"></a>
|
||||
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Pulls"></a>
|
||||
<br>
|
||||
<a href="https://console.paperspace.com/github/ultralytics/ultralytics"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a>
|
||||
<a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||
<a href="https://www.kaggle.com/ultralytics/yolov8"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
</div>
|
||||
|
||||
يتم تقديم [Ultralytics](https://ultralytics.com) [YOLOv8](https://github.com/ultralytics/ultralytics) ، أحدث إصدار من نموذج كشف الكائنات وتجزئة الصور المشهورة للوقت الفعلي. يعتمد YOLOv8 على التطورات المتقدمة في التعلم العميق والرؤية الحاسوبية ، ويقدم أداءً فائقًا من حيث السرعة والدقة. يجعل التصميم البسيط له مناسبًا لمختلف التطبيقات وقابلًا للتكيف بسهولة مع منصات الأجهزة المختلفة ، من الأجهزة الحافة إلى واجهات برمجة التطبيقات في السحابة.
|
||||
|
||||
استكشف أدلة YOLOv8 ، وهي مورد شامل يهدف إلى مساعدتك في فهم واستخدام ميزاته وقدراته. سواء كنت ممارسًا في مجال التعلم الآلي من ذوي الخبرة أو جديدًا في هذا المجال ، فإن الهدف من هذا المركز هو تحقيق الحد الأقصى لإمكانات YOLOv8 في مشاريعك.
|
||||
|
||||
!!! Note "ملاحظة"
|
||||
|
||||
🚧 تم تطوير وثائقنا متعددة اللغات حاليًا ، ونعمل بجد لتحسينها. شكراً لصبرك! 🙏
|
||||
|
||||
## من أين أبدأ
|
||||
|
||||
- **تثبيت** `ultralytics` بواسطة pip والبدء في العمل في دقائق [:material-clock-fast: ابدأ الآن](quickstart.md){ .md-button }
|
||||
- **توقع** الصور ومقاطع الفيديو الجديدة بواسطة YOLOv8 [:octicons-image-16: توقع على الصور](modes/predict.md){ .md-button }
|
||||
- **تدريب** نموذج YOLOv8 الجديد على مجموعة البيانات المخصصة الخاصة بك [:fontawesome-solid-brain: قم بتدريب نموذج](modes/train.md){ .md-button }
|
||||
- **استكشاف** مهام YOLOv8 مثل التجزئة والتصنيف والوضع والتتبع [:material-magnify-expand: استكشاف المهام](tasks/index.md){ .md-button }
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/LNwODJXcvt4?si=7n1UvGRLSd9p5wKs"
|
||||
title="مشغل فيديو يوتيوب" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong> مشاهدة: </strong> كيفية تدريب نموذج YOLOv8 على مجموعة بيانات مخصصة في <a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb" target="_blank">جوجل كولاب</a>.
|
||||
</p>
|
||||
|
||||
## YOLO: نبذة تاريخية
|
||||
|
||||
تم تطوير [YOLO](https://arxiv.org/abs/1506.02640) (You Only Look Once) ، نموذج شهير لكشف الكائنات وتجزئة الصور ، من قبل جوزيف ريدمون وعلي فرهادي في جامعة واشنطن. في عام 2015 ، حققت YOLO شهرة سريعة بفضل سرعتها العالية ودقتها.
|
||||
|
||||
- [YOLOv2](https://arxiv.org/abs/1612.08242) ، الذي تم إصداره في عام 2016 ، قام بتحسين النموذج الأصلي من خلال دمج التطبيع التشغيلي ، ومربعات الربط ، ومجموعات الأبعاد.
|
||||
- [YOLOv3](https://pjreddie.com/media/files/papers/YOLOv3.pdf) ، الذي تم إطلاقه في عام 2018 ، قدم تحسينات إضافية لأداء النموذج باستخدام شبكة ظهر أكثر كفاءة ومرشحات متعددة وتجميع هرم المساحة.
|
||||
- تم إصدار [YOLOv4](https://arxiv.org/abs/2004.10934) في عام 2020 ، وقدم ابتكارات مثل زيادة المساعدات في البيانات ، ورأس جديد للكشف غير المرتبط بالمرابط ، ووظيفة فقدان جديدة.
|
||||
- [YOLOv5](https://github.com/ultralytics/yolov5) قام بتحسين أداء النموذج وأضاف ميزات جديدة مثل تحسين ثوابت النموذج ، وتعقب التجارب المتكامل والتصدير التلقائي إلى تنسيقات التصدير الشهيرة.
|
||||
- [YOLOv6](https://github.com/meituan/YOLOv6) تم تَوْزيعه على [Meituan](https://about.meituan.com/) في عام 2022 وهو قيد الاستخدام في العديد من روبوتات التسليم الذاتي للشركة.
|
||||
- [YOLOv7](https://github.com/WongKinYiu/yolov7) أضاف مهمات إضافية مثل تقدير الوضع على مجموعة بيانات نقاط COCO الرئيسية.
|
||||
- [YOLOv8](https://github.com/ultralytics/ultralytics) هو أحدث إصدار من YOLO بواسطة Ultralytics. باعتباره نموذجًا حديثًا وفريدًا من نوعه ، فإن YOLOv8 يبني على نجاح الإصدارات السابقة ، ويقدم ميزات وتحسينات جديدة لتحسين الأداء والمرونة والكفاءة. يدعم YOLOv8 مجموعة كاملة من مهام الذكاء الصناعي للرؤية ، بما في ذلك [الكشف](tasks/detect.md) ، [التجزئة](tasks/segment.md) ، [تقدير الوضع](tasks/pose.md) ، [التتبع](modes/track.md) ، و [التصنيف](tasks/classify.md). تتيح هذه القابلية للتكيف للمستخدمين استغلال قدرات YOLOv8 في تطبيقات ومجالات متنوعة.
|
||||
|
||||
## تراخيص YOLO: كيف يتم ترخيص Ultralytics YOLO؟
|
||||
|
||||
يوفر Ultralytics خيارين للترخيص لاستيعاب الحالات الاستخدام المتنوعة:
|
||||
|
||||
- **ترخيص AGPL-3.0**: هذا الترخيص مفتوح المصدر والمعتمد من [OSI](https://opensource.org/licenses/) وهو مثالي للطلاب والهواة ، ويشجع على التعاون المفتوح ومشاركة المعرفة. راجع ملف [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) لمزيد من التفاصيل.
|
||||
- **ترخيص المؤسسة**: صمم للاستخدام التجاري ، يسمح هذا الترخيص بدمج سلس للبرمجيات ونماذج AI الخاصة بشركة Ultralytics في السلع والخدمات التجارية ، وتفادي متطلبات المصدر المفتوح لـ AGPL-3.0. إذا تشمل سيناريو الخاص بك تضمين حلولنا في عرض تجاري ، فيرجى التواصل من خلال [Ultralytics Licensing](https://ultralytics.com/license).
|
||||
|
||||
تم تصميم استراتيجية الترخيص الخاصة بنا لضمان أن أي تحسينات على مشاريعنا مفتوحة المصدر يتم إرجاعها إلى المجتمع. نحمل مبادئ المصدر المفتوح قريبة من قلوبنا ❤️ ، ومهمتنا هي ضمان أن يمكن استخدام وتوسيع مساهماتنا بطرق تعود بالنفع على الجميع.
|
||||
|
|
@ -1,191 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف FastSAM ، وهو حلاً مبنيًا على الشبكات العصبية السريعة لتجزئة الكائنات في الوقت الحقيقي في الصور. تفاعل المستخدم المحسّن ، والكفاءة الحسابية ، والقابلية للتكيف في مهام الرؤية المختلفة.
|
||||
keywords: FastSAM ، التعلم الآلي ، حلاً مبنيًا على الشبكات العصبية السريعة ، قسيمة الكائنات ، حلاً في الوقت الحقيقي ، Ultralytics ، مهام الرؤية ، معالجة الصور ، تطبيقات صناعية ، تفاعل المستخدم
|
||||
---
|
||||
|
||||
# نموذج تجزئة أي شيء بسرعة عالية (FastSAM)
|
||||
|
||||
نموذج تجزئة أي شيء بسرعة عالية (FastSAM) هو حلاً مبتكرًا للعصب الشبكي يعمل بالزمن الحقيقي لمهمة تجزئة أي كائن داخل صورة ما. تم تصميم هذه المهمة لتجزئة أي كائن داخل صورة بناءً على إشارات تفاعل المستخدم المختلفة الممكنة. يقلل الـ FastSAM من الاحتياجات الحسابية بشكل كبير مع الحفاظ على أداء تنافسي ، مما يجعله خيارًا عمليًا لمجموعة متنوعة من مهام الرؤية.
|
||||
|
||||

|
||||
|
||||
## نظرة عامة
|
||||
|
||||
تم تصميم FastSAM للتغلب على القيود الموجودة في [نموذج تجزئة ما شيء (SAM)](sam.md) ، وهو نموذج تحويل ثقيل يتطلب موارد حسابية كبيرة. يفصل FastSAM عملية تجزئة أي شيء إلى مرحلتين متسلسلتين: تجزئة جميع الأمثلة واختيار موجه بناءً على التعليمات. تستخدم المرحلة الأولى [YOLOv8-seg](../tasks/segment.md) لإنتاج قناع التجزئة لجميع الأمثلة في الصورة. في المرحلة الثانية ، يتم إخراج منطقة الاهتمام المتعلقة بالتعليمة.
|
||||
|
||||
## المميزات الرئيسية
|
||||
|
||||
1. **حلاً في الوقت الحقيقي**: من خلال استغلال كفاءة الشبكات العصبية الحاسوبية ، يوفر FastSAM حلاً في الوقت الحقيقي لمهمة تجزئة أي شيء ، مما يجعله قيمًا للتطبيقات الصناعية التي تتطلب نتائج سريعة.
|
||||
|
||||
2. **كفاءة وأداء**: يقدم FastSAM تقليل كبير في الاحتياجات الحسابية واستخدام الموارد دون التنازل عن جودة الأداء. يحقق أداءً قابلاً للمقارنة مع SAM ولكن بموارد حسابية مخفضة بشكل كبير ، مما يمكن من تطبيقه في الوقت الحقيقي.
|
||||
|
||||
3. **تجزئة يستند إلى الموجه**: يمكن لـ FastSAM تجزئة أي كائن داخل صورة ترشده مختلف إشارات تفاعل المستخدم الممكنة ، مما يوفر مرونة وقابلية للتكيف في سيناريوهات مختلفة.
|
||||
|
||||
4. **يستند إلى YOLOv8-seg**: يستند FastSAM إلى [YOLOv8-seg](../tasks/segment.md) ، وهو كاشف كائنات مجهز بفرع تجزئة المثيلات. يمكنه بشكل فعال إنتاج قناع التجزئة لجميع الأمثلة في صورة.
|
||||
|
||||
5. **نتائج تنافسية في الاختبارات التحضيرية**: في مهمة اقتراح الكائن على MS COCO ، يحقق FastSAM درجات عالية بسرعة أسرع بكثير من [SAM](sam.md) على بطاقة NVIDIA RTX 3090 واحدة ، مما يدل على كفاءته وقدرته.
|
||||
|
||||
6. **تطبيقات عملية**: توفر الطريقة المقترحة حلاً جديدًا وعمليًا لعدد كبير من مهام الرؤية بسرعة عالية حقًا ، بمعدلات سرعة عشرات أو مئات المرات أسرع من الطرق الحالية.
|
||||
|
||||
7. **جدوى ضغط النموذج**: يظهر FastSAM إمكانية تقليل الجهد الحسابي بشكل كبير من خلال إدخال سابق اصطناعي للهيكل ، مما يفتح إمكانيات جديدة لهندسة هيكل النموذج الكبير لمهام الرؤية العامة.
|
||||
|
||||
## النماذج المتاحة ، المهام المدعومة ، وأوضاع التشغيل
|
||||
|
||||
يعرض هذا الجدول النماذج المتاحة مع أوزانها المحددة ، والمهام التي تدعمها ، ومدى توافقها مع أوضاع التشغيل المختلفة مثل [الاستنتاج](../modes/predict.md) ، [التحقق](../modes/val.md) ، [التدريب](../modes/train.md) ، و[التصدير](../modes/export.md) ، مشار إليها برموز الـ✅ للأوضاع المدعومة والرموز ❌ للأوضاع غير المدعومة.
|
||||
|
||||
| نوع النموذج | أوزان تم تدريبها مسبقًا | المهام المدعومة | الاستنتاج | التحقق | التدريب | التصدير |
|
||||
|-------------|-------------------------|---------------------------------------|-----------|--------|---------|---------|
|
||||
| FastSAM-s | `FastSAM-s.pt` | [تجزئة المثيلات](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
| FastSAM-x | `FastSAM-x.pt` | [تجزئة المثيلات](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
|
||||
## أمثلة الاستخدام
|
||||
|
||||
يسهل دمج نماذج FastSAM في تطبيقات Python الخاصة بك. يوفر Ultralytics واجهة برمجة تطبيقات Python سهلة الاستخدام وأوامر CLI لتسهيل التطوير.
|
||||
|
||||
### استخدام التوقعات
|
||||
|
||||
للقيام بكشف الكائنات في صورة ، استخدم طريقة `predict` كما هو موضح أدناه:
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
from ultralytics import FastSAM
|
||||
from ultralytics.models.fastsam import FastSAMPrompt
|
||||
|
||||
# حدد مصدر التوقع
|
||||
source = 'path/to/bus.jpg'
|
||||
|
||||
# قم بإنشاء نموذج FastSAM
|
||||
model = FastSAM('FastSAM-s.pt') # or FastSAM-x.pt
|
||||
|
||||
# تنفيذ توقعات على صورة
|
||||
everything_results = model(source, device='cpu', retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
|
||||
|
||||
# قم بتجهيز كائن معالج مع قواعد التوقع
|
||||
prompt_process = FastSAMPrompt(source, everything_results, device='cpu')
|
||||
|
||||
# التوقع باستخدام كل شيء
|
||||
ann = prompt_process.everything_prompt()
|
||||
|
||||
# bbox الشكل الافتراضي [0،0،0،0] -> [x1،y1،x2،y2]
|
||||
ann = prompt_process.box_prompt(bbox=[200، 200، 300، 300])
|
||||
|
||||
# التوقع النصي
|
||||
ann = prompt_process.text_prompt(text='صورة لكلب')
|
||||
|
||||
# التوقع النقطي
|
||||
ann = prompt_process.point_prompt(points=[[200، 200]]، pointlabel=[1])
|
||||
prompt_process.plot(annotations=ann، output='./')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
# قم بتحميل نموذج FastSAM وتجزئة كل شيء به
|
||||
yolo segment predict model=FastSAM-s.pt source=path/to/bus.jpg imgsz=640
|
||||
```
|
||||
|
||||
توضح هذه المقاطع البساطة في تحميل نموذج مدرب مسبقًا وتنفيذ توقع على صورة.
|
||||
|
||||
### استخدام مهام التحقق
|
||||
|
||||
يمكن تنفيذ التحقق من النموذج على مجموعة بيانات على النحو التالي:
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
from ultralytics import FastSAM
|
||||
|
||||
# قم بإنشاء نموذج FastSAM
|
||||
model = FastSAM('FastSAM-s.pt') # or FastSAM-x.pt
|
||||
|
||||
# قم بتنفيذ التحقق من النموذج
|
||||
results = model.val(data='coco8-seg.yaml')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
# قم بتحميل نموذج FastSAM وأجرِ التحقق منه بخصوص مجموعة البيانات مثال كوكو 8 بحجم صورة 640
|
||||
yolo segment val model=FastSAM-s.pt data=coco8.yaml imgsz=640
|
||||
```
|
||||
|
||||
يرجى ملاحظة أن الـ FastSAM يدعم فقط الكشف والتجزئة لفئة واحدة من الكائن. هذا يعني أنه سيتعرف ويجزء جميع الكائنات على أنها نفس الفئة. لذلك ، عند إعداد مجموعة البيانات ، يجب تحويل جميع معرفات فئة الكائن إلى 0.
|
||||
|
||||
## استخدام FastSAM الرسمي
|
||||
|
||||
يتوفر نموذج FastSAM مباشرةً من مستودع [https://github.com/CASIA-IVA-Lab/FastSAM](https://github.com/CASIA-IVA-Lab/FastSAM). فيما يلي نظرة عامة موجزة على الخطوات التقليدية التي قد تتخذها لاستخدام FastSAM:
|
||||
|
||||
### التثبيت
|
||||
|
||||
1. استنسخ مستودع FastSAM:
|
||||
```shell
|
||||
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
|
||||
```
|
||||
|
||||
2. أنشئ بيئة Conda وفعّلها بـ Python 3.9:
|
||||
```shell
|
||||
conda create -n FastSAM python=3.9
|
||||
conda activate FastSAM
|
||||
```
|
||||
|
||||
3. انتقل إلى المستودع المنسخ وقم بتثبيت الحزم المطلوبة:
|
||||
```shell
|
||||
cd FastSAM
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
4. قم بتثبيت نموذج CLIP:
|
||||
```shell
|
||||
pip install git+https://github.com/openai/CLIP.git
|
||||
```
|
||||
|
||||
### مثال الاستخدام
|
||||
|
||||
1. قم بتنزيل [تفويض نموذج](https://drive.google.com/file/d/1m1sjY4ihXBU1fZXdQ-Xdj-mDltW-2Rqv/view?usp=sharing).
|
||||
|
||||
2. استخدم FastSAM للتوقع. أمثلة الأوامر:
|
||||
|
||||
- تجزئة كل شيء في صورة:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
|
||||
```
|
||||
|
||||
- تجزئة كائنات محددة باستخدام تعليمات النص:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "الكلب الأصفر"
|
||||
```
|
||||
|
||||
- تجزئة كائنات داخل مربع محدد (تقديم إحداثيات الصندوق في تنسيق xywh):
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[570,200,230,400]"
|
||||
```
|
||||
|
||||
- تجزئة كائنات قرب النقاط المحددة:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
|
||||
```
|
||||
|
||||
بالإضافة إلى ذلك ، يمكنك تجربة FastSAM من خلال [Colab demo](https://colab.research.google.com/drive/1oX14f6IneGGw612WgVlAiy91UHwFAvr9?usp=sharing) أو على [HuggingFace web demo](https://huggingface.co/spaces/An-619/FastSAM) لتجربة بصرية.
|
||||
|
||||
## الاقتباسات والشكر
|
||||
|
||||
نود أن نشكر أباء FastSAM على مساهماتهم الهامة في مجال تجزئة المثيلات في الوقت الحقيقي:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "بيب تيكس"
|
||||
|
||||
```bibtex
|
||||
@misc{zhao2023fast,
|
||||
title={Fast Segment Anything},
|
||||
author={Xu Zhao and Wenchao Ding and Yongqi An and Yinglong Du and Tao Yu and Min Li and Ming Tang and Jinqiao Wang},
|
||||
year={2023},
|
||||
eprint={2306.12156},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
يمكن العثور على ورقة FastSAM الأصلية على [arXiv](https://arxiv.org/abs/2306.12156). قام الأباء بجعل أعمالهم متاحة للجمهور ، ويمكن الوصول إلى قاعدة الكود على [GitHub](https://github.com/CASIA-IVA-Lab/FastSAM). نقدر جهودهم في تطوير المجال وجعل أعمالهم متاحة للمجتمع الأوسع.
|
||||
|
|
@ -1,98 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف مجموعة متنوعة من عائلة YOLO، ونماذج SAM وMobileSAM وFastSAM وYOLO-NAS وRT-DETR المدعومة من Ultralytics. ابدأ بأمثلة لكل من استخدام واجهة الأوامر وPython.
|
||||
keywords: Ultralytics, documentation, YOLO, SAM, MobileSAM, FastSAM, YOLO-NAS, RT-DETR, models, architectures, Python, CLI
|
||||
---
|
||||
|
||||
# النماذج المدعومة من Ultralytics
|
||||
|
||||
أهلاً بك في وثائق نماذج Ultralytics! نحن نقدم الدعم لمجموعة واسعة من النماذج، كل منها مُصمم لمهام محددة مثل [الكشف عن الأجسام](../tasks/detect.md)، [تقطيع الحالات](../tasks/segment.md)، [تصنيف الصور](../tasks/classify.md)، [تقدير الوضعيات](../tasks/pose.md)، و[تتبع الأجسام المتعددة](../modes/track.md). إذا كنت مهتمًا بالمساهمة في هندسة نموذجك مع Ultralytics، راجع دليل [المساهمة](../../help/contributing.md).
|
||||
|
||||
!!! Note "ملاحظة"
|
||||
|
||||
🚧 تحت الإنشاء: وثائقنا بلغات متعددة قيد الإنشاء حاليًا، ونحن نعمل بجد لتحسينها. شكرًا لصبرك! 🙏
|
||||
|
||||
## النماذج المميزة
|
||||
|
||||
إليك بعض النماذج الرئيسية المدعومة:
|
||||
|
||||
1. **[YOLOv3](yolov3.md)**: الإصدار الثالث من عائلة نموذج YOLO، الذي أنشأه أصلاً Joseph Redmon، والمعروف بقدراته الفعالة في الكشف عن الأجسام في الوقت الفعلي.
|
||||
2. **[YOLOv4](yolov4.md)**: تحديث محلي لـ YOLOv3، تم إصداره بواسطة Alexey Bochkovskiy في 2020.
|
||||
3. **[YOLOv5](yolov5.md)**: نسخة مُحسنة من هندسة YOLO من قبل Ultralytics، توفر أداءً أفضل وتوازن في السرعة مقارنة بالإصدارات السابقة.
|
||||
4. **[YOLOv6](yolov6.md)**: أُصدرت بواسطة [Meituan](https://about.meituan.com/) في 2022، ويُستخدم في العديد من روبوتات التوصيل الذاتية للشركة.
|
||||
5. **[YOLOv7](yolov7.md)**: تم إصدار نماذج YOLO المحدثة في 2022 بواسطة مؤلفي YOLOv4.
|
||||
6. **[YOLOv8](yolov8.md) جديد 🚀**: الإصدار الأحدث من عائلة YOLO، يتميز بقدرات مُعززة مثل تقطيع الحالات، تقدير الوضعيات/النقاط الرئيسية، والتصنيف.
|
||||
7. **[Segment Anything Model (SAM)](sam.md)**: نموذج Segment Anything Model (SAM) من Meta.
|
||||
8. **[Mobile Segment Anything Model (MobileSAM)](mobile-sam.md)**: نموذج MobileSAM للتطبيقات المحمولة، من جامعة Kyung Hee.
|
||||
9. **[Fast Segment Anything Model (FastSAM)](fast-sam.md)**: نموذج FastSAM من مجموعة تحليل الصور والفيديو، والمعهد الصيني للأتمتة، وأكاديمية العلوم الصينية.
|
||||
10. **[YOLO-NAS](yolo-nas.md)**: نماذج YOLO Neural Architecture Search (NAS).
|
||||
11. **[Realtime Detection Transformers (RT-DETR)](rtdetr.md)**: نماذج Realtime Detection Transformer (RT-DETR) من PaddlePaddle التابعة لشركة Baidu.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/MWq1UxqTClU?si=nHAW-lYDzrz68jR0"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> تشغيل نماذج YOLO من Ultralytics في بضعة أسطر من الكود فقط.
|
||||
</p>
|
||||
|
||||
## البدء في الاستخدام: أمثلة على الاستخدام
|
||||
|
||||
يوفر هذا المثال أمثلة مبسطة على التدريب والاستدلال باستخدام YOLO. للحصول على الوثائق الكاملة عن هذه وغيرها من [الأوضاع](../modes/index.md), انظر صفحات وثائق [التنبؤ](../modes/predict.md)، و[التدريب](../modes/train.md)، و[التقييم](../modes/val.md) و[التصدير](../modes/export.md).
|
||||
|
||||
لاحظ أن المثال أدناه هو لنماذج [Detect](../tasks/detect.md) YOLOv8 لكشف الأجسام. للاطلاع على المهام الإضافية المدعومة، راجع وثائق [Segment](../tasks/segment.md)، و[Classify](../tasks/classify.md) و[Pose](../tasks/pose.md).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
نماذج `*.pt` المُدربة مسبقًا وملفات الإعداد `*.yaml` يمكن أن تُمرر إلى فئات `YOLO()`, `SAM()`, `NAS()` و `RTDETR()` لإنشاء مثال نموذج في Python:
|
||||
|
||||
```python
|
||||
من ultralytics استيراد YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المُدرب مسبقًا على COCO
|
||||
النموذج = YOLO('yolov8n.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تدريب النموذج على مجموعة البيانات المثالية COCO8 لمدة 100 عصر
|
||||
النتائج = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# تشغيل الاستدلال بنموذج YOLOv8n على صورة 'bus.jpg'
|
||||
النتائج = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
الأوامر CLI متاحة لتشغيل النماذج مباشرة:
|
||||
|
||||
```bash
|
||||
# تحميل نموذج YOLOv8n المُدرب مسبقًا على COCO وتدريبه على مجموعة البيانات المثالية COCO8 لمدة 100 عصر
|
||||
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# تحميل نموذج YOLOv8n المُدرب مسبقًا على COCO وتشغيل الاستدلال على صورة 'bus.jpg'
|
||||
yolo predict model=yolov8n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## المساهمة بنماذج جديدة
|
||||
|
||||
هل أنت مهتم بالمساهمة بنموذجك في Ultralytics؟ رائع! نحن دائمًا منفتحون على توسيع محفظة النماذج لدينا.
|
||||
|
||||
1. **احفظ نسخة عن المستودع**: ابدأ بحفظ نسخة عن [مستودع Ultralytics على GitHub](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
2. **استنسخ نسختك**: انسخ نسختك إلى جهازك المحلي وأنشئ فرعًا جديدًا للعمل عليه.
|
||||
|
||||
3. **طبق نموذجك**: أضف نموذجك متبعًا معايير وإرشادات البرمجة الموفرة في دليل [المساهمة](../../help/contributing.md) لدينا.
|
||||
|
||||
4. **اختبر بدقة**: تأكد من اختبار نموذجك بشكل مكثف، سواء بشكل منفصل أو كجزء من المسار البرمجي.
|
||||
|
||||
5. **أنشئ Pull Request**: بمجرد أن تكون راضًيا عن نموذجك، قم بإنشاء طلب سحب إلى المستودع الرئيسي للمراجعة.
|
||||
|
||||
6. **مراجعة الكود والدمج**: بعد المراجعة، إذا كان نموذجك يلبي معاييرنا، سيتم دمجه في المستودع الرئيسي.
|
||||
|
||||
للخطوات التفصيلية، يرجى الرجوع إلى دليل [المساهمة](../../help/contributing.md).
|
||||
|
|
@ -1,116 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعرّف على MobileSAM وتطبيقه، وقارنه مع SAM الأصلي، وكيفية تنزيله واختباره في إطار Ultralytics. قم بتحسين تطبيقاتك المحمولة اليوم.
|
||||
keywords: MobileSAM، Ultralytics، SAM، التطبيقات المحمولة، Arxiv، GPU، API، مُشفّر الصورة، فك تشفير القناع، تنزيل النموذج، طريقة الاختبار
|
||||
---
|
||||
|
||||

|
||||
|
||||
# التمييز المحمول لأي شيء (MobileSAM)
|
||||
|
||||
الآن يمكنك الاطّلاع على ورقة MobileSAM في [arXiv](https://arxiv.org/pdf/2306.14289.pdf).
|
||||
|
||||
يمكن الوصول إلى عرض مباشر لـ MobileSAM يعمل على وحدة المعالجة المركزية CPU من [هنا](https://huggingface.co/spaces/dhkim2810/MobileSAM). يستغرق الأداء على وحدة المعالجة المركزية Mac i5 تقريبًا 3 ثوانٍ. في عرض الواجهة التفاعلية الخاص بهنغ فيس، تؤدي واجهة المستخدم ووحدات المعالجة المركزية ذات الأداء المنخفض إلى استجابة أبطأ، لكنها تواصل العمل بفعالية.
|
||||
|
||||
تم تنفيذ MobileSAM في عدة مشاريع بما في ذلك [Grounding-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything) و [AnyLabeling](https://github.com/vietanhdev/anylabeling) و [Segment Anything in 3D](https://github.com/Jumpat/SegmentAnythingin3D).
|
||||
|
||||
تم تدريب MobileSAM على وحدة المعالجة الرسومية (GPU) الواحدة باستخدام مجموعة بيانات تحتوي على 100000 صورة (1% من الصور الأصلية) في أقل من يوم واحد. سيتم توفير الشفرة المصدرية لعملية التدريب هذه في المستقبل.
|
||||
|
||||
## النماذج المتاحة، المهام المدعومة، وأوضاع التشغيل
|
||||
|
||||
يُعرض في هذا الجدول النماذج المتاحة مع وزنها المدرب مسبقًا، والمهام التي تدعمها، وتوافقها مع أوضاع التشغيل المختلفة مثل [الاستدلال](../modes/predict.md)، [التحقق](../modes/val.md)، [التدريب](../modes/train.md)، و [التصدير](../modes/export.md)، حيث يُشير إيموجي ✅ للأوضاع المدعومة وإيموجي ❌ للأوضاع غير المدعومة.
|
||||
|
||||
| نوع النموذج | الأوزان المدربة مسبقًا | المهام المدعومة | الاستدلال | التحقق | التدريب | التصدير |
|
||||
|-------------|------------------------|--------------------------------------|-----------|--------|---------|---------|
|
||||
| MobileSAM | `mobile_sam.pt` | [تجزئة العناصر](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
|
||||
## التحويل من SAM إلى MobileSAM
|
||||
|
||||
نظرًا لأن MobileSAM يحتفظ بنفس سير العمل لـ SAM الأصلي، قمنا بدمج التجهيزات المسبقة والتجهيزات اللاحقة للنموذج الأصلي وجميع الواجهات الأخرى. نتيجة لذلك، يمكن لأولئك الذين يستخدمون حاليًا SAM الأصلي الانتقال إلى MobileSAM بقدر أدنى من الجهد.
|
||||
|
||||
يؤدي MobileSAM بشكل مقارب لـ SAM الأصلي ويحتفظ بنفس سير العمل باستثناء تغيير في مُشفر الصورة. على وحدة المعالجة الرسومية (GPU) الواحدة، يعمل MobileSAM بمعدل 12 مللي ثانية لكل صورة: 8 مللي ثانية لمُشفر الصورة و4 مللي ثانية لفك تشفير القناع.
|
||||
|
||||
يوفر الجدول التالي مقارنة بين مُشفرات الصور القائمة على ViT:
|
||||
|
||||
| مُشفّر الصورة | SAM الأصلي | MobileSAM |
|
||||
|---------------|----------------|--------------|
|
||||
| العوامل | 611 مليون | 5 مليون |
|
||||
| السرعة | 452 مللي ثانية | 8 مللي ثانية |
|
||||
|
||||
يستخدم SَM الأصلي و MobileSAM نفس فك تشفير القناع الذي يعتمد على التوجيه بواسطة الرموز:
|
||||
|
||||
| فك تشفير القناع | SAM الأصلي | MobileSAM |
|
||||
|-----------------|--------------|--------------|
|
||||
| العوامل | 3.876 مليون | 3.876 مليون |
|
||||
| السرعة | 4 مللي ثانية | 4 مللي ثانية |
|
||||
|
||||
فيما يلي مقارنة لكامل سير العمل:
|
||||
|
||||
| السير الكامل (التشفير+الفك) | SAM الأصلي | MobileSAM |
|
||||
|-----------------------------|----------------|---------------|
|
||||
| العوامل | 615 مليون | 9.66 مليون |
|
||||
| السرعة | 456 مللي ثانية | 12 مللي ثانية |
|
||||
|
||||
يتم عرض أداء MobileSAM و SAM الأصلي باستخدام كل من النقطة ومربع كلمة المحفز.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
بفضل أدائه المتفوق، يكون MobileSAM أصغر بحوالي 5 أضعاف وأسرع بحوالي 7 أضعاف من FastSAM الحالي. يتوفر مزيد من التفاصيل على [صفحة مشروع MobileSAM](https://github.com/ChaoningZhang/MobileSAM).
|
||||
|
||||
## اختبار MobileSAM في Ultralytics
|
||||
|
||||
مثل SAM الأصلي، نقدم طريقة اختبار مبسّطة في Ultralytics، بما في ذلك وضعي النقطة والصندوق.
|
||||
|
||||
### تنزيل النموذج
|
||||
|
||||
يمكنك تنزيل النموذج [هنا](https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt).
|
||||
|
||||
### النقطة ككلمة محفز
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# تحميل النموذج
|
||||
model = SAM('mobile_sam.pt')
|
||||
|
||||
# توقع جزء بناءً على نقطة محفز
|
||||
model.predict('ultralytics/assets/zidane.jpg', points=[900, 370], labels=[1])
|
||||
```
|
||||
|
||||
### الصندوق ككلمة محفز
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# تحميل النموذج
|
||||
model = SAM('mobile_sam.pt')
|
||||
|
||||
# توقع جزء بناءً على صندوق محفز
|
||||
model.predict('ultralytics/assets/zidane.jpg', bboxes=[439, 437, 524, 709])
|
||||
```
|
||||
|
||||
لقد قمنا بتنفيذ "MobileSAM" و "SAM" باستخدام نفس API. لمزيد من معلومات الاستخدام، يُرجى الاطّلاع على [صفحة SAM](sam.md).
|
||||
|
||||
## الاقتباس والشكر
|
||||
|
||||
إذا وجدت MobileSAM مفيدًا في أبحاثك أو عملك التطويري، يُرجى النظر في استشهاد ورقتنا:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{mobile_sam,
|
||||
title={Faster Segment Anything: Towards Lightweight SAM for Mobile Applications},
|
||||
author={Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung Ho and Lee, Seungkyu and Hong, Choong Seon},
|
||||
journal={arXiv preprint arXiv:2306.14289},
|
||||
year={2023}
|
||||
}
|
||||
|
|
@ -1,93 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: اكتشف ميزات وفوائد RT-DETR من Baidu، وهو كاشف كائنات فعال وقابل للتكيف في الوقت الفعلي يعتمد على Vision Transformers، بما في ذلك النماذج المدربة مسبقًا.
|
||||
keywords: RT-DETR, Baidu, Vision Transformers, كشف كائنات, أداء فوري, CUDA, TensorRT, اختيار الاستعلام المرتبط بـ IoU, Ultralytics, واجهة برمجة التطبيقات الخاصة بلغة Python, PaddlePaddle
|
||||
---
|
||||
|
||||
# RT-DETR من Baidu: اكتشاف كائنات في الوقت الفعلي يعتمد على Vision Transformer
|
||||
|
||||
## النظرة العامة
|
||||
|
||||
Real-Time Detection Transformer (RT-DETR)، المطور من قبل Baidu، هو كاشف حديث الطراز يوفر أداءً فعليًا في الوقت الفعلي مع الحفاظ على دقة عالية. يستفيد من قوة Vision Transformers (ViT) في معالجة الميزات متعددة المقياس عن طريق فصل التفاعلات داخل المقياس ودمج التفاعلات بين المقاييس المختلفة. يتكيف RT-DETR بشكل كبير ويدعم ضبط سرعة الاستعلام باستخدام طبقات مختلفة في المفكرة بدون إعادة التدريب. يتفوق هذا النموذج على العديد من كاشفات الكائنات في الوقت الفعلي الأخرى، ويستفيد من المنصات القوية مثل CUDA مع TensorRT.
|
||||
|
||||

|
||||
**نظرة عامة على RT-DETR من Baidu.** يعرض مخطط معمارية نموذج RT-DETR مراحل الظهر الثلاث الأخيرة {S3، S4، S5} كإدخال للمشفر. يحول المشفر الهجين الفعال الميزات متعددة المقياس إلى تسلسل من ميزات الصورة من خلال تفاعل الميزات داخل المقياس (AIFI) ووحدة دمج الميزات بين المقاييس المختلفة (CCFM). يتم استخدام اختيار الاستعلام المرتبط بـ IoU لاختيار عدد ثابت من ميزات الصورة لتكون استعلامات الكائن الأولية لفك الترميز. أخيرًا، يحسن فك الترميز مع رؤوس التنبؤ الإضافية الاستعلامات الكائنية لتوليد المربعات وتقييمات الثقة ([المصدر](https://arxiv.org/pdf/2304.08069.pdf)).
|
||||
|
||||
### الميزات الرئيسية
|
||||
|
||||
- **مشفر هجين فعال:** يستخدم RT-DETR من Baidu مشفر هجين فعال يعمل على معالجة الميزات متعددة المقياس من خلال فصل التفاعلات داخل المقياس ودمج التفاعلات بين المقاييس المختلفة. يقلل هذا التصميم الفريد القائم على Vision Transformers من تكاليف الحسابات ويتيح الكشف عن الكائنات في الوقت الفعلي.
|
||||
- **اختيار الاستعلام المرتبط بـ IoU:** يعمل RT-DETR من Baidu على تحسين بدء استعلام الكائنات من خلال استخدام اختيار الاستعلام المرتبط بـ IoU. يتيح هذا للنموذج التركيز على الكائنات الأكثر صلة في السيناريو، مما يعزز دقة الكشف.
|
||||
- **سرعة الاستنتاج قابلة للتكيف:** يدعم RT-DETR من Baidu ضبط سرعة الاستنتاج بشكل مرن باستخدام طبقات مختلفة في المفكرة دون الحاجة لإعادة التدريب. يسهل هذا التكيف التطبيق العملي في العديد من سيناريوهات كشف الكائنات في الوقت الفعلي.
|
||||
|
||||
## النماذج المدربة مسبقًا
|
||||
|
||||
تقدم واجهة برمجة التطبيقات الخاصة بلغة Python في Ultralytics نماذج PaddlePaddle RT-DETR مدربة مسبقًا بمقاييس مختلفة:
|
||||
|
||||
- RT-DETR-L: 53.0% AP على COCO val2017، 114 FPS على GPU T4
|
||||
- RT-DETR-X: 54.8% AP على COCO val2017، 74 FPS على GPU T4
|
||||
|
||||
## أمثلة الاستخدام
|
||||
|
||||
يوفر هذا المثال أمثلة بسيطة لتدريب واختبار RT-DETRR. للحصول على وثائق كاملة حول هذه الأمثلة وأوضاع أخرى [انقر هنا](../modes/index.md) للاطلاع على صفحات الوثائق [التنبؤ](../modes/predict.md)، [التدريب](../modes/train.md)، [التصحيح](../modes/val.md) و [التصدير](../modes/export.md).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import RTDETR
|
||||
|
||||
# تحميل نموذج RT-DETR-l محمي بواسطة COCO مسبقًا
|
||||
model = RTDETR('rtdetr-l.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تدريب النموذج على مجموعة بيانات المثال COCO8 لـ 100 دورة
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# تشغيل الاستدلال باستخدام النموذج RT-DETR-l على صورة 'bus.jpg'
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# تحميل نموذج RT-DETR-l محمي بواسطة COCO مسبقًا وتدريبه على مجموعة بيانات المثال COCO8 لـ 100 دورة
|
||||
yolo train model=rtdetr-l.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# تحميل نموذج RT-DETR-l محمي بواسطة COCO مسبقًا وتشغيل الاستدلال على صورة 'bus.jpg'
|
||||
yolo predict model=rtdetr-l.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## المهام والأوضاع المدعومة
|
||||
|
||||
يقدم هذا الجدول أنواع النماذج والأوزان المدربة مسبقًا المحددة والمهام المدعومة بواسطة كل نموذج، والأوضاع المختلفة ([التدريب](../modes/train.md)، [التصحيح](../modes/val.md)، [التنبؤ](../modes/predict.md)، [التصدير](../modes/export.md)) التي يتم دعمها، ممثلة برموز الـ ✅.
|
||||
|
||||
| نوع النموذج | الأوزان المدربة مسبقًا | المهام المدعومة | استنتاج | تحقق صحة | تدريب | استيراد |
|
||||
|-----------------------|------------------------|----------------------------------|---------|----------|-------|---------|
|
||||
| RT-DETR الكبير | `rtdetr-l.pt` | [كشف كائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| RT-DETR الكبير الزائد | `rtdetr-x.pt` | [كشف كائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
## الاستشهادات والتقديرات
|
||||
|
||||
إذا استخدمت RT-DETR من Baidu في أعمال البحث أو التطوير الخاصة بك، يرجى الاستشهاد بـ [الورقة الأصلية](https://arxiv.org/abs/2304.08069):
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{lv2023detrs,
|
||||
title={DETRs Beat YOLOs on Real-time Object Detection},
|
||||
author={Wenyu Lv and Shangliang Xu and Yian Zhao and Guanzhong Wang and Jinman Wei and Cheng Cui and Yuning Du and Qingqing Dang and Yi Liu},
|
||||
year={2023},
|
||||
eprint={2304.08069},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
نحن نود أن نعرب عن امتناننا لـ Baidu وفريق [PaddlePaddle](https://github.com/PaddlePaddle/PaddleDetection) لإنشاء وصيانة هذ المورد القيم لمجتمع الرؤية الحاسوبية. نقدر تفاعلهم مع المجال من خلال تطوير كاشف الكائنات الحقيقي في الوقت الفعلي القائم على Vision Transformers، RT-DETR.
|
||||
|
||||
*keywords: RT-DETR، الناقل، Vision Transformers، Baidu RT-DETR، PaddlePaddle، Paddle Paddle RT-DETR، كشف كائنات في الوقت الفعلي، كشف كائنات قائم على Vision Transformers، نماذج PaddlePaddle RT-DETR مدربة مسبقًا، استخدام Baidu's RT-DETR، واجهة برمجة التطبيقات الخاصة بلغة Python في Ultralytics*
|
||||
|
|
@ -1,225 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف النموذج القاطع للشيء أيا كان (SAM) الحديث من Ultralytics الذي يتيح الت segment تشفير صور الوقت الحقيقي. تعرف على مرونته في مجال الت segment، وأداء نقل انيفورم زيرو شوت، وكيفية استخدامه.
|
||||
keywords: Ultralytics, قسيمة الصور, Segment Anything Model, SAM, سلسلة بيانات SA-1B, مرونة الصور في الوقت الحقيقي, نقل الانيفورم زيرو شوت, الكشف عن الكائنات, تحليل الصور, التعلم الآلي
|
||||
---
|
||||
|
||||
# نموذج القطعة شيء ما (SAM)
|
||||
|
||||
مرحبًا بك في الجبهة الأولى لقطع الصور مع نموذج القطعة شيء ما ، أو SAM. هذا النموذج الثوري قد غير اللعبة من خلال إدخال التشفير القراءة للصور مع أداء في الوقت الحقيقي، وتحديد معايير جديدة في هذا المجال.
|
||||
|
||||
## مقدمة إلى SAM: القطعة شيء ما نموذج
|
||||
|
||||
نموذج القطعة شيء ما ، أو SAM، هو نموذج شفاف اول في فصل الصور الرقمية التي تتيح قدرة شهير على التشفير، توفر مرونة فريدة من نوعها في مهام التحليل اللازمة للصور. نموذج SAM هو أساس مشروع 'أي شيء في شيء' الابتكاري و هو مشروع يقدم نموذجا جديدا ، مهمة وسلسلة بيانات مبتكرة للفصل البصري.
|
||||
|
||||
يتيح تصميم SAM المتقدم له التكيف مع توزيعات صور جديدة ومهام جديدة دون الحاجة إلى معرفة مسبقة، وهذه الميزة تعرف بالكفاءة المطلوبة. حيث يتم تدريبه على سلسلة البيانات الواسعة [سلسلة SA-1B](https://ai.facebook.com/datasets/segment-anything/)، التي تحتوي على أكثر من ملياري قناع معروض على 11 مليون صورة تمت المحافظة عليها بعناية، وقد عرض SAM أداء مثير للإعجاب مع نقل انيفورم زيرو شوت فاق النتائج المراقبة السابقة بالتدريب الكامل في العديد من الحالات.
|
||||
|
||||

|
||||
صور مثالية مع قناع محاط بها من سلسلة البيانات التي قدمناها حديثًا ، SA-1B. يحتوي سلسلة SA-1B على 11 مليون صورة متنوعة ، عالية الدقة ، مرخصة وتحمي الخصوصية و 1.1 مليار قناع فصل جودة عالية. تم توجيه هذه القناع تمامًا بتقويم آلي من قبل SAM وتم التحقق من جودتها وتنوعها من خلال تصنيفات بشرية وتجارب عديدة. يتم تجميع الصور حسب عدد الأقنعة في كل صورة للتصوير (هناك حوالي 100 قناع في الصورة في المتوسط).
|
||||
|
||||
## السمات الرئيسية لنموذج القطعة شيء ما (SAM)
|
||||
|
||||
- **مهمة التشفير القضائية:** تم تصميم SAM بهدف مهمة التشفير القابلة للتشفير ، مما يتيح له إنشاء قناع تشفير صالح من أي تلميح معين ، مثل الدلائل المكانية أو النصية التي تحدد الكائن.
|
||||
- **بنية متقدمة:** يستخدم نموذج القطعة شيء ما مُشفر صورة قوي ، مشفر تشفير ومُشفر بسهولة الويغورة. تمكن هذه البنية الفريدة من فتح المجال للتشفير المرن ، وحساب القناع في الوقت الحقيقي ، والاستعداد للغموض في مهام التشفير.
|
||||
- **سلسلة البيانات SA-1B:** التي قدمها مشروع أي شيء في شيء، تعرض سلسلة البيانات SA-1B أكثر من ملياري قناع على 11 مليون صورة. كأكبر سلسلة بيانات للفصل حتى الآن، توفر نموذج SAM مصدر تدريب ضخم ومتنوع.
|
||||
- **أداء نقل الانيفورم زيرو شوت:** يعرض نموذج SAM أداء رائع في نقل الانيفورم زيرو شوت في مهام القطع المختلفة، مما يجعله أداة قوية جاهزة للاستخدام في تطبيقات متنوعة مع حاجة قليلة جدًا لهندسة التشفير الخاصة.
|
||||
|
||||
للحصول على نظرة شاملة على نموذج القطعة شيء ما وسلسلة SA-1B، يرجى زيارة [موقع أي شيء في شيء](https://segment-anything.com) واطلع على بحث [أي شيء في شيء](https://arxiv.org/abs/2304.02643).
|
||||
|
||||
## النماذج المتاحة والمهام المدعومة ووضعيات العمل
|
||||
|
||||
تقدم هذه الجدول النماذج المتاحة مع أوزان محددة مسبقًا والمهام التي يدعمونها وتوافقهم مع وضعيات العمل المختلفة مثل [قراءة الصورة](../modes/predict.md)، [التحقق](../modes/val.md)، [التدريب](../modes/train.md)، و [التصدير](../modes/export.md) ، مما يشير إلى ✅ رموز الدعم و ❌ للوضعيات غير المدعومة.
|
||||
|
||||
| نوع النموذج | الأوزان المدربة مسبقًا | المهام المدعومة | قراءة الصورة | التحقق | التدريب | التصدير |
|
||||
|-------------|------------------------|------------------------------------|--------------|--------|---------|---------|
|
||||
| SAM الأساسي | `sam_b.pt` | [تجزئة النسخ](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
| SAM الكبير | `sam_l.pt` | [تجزئة النسخ](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
|
||||
## كيفية استخدام SAM: مرونة وقوة في تجزئة الصورة
|
||||
|
||||
يمكن استخدام نموذج القطعة شيء من أجل العديد من المهام التابعة إلى تدريبه. يشمل ذلك الكشف عن الحافة، إنشاء ترشيح للكائنات، تجزئة نسخة وتوقع نص مبدئي للتشفير. مع التشفير المهني ، يمكن لـ SAM التكيف بسرعة مع المهمات وتوزيعات البيانات الجديدة بطريقة transfer zero-shot، وبالتالي يعتبر أداة متعددة الاستخدامات وفعالة لجميع احتياجات تجزئة الصورة.
|
||||
|
||||
### مثال لدمج SAM
|
||||
|
||||
!!! Example "القسم بالاشارات"
|
||||
|
||||
تقسيم الصورة مع الإشارات المعطاة.
|
||||
|
||||
=== "البايثون"
|
||||
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# تحميل النموذج
|
||||
model = SAM('sam_b.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تشغيل التنبوء بواسطة الدلائل
|
||||
model('ultralytics/assets/zidane.jpg', bboxes=[439, 437, 524, 709])
|
||||
|
||||
# تشغيل التنبوء بواسطة نقاط الإشارة
|
||||
model('ultralytics/assets/zidane.jpg', points=[900, 370], labels=[1])
|
||||
```
|
||||
|
||||
!!! Example "قطع كل الشيء"
|
||||
|
||||
قم بتجزئة الصورة بأكملها.
|
||||
|
||||
=== "البايثون"
|
||||
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# تحميل النموذج
|
||||
model = SAM('sam_b.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تشغيل التنبوء
|
||||
model('مسار/إلى/صورة.jpg')
|
||||
```
|
||||
|
||||
=== "صفيحة"
|
||||
|
||||
```البايش
|
||||
# تشغيل التنبوء بنموذج SAM
|
||||
yolo predict model=sam_b.pt source=path/to/image.jpg
|
||||
```
|
||||
|
||||
- المنطق هنا هو تجزئة الصورة كلها إذا لم تمر عبر أي إشارات (bboxes/ points / masks).
|
||||
|
||||
!!! Example "مثال على SAMPredictor"
|
||||
|
||||
بواسطة هذا الطريق ، يمكنك تعيين الصورة مرة واحدة وتشغيل الإشارات مرارًا وتكرارًا دون تشغيل مشفر الصورة مرة أخرى.
|
||||
|
||||
=== "التنبؤ بالإشارة"
|
||||
|
||||
```البايثون
|
||||
from ultralytics.models.sam import Predictor as SAMPredictor
|
||||
|
||||
# إنشاء SAMPredictor
|
||||
الأعلى = dict (الثقة = 0.25، task ='segment'، النمط = 'تنبؤ'، imgsz = 1024، نموذج = "mobile_sam.pt")
|
||||
predictor = SAMPredictor (overrides = التجاوز الأعلى)
|
||||
|
||||
# تعيين الصورة
|
||||
predictor.set_image("ultralytics/assets/zidane.jpg") # تعيين بواسطة ملف صورة
|
||||
predictor.set_image(cv2.imread("ultralytics/assets/zidane.jpg")) # تعيين مع np.ndarray
|
||||
results = predictor(bboxes=[439, 437, 524, 709])
|
||||
results = predictor(points=[900, 370], labels=[1])
|
||||
|
||||
# إعادة تعيين الصورة
|
||||
predictor.reset_image()
|
||||
```
|
||||
|
||||
قطع كل شيء مع وجود معطيات اختيارية.
|
||||
|
||||
=== "تقطيع كل شيء"
|
||||
|
||||
```البايثون
|
||||
from ultralytics.models.sam import Predictor as SAMPredictor
|
||||
|
||||
# إنشاء SAMPredictor
|
||||
الأعلى = dict (الثقة = 0.25، task ='segment'، النمط = 'تنبؤ'، imgsz = 1024، نموذج = "mobile_sam.pt")
|
||||
predictor = SAMPredictor (overrides = التجاوز الأعلى)
|
||||
|
||||
# تجزئة مع بيانات إضافية
|
||||
results = predictor(source="ultralytics/assets/zidane.jpg"، crop_n_layers=1، points_stride=64)
|
||||
```
|
||||
|
||||
- المزيد args إضافي للتقطيع كل شيء شاهد التوثيق مرجع [`السلبي/تقديم` مرجع](../../../reference/models/sam/predict.md).
|
||||
|
||||
## مقارنة SAM مقابل YOLOv8
|
||||
|
||||
في هذا المكان نقارن نموذج SAM الأصغر سام، SAM-b ، مع نموذج التجزئة YOLOv8 الصغيرة Ultralytics، [YOLOv8n-seg](../tasks/segment.md):
|
||||
|
||||
| النموذج | الحجم | المعلمات | السرعة (المعالج) |
|
||||
|----------------------------------------------|----------------------------|-----------------------|--------------------------|
|
||||
| سام SAM-b | 358 م.بايت | 94.7 M | 51096 ms/im |
|
||||
| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im |
|
||||
| [FastSAM-s](fast-sam.md) with YOLOv8 حافظة | 23.7 MB | 11.8 M | 115 ms/im |
|
||||
| [YOLOv8n-seg](../tasks/segment.md) ل Ultraly | **6.7 MB** (53.4 مرة أصغر) | **3.4 M** (27.9x أقل) | **59 ms/im** (866x أسرع) |
|
||||
|
||||
هذه المقارنة تظهر الاختلافات في أمر المقدار والسرعة بين النماذج. في حين يقدم SAM قدرات فريدة للتجزئة التلقائية ، إلا أنه ليس منافسًا مباشرًا لنماذج التجزئة YOLOv8 ، حيث تكون أصغر وأسرع وأكثر كفاءة.
|
||||
|
||||
اكتنزات التجريب على ماكينة Apple M2 Macbook 2023 مع 16GB من الذاكرة. لإعادة إنتاج هذا الاختبار:
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "البايثون"
|
||||
```البايثون
|
||||
from ultralytics import FastSAM, SAM, YOLO
|
||||
|
||||
# تحليل يام-b
|
||||
model = SAM('sam_b.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
|
||||
# تحليل MobileSAM
|
||||
model = SAM('mobile_sam.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
|
||||
# تحليل FastSAM-s
|
||||
model = FastSAM('FastSAM-s.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
|
||||
# تحليل YOLOv8n-seg
|
||||
model = YOLO('yolov8n-seg.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
```
|
||||
|
||||
## تعلم تلقائي: مسار سريع إلى سلاسل البيانات الخاصة بالتجزئة
|
||||
|
||||
التعلم التلقائي هو ميزة رئيسية لـ SAM، حيث يسمح للمستخدمين بإنشاء [سلاسل بيانات تجزئة](https://docs.ultralytics.com/datasets/segment) باستخدام نموذج الكشف الجاهز. يتيح هذا الميزة إنشاء وتحديث سريع ودقيق لعدد كبير من الصور بدون الحاجة إلى عملية التسمية اليدوية البطيئة.
|
||||
|
||||
### إنشاء سلاسل البيانات الخاصة بالتجزئة باستخدام نموذج الكشف
|
||||
|
||||
للتعليم التلقائي لسلاسل البيانات الخاصة بالتجزئة باستخدام إطار العمل Ultralytics ، استخدم وظيفة 'auto_annotate' كما هو موضح أدناه:
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "البايثون"
|
||||
```البايثون
|
||||
from ultralytics.data.annotator import auto_annotate
|
||||
|
||||
auto_annotate(data="مسار/إلى/صور", det_model="yolov8x.pt", sam_model='sam_b.pt')
|
||||
```
|
||||
|
||||
| الوسيطة | النوع | الوصف | الافتراضي |
|
||||
|------------|------------------------|---------------------------------------------------------------------------------------------------------------------------|--------------|
|
||||
| البيانات | سلسلة | المسار إلى المجلد الذي يحتوي على الصور التي سيتم الإشارة إليها. | |
|
||||
| det_model | سلسلة، اختياري | نموذج الكشف المدرب المسبق لـ YOLO. الافتراضي هو 'yolov8x.pt'. | 'yolov8x.pt' |
|
||||
| sam_model | سلسلة، اختياري | نموذج القطعة أيا شيء من Ultralytics. الافتراضي هو 'sam_b.pt'. | 'sam_b.pt' |
|
||||
| device | سلسلة، اختياري | الجهاز الذي يتم تشغيل النماذج عليه. الافتراضي هو سلسلة فارغة (وحدة المعالجة المركزية أو وحدة معالجة الرسومات إذا توافرت). | |
|
||||
| output_dir | سلسلة، لا شيء، اختياري | الدليل لحفظ النتائج المرئية. الافتراضي هو مجلد 'التسميات' في نفس دليل 'البيانات'. | لا شيء |
|
||||
|
||||
يأخذ تابع 'auto_annotate' المسار إلى الصور الخاصة بك مع وسيطات اختيارية لتحديد نموذج الكشف المدرب مسبقًا ونموذج التجزئة SAM والجهاز الذي سيتم تشغيل النماذج به والدليل الخروج لحفظ النتائج المرئية.
|
||||
|
||||
تعلم تلقائيًا باستخدام نماذج مدربة مسبقًا يمكن أن يقلل بشكل كبير من الوقت والجهد المطلوب لإنشاء سلاسل بيانات تجزئة عالية الجودة. يكون هذا الأمر مفيدًا خصوصًا للباحثين والمطورين الذين يتعاملون مع مجموعات صور كبيرة ، حيث يتيح لهم التركيز على تطوير النماذج وتقييمها بدلاً من التسمية اليدوية البطيئة.
|
||||
|
||||
## الاقتباسات والتقديرات
|
||||
|
||||
إذا وجدت SAM مفيدًا في البحث أو العمل التطويري الخاص بك ، يرجى النظر في استشهاد بحثنا:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "البيبتيكس"
|
||||
```البيبتيكس
|
||||
@misc{kirillov2023segment,
|
||||
title={Segment Anything},
|
||||
author={Alexander Kirillov and Eric Mintun and Nikhila Ravi and Hanzi Mao and Chloe Rolland and Laura Gustafson and Tete Xiao and Spencer Whitehead and Alexander C. Berg and Wan-Yen Lo and Piotr Dollár and Ross Girshick},
|
||||
year={2023},
|
||||
eprint={2304.02643},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
نود أن نعبر عن امتناننا لـ Meta AI لإنشاء وصيانة هذا المورد القيم لمجتمع البصريات الحواسيبية.
|
||||
|
||||
*أكلمات دالة: سلسلة المفعولة, نموذج القطعة شيء ما, SAM, Meta SAM, التجزئة, التشفير المميز, آلة آي, segment, Ultralytics, نماذج مدربة مسبقا, SAM الاساسي, SAM الكبير, تجزئة الكيانات, الرؤية الكمبيوترية, آي الاصطناعية, التعلم الآلي, تسمية بيانات, قناع التجزئة, نموذج الكشف, نموذج الكشف YOLO, البيبتكس, Meta AI.*
|
||||
|
|
@ -1,121 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف التوثيق المفصل لـ YOLO-NAS ، وهو نموذج كشف الكائنات المتطور. تعلم المزيد عن ميزاته والطرز المدربة مسبقًا واستخدامه مع واجهة برمجة Ultralytics Python وأكثر من ذلك.
|
||||
keywords: YOLO-NAS, Deci AI, كشف الكائنات, deep learning, البحث في الهندسة العصبية, واجهة برمجة Ultralytics Python, نموذج YOLO, الطرز المدربة مسبقًا, كمّية, التحسين, COCO, Objects365, Roboflow 100
|
||||
---
|
||||
|
||||
# YOLO-NAS
|
||||
|
||||
## نظرة عامة
|
||||
|
||||
تم تطوير YOLO-NAS بواسطة ديسي ايه اي ، وهو نموذج استشعار الكائنات الطائرة للأمام الذي يقدم تطورًا مبتكرًا. إنه منتج تكنولوجيا بحث الهندسة العصبية المتقدمة ، المصممة بعناية لمعالجة القيود التي كانت تعاني منها النماذج السابقة YOLO. مع تحسينات كبيرة في دعم التمثيل الكموني وتنازلات الدقة والتأخير ، يمثل YOLO-NAS قفزة كبيرة في كشف الكائنات.
|
||||
|
||||

|
||||
**نظرة عامة على YOLO-NAS.** يستخدم YOLO-NAS كتلًا تفاعلية للتمثيل الكموني وتمثيل كمي للحصول على أداء مثلى. يواجه النموذج ، عند تحويله إلى الإصدار المكون من 8 بت ، انخفاضًا طفيفًا في الدقة ، وهو تحسين كبير على النماذج الأخرى. تتوج هذه التطورات بتصميم متفوق ذي قدرات استشعار للكائنات لا مثيل لها وأداء متميز.
|
||||
|
||||
### المزايا الرئيسية
|
||||
|
||||
- **كتلة أساسية ودية للتمثيل الكموني:** يقدم YOLO-NAS كتلة أساسية جديدة ودية للتمثيل الكموني ، مما يعالج أحد القيود الرئيسية للنماذج السابقة YOLO.
|
||||
- **تدريب متطور وتمثيل كمي:** يستخدم YOLO-NAS نظم تدريب متقدمة وتمثيلًا للكم بعد التدريب لتعزيز الأداء.
|
||||
- **تحسين AutoNAC والتدريب المسبق:** يستخدم YOLO-NAS تحسين AutoNAC ويتم تدريبه مسبقًا على مجموعات بيانات بارزة مثل COCO و Objects365 و Roboflow 100. يجعل هذا التدريب المسبق مناسبًا لمهام استشعار الكائنات الفرعية في بيئات الإنتاج.
|
||||
|
||||
## الطرز المدربة مسبقًا
|
||||
|
||||
استمتع بقوة كشف الكائنات من الجيل القادم مع الطرز المدربة مسبقًا لـ YOLO-NAS التي يوفرها Ultralytics. تم تصميم هذه الطرز لتقديم أداء متفوق من حيث السرعة والدقة. اختر من بين مجموعة متنوعة من الخيارات المصممة وفقًا لاحتياجاتك الخاصة:
|
||||
|
||||
| الطراز | مؤشر التقدير المتوسط (mAP) | تأخر الوقت (ms) |
|
||||
|------------------|----------------------------|-----------------|
|
||||
| YOLO-NAS S | 47.5 | 3.21 |
|
||||
| YOLO-NAS M | 51.55 | 5.85 |
|
||||
| YOLO-NAS L | 52.22 | 7.87 |
|
||||
| YOLO-NAS S INT-8 | 47.03 | 2.36 |
|
||||
| YOLO-NAS M INT-8 | 51.0 | 3.78 |
|
||||
| YOLO-NAS L INT-8 | 52.1 | 4.78 |
|
||||
|
||||
تم تصميم كل نسخة من النموذج لتقديم توازن بين متوسط الدقة (mAP) وتأخير الوقت ، مما يساعدك في تحسين مهام كشف الكائنات الخاصة بك من حيث الأداء والسرعة.
|
||||
|
||||
## أمثلة الاستخدام
|
||||
|
||||
قام Ultralytics بجعل طرز YOLO-NAS سهلة الدمج في تطبيقات Python الخاصة بك عبر حزمة `ultralytics` الخاصة بنا. توفر الحزمة واجهة برمجة التطبيقات بسيطة الاستخدام لتسهيل العملية.
|
||||
|
||||
توضح الأمثلة التالية كيفية استخدام طرز YOLO-NAS مع حزمة `ultralytics` للكشف والتحقق:
|
||||
|
||||
### أمثلة الكشف والتحقق
|
||||
|
||||
في هذا المثال ، نقوم بالتحقق من صحة YOLO-NAS-s على مجموعة بيانات COCO8.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
يوفر هذا المثال رمز بسيط لعملية الكشف والتحقق لـ YOLO-NAS. لمعالجة نتائج الاستدلال ، انظر وضع [توقع](../modes/predict.md). لاستخدام YOLO-NAS مع وضعيات إضافية ، انظر [توصيف](../modes/val.md) و[تصدير](../modes/export.md). لا يدعم نظام YOLO-NAS على حزمة `ultralytics` عملية التدريب.
|
||||
|
||||
=== "Python"
|
||||
|
||||
يمكن تمرير نماذج PyTorch المدربة مسبقًا `*.pt` إلى فئة `NAS()` لإنشاء نموذج في Python:
|
||||
|
||||
```python
|
||||
from ultralytics import NAS
|
||||
|
||||
# تحميل نموذج YOLO-NAS-s المدرب مسبقًا على COCO
|
||||
model = NAS('yolo_nas_s.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# التحقق من صحة النموذج على مجموعة بيانات مثال COCO8
|
||||
results = model.val(data='coco8.yaml')
|
||||
|
||||
# تشغيل استدلال باستخدام نموذج YOLO-NAS-s على صورة 'bus.jpg'
|
||||
results = model('path/to/bus.jpg'))
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
تتوفر أوامر CLI لتشغيل النماذج مباشرة:
|
||||
|
||||
```bash
|
||||
# تحميل نموذج YOLO-NAS-s المدرب مسبقًا على COCO والتحقق من أدائه على مجموعة بيانات مثال COCO8
|
||||
yolo val model=yolo_nas_s.pt data=coco8.yaml
|
||||
|
||||
# تحميل نموذج YOLO-NAS-s المدرب مسبقًا على COCO والتنبؤ بالاستدلال على صورة 'bus.jpg'
|
||||
yolo predict model=yolo_nas_s.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## المهام والأوضاع المدعومة
|
||||
|
||||
نحن نقدم ثلاثة أنواع من نماذج YOLO-NAS: الصغير (s) ، المتوسط (m) ، والكبير (l). يتم تصميم كل نسخة لتلبية احتياجات الحوسبة والأداء المختلفة:
|
||||
|
||||
- **YOLO-NAS-s**: محسنة للبيئات التي تكون فيها الموارد الحسابية محدودة والكفاءة هي الأهم.
|
||||
- **YOLO-NAS-m**: يقدم نهجًا متوازنًا ، مناسبًا لكشف الكائنات العامة بدقة أعلى.
|
||||
- **YOLO-NAS-l**: مصممة للسيناريوهات التي تتطلب أعلى درجة من الدقة ، حيث الموارد الحسابية أقل قيدًا.
|
||||
|
||||
أدناه نظرة عامة مفصلة عن كل نموذج ، بما في ذلك روابط أوزانهم المدربين مسبقًا ، والمهام التي يدعمونها ، وتوافقهم مع وضعيات التشغيل المختلفة.
|
||||
|
||||
| نوع النموذج | أوزان مدربة مسبقًا | المهام المدعومة | الاستدلال | التحقق | التدريب | التصدير |
|
||||
|-------------|-----------------------------------------------------------------------------------------------|------------------------------------|-----------|--------|---------|---------|
|
||||
| YOLO-NAS-s | [yolo_nas_s.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolo_nas_s.pt) | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
|
||||
| YOLO-NAS-m | [yolo_nas_m.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolo_nas_m.pt) | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
|
||||
| YOLO-NAS-l | [yolo_nas_l.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolo_nas_l.pt) | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
|
||||
|
||||
## الاقتباسات والشكر
|
||||
|
||||
إذا استخدمت YOLO-NAS في أعمالك البحثية أو التطويرية ، يرجى الاستشهاد بمشروع SuperGradients:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{supergradients,
|
||||
doi = {10.5281/ZENODO.7789328},
|
||||
url = {https://zenodo.org/record/7789328},
|
||||
author = {Aharon, Shay and {Louis-Dupont} and {Ofri Masad} and Yurkova, Kate and {Lotem Fridman} and {Lkdci} and Khvedchenya, Eugene and Rubin, Ran and Bagrov, Natan and Tymchenko, Borys and Keren, Tomer and Zhilko, Alexander and {Eran-Deci}},
|
||||
title = {Super-Gradients},
|
||||
publisher = {GitHub},
|
||||
journal = {GitHub repository},
|
||||
year = {2021},
|
||||
}
|
||||
```
|
||||
|
||||
نعبر عن امتناننا لفريق [SuperGradients](https://github.com/Deci-AI/super-gradients/) في Deci AI لجهودهم في إنشاء وصيانة هذة الموارد القيمة لمجتمع رؤية الحاسوب. نعتقد أن YOLO-NAS ، بتصميمه المبتكر وقدرته الاستشعار المتفوقة للكائنات ، سيصبح أداة حاسمة للمطورين والباحثين على حد سواء.
|
||||
|
||||
*keywords: YOLO-NAS, Deci AI, كشف الكائنات, deep learning, البحث في الهندسة العصبية, واجهة برمجة Ultralytics Python, نموذج YOLO, SuperGradients, الطرز المدربة مسبقًا, كتلة أساسية ودية للتمثيل الكموني, أنظمة تدريب متطورة, تمثيل كمي بعد التدريب, تحسين AutoNAC, COCO, Objects365, Roboflow 100*
|
||||
|
|
@ -1,98 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: احصل على نظرة عامة حول YOLOv3 و YOLOv3-Ultralytics و YOLOv3u. تعرف على ميزاتها الرئيسية واستخدامها والمهام المدعومة للكشف عن الكائنات.
|
||||
keywords: YOLOv3، YOLOv3-Ultralytics، YOLOv3u، الكشف عن الكائنات، إجراء، التدريب، Ultralytics
|
||||
---
|
||||
|
||||
# YOLOv3 و YOLOv3-Ultralytics و YOLOv3u
|
||||
|
||||
## النظرة العامة
|
||||
|
||||
يقدم هذا الوثيقة نظرة عامة على ثلاث نماذج مرتبطة بكشف الكائنات ، وهي [YOLOv3](https://pjreddie.com/darknet/yolo/) و [YOLOv3-Ultralytics](https://github.com/ultralytics/yolov3) و [YOLOv3u](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
1. **YOLOv3:** هذه هي الإصدار الثالث من خوارزمية You Only Look Once (YOLO) للكشف عن الكائنات. قام جوزيف ريدمون بتطويرها بالأصل ، وقد قامت YOLOv3 بتحسين سابقيها من خلال إدخال ميزات مثل التنبؤات متعددة المقياس وثلاثة أحجام مختلفة من نوى الكشف.
|
||||
|
||||
2. **YOLOv3-Ultralytics:** هذه هي تنفيذ Ultralytics لنموذج YOLOv3. يقوم بإعادة إنتاج بنية YOLOv3 الأصلية ويقدم وظائف إضافية ، مثل دعم المزيد من النماذج المدربة مسبقًا وخيارات تخصيص أسهل.
|
||||
|
||||
3. **YOLOv3u:** هذا هو الإصدار المُحدّث لـ YOLOv3-Ultralytics الذي يدمج رأس الكشف بدون مشتركات وبدون مستخدم الكائن الذي يستخدم في نماذج YOLOv8. يحتفظ YOLOv3u بنفس بنية العمود الفقري والعنق مثل YOLOv3 ولكن برأس الكشف المُحدث من YOLOv8.
|
||||
|
||||

|
||||
|
||||
## الميزات الرئيسية
|
||||
|
||||
- **YOLOv3:** قدم استخدام ثلاث مقياسات مختلفة للكشف ، باستخدام ثلاثة أحجام مختلفة من نوى الكشف: 13x13 ، 26x26 و 52x52. هذا يحسن بشكل كبير دقة الكشف للكائنات ذات الأحجام المختلفة. بالإضافة إلى ذلك ، أضاف YOLOv3 ميزات مثل التنبؤات متعددة العلامات لكل مربع محاذاة وشبكة استخراج سمات أفضل.
|
||||
|
||||
- **YOLOv3-Ultralytics:** توفر تنفيذ Ultralytics لـ YOLOv3 نفس الأداء مثل النموذج الأصلي ولكنه يأتي مع دعم إضافي للمزيد من النماذج المدربة مسبقًا وطرق تدريب إضافية وخيارات أسهل للتخصيص. هذا يجعلها أكثر مرونة وسهولة استخداماً للتطبيقات العملية.
|
||||
|
||||
- **YOLOv3u:** يدمج هذا النموذج المُحدّث رأس الكشف بدون مشتركات وبدون مستخدم الكائن من YOLOv8. من خلال إزالة الحاجة إلى صناديق المرجع المحددة مسبقًا ودرجات تكون الكائن ، يمكن أن يحسن تصميم رأس الكشف هذا قدرة النموذج على كشف الكائنات ذات الأحجام والأشكال المتنوعة. هذا يجعل YOLOv3u أكثر مرونة ودقة لمهام كشف الكائنات.
|
||||
|
||||
## المهام المدعومة والأوضاع
|
||||
|
||||
تم تصميم سلسلة YOLOv3 ، بما في ذلك YOLOv3 و YOLOv3-Ultralytics و YOLOv3u ، خصيصًا لمهام الكشف عن الكائنات. يشتهر هذه النماذج بفعاليتها في سيناريوهات العالم الحقيقي المختلفة ، مع توازن دقة الكشف والسرعة. يوفر كل طراز ميزات وتحسينات فريدة ، مما يجعلها مناسبة لمجموعة متنوعة من التطبيقات.
|
||||
|
||||
يدعم النماذج الثلاثة وضعًا شاملاً من الأوضاع ، مما يضمن مرونة في مراحل مختلفة من نموذج النشر والتطوير. هذه الأوضاع تشمل [التمييز](../modes/predict.md) ، [التحقق](../modes/val.md) ، [التدريب](../modes/train.md) و [التصدير](../modes/export.md) ، مما يوفر للمستخدمين مجموعة كاملة من أدوات فعالة للكشف عن الكائنات.
|
||||
|
||||
| نوع النموذج | المهام المدعومة | التمييز | التحقق | التدريب | التصدير |
|
||||
|--------------------|------------------------------------|---------|--------|---------|---------|
|
||||
| YOLOv3 | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv3-Ultralytics | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv3u | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
توفر هذه الجدولة نظرة فورية على إمكانات كل نسخة من YOLOv3 ، مما يسلط الضوء على مرونتها وملاءمتها لمختلف المهام وأوضاع العمل العملية في سير العمل لكشف الكائنات.
|
||||
|
||||
## أمثلة الاستخدام
|
||||
|
||||
يقدم هذا المثال أمثلة بسيطة للتدريب والتنبؤ باستخدام YOLOv3. للحصول على وثائق كاملة حول هذه وغيرها من [الأوضاع](../modes/index.md) انظر صفحات الوثائق: [التنبؤ](../modes/predict.md) ، (../modes/train.md) [Val](../modes/val.md) و [التصدير](../modes/export.md) docs.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "بيثون"
|
||||
|
||||
يمكن تمرير نماذج PyTorch المدربة مسبقًا `*.pt` وملفات التكوين `*.yaml` إلى فئة `YOLO()` لإنشاء نموذج في Python:
|
||||
|
||||
```python
|
||||
من ultralytics استيراد YOLO
|
||||
|
||||
# تحميل نموذج YOLOv3n المدرب مسبقًا على COCO
|
||||
model = YOLO('yolov3n.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تدريب النموذج على مجموعة البيانات المثالية Coco8 لمدة 100 دورة تدريب
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# قم بتشغيل التنبؤ باستخدام نموذج YOLOv3n على صورة 'bus.jpg'
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
تتوفر أوامر CLI لتشغيل النماذج مباشرة:
|
||||
|
||||
```bash
|
||||
# تحميل نموذج YOLOv3n المدرب مسبقًا على COCO وقم بتدريبه على مجموعة البيانات المثالية Coco8 لمدة 100 دورة تدريب
|
||||
yolo train model=yolov3n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# تحميل نموذج YOLOv3n المدرب مسبقًا على COCO وتشغيل التنبؤ على صورة 'bus.jpg'
|
||||
yolo predict model=yolov3n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## الاقتباسات والشكر
|
||||
|
||||
إذا قمت باستخدام YOLOv3 في بحثك ، فيرجى الاقتباس لأوراق YOLO الأصلية ومستودع Ultralytics YOLOv3:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "بيب تيكس"
|
||||
|
||||
```bibtex
|
||||
@article{redmon2018yolov3,
|
||||
title={YOLOv3: An Incremental Improvement},
|
||||
author={Redmon, Joseph and Farhadi, Ali},
|
||||
journal={arXiv preprint arXiv:1804.02767},
|
||||
year={2018}
|
||||
}
|
||||
```
|
||||
|
||||
شكراً لجوزيف ريدمون وعلي فرهادي على تطوير YOLOv3 الأصلي.
|
||||
|
|
@ -1,72 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف دليلنا التفصيلي على YOLOv4 ، وهو جهاز كشف الكائنات الحديثة في الوقت الحقيقي. فهم أبرز معالم التصميم المعماري الخاصة به ، والميزات المبتكرة ، وأمثلة التطبيق.
|
||||
keywords: ultralytics ، yolo v4 ، كشف الكائنات ، شبكة عصبية ، كشف في الوقت الحقيقي ، كاشف الكائنات ، تعلم الآلة
|
||||
|
||||
---
|
||||
|
||||
# YOLOv4: الكشف العالي السرعة والدقة للكائنات
|
||||
|
||||
أهلاً بك في صفحة وثائق Ultralytics لـ YOLOv4 ، جهاز كشف الكائنات الحديث في الوقت الحقيقي الذي تم إطلاقه في عام 2020 من قبل Alexey Bochkovskiy على [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet). تم تصميم YOLOv4 لتوفير التوازن المثالي بين السرعة والدقة ، مما يجعله خيارًا ممتازًا للعديد من التطبيقات.
|
||||
|
||||

|
||||
**رسم توضيحي لهندسة YOLOv4**. يعرض التصميم المعماري المعقد لشبكة YOLOv4 ، بما في ذلك المكونات الرئيسية والرقبة والرأس ، والطبقات المترابطة للكشف الفعال في الوقت الحقيقي.
|
||||
|
||||
## مقدمة
|
||||
|
||||
تعني YOLOv4 "فقط تنظر مرة واحدة النسخة 4". هو نموذج كشف الكائنات الحقيقي الزمني الذي تم تطويره لمعالجة قيود الإصدارات السابقة لـ YOLO مثل [YOLOv3](yolov3.md) ونماذج كشف الكائنات الأخرى. على عكس كاشفات الكائنات الأخرى القائمة على الشبكات العصبية المتزاحمة المستخدمة للكشف عن الكائنات ، يمكن تطبيق YOLOv4 لأنظمة الوصية النصحية وكذلك لإدارة العملية المستقلة وتقليل الإدخالات البشرية. يتيح تشغيله على وحدات معالجة الرسومات القياسية (GPUs) الاستخدام الشامل بتكلفة معقولة ، وتم تصميمه للعمل في الوقت الفعلي على وحدة معالجة الرسومات التقليدية مع الحاجة إلى وحدة واحدة فقط من هذا النوع للتدريب.
|
||||
|
||||
## الهندسة
|
||||
|
||||
تستغل YOLOv4 العديد من الميزات المبتكرة التي تعمل معًا لتحسين أدائها. تشمل هذه الميزات الاتصالات المتبقية المرجحة (WRC) ، والاتصالات الجزئية عبر المرحلة المتقاطعة (CSP) ، والتطبيع المتقاطع المصغر لدُفع (CmBN) ، والتدريب المتنازع لنفسه (SAT) ، وتنشيط Mish ، وزيادة بيانات الزخم ، وتنظيم DropBlock ، وخسارة CIoU. يتم دمج هذه الميزات لتحقيق أحدث النتائج.
|
||||
|
||||
يتألف كاشف الكائنات النموذجي من عدة أجزاء بما في ذلك المدخل والظهر والرقبة والرأس. يتم تدريب الظهرية لـ YOLOv4 سلفًا على ImageNet ويستخدم لتوقع فئات ومربعات محيطة للكائنات. يمكن أن يكون الظهرية من عدة نماذج بما في ذلك VGG و ResNet و ResNeXt أو DenseNet. يتم استخدام جزء الرقبة من الكاشف لجمع خرائط الميزات من مراحل مختلفة وعادة ما يتضمن عدة مسارات لأسفل وعدة مسارات للأعلى. جزء الرأس هو ما يستخدم لإجراء اكتشاف الكائنات والتصنيف النهائي.
|
||||
|
||||
## الحقيبة المجانية
|
||||
|
||||
يستخدم YOLOv4 أيضًا طرقًا تعرف باسم "حقيبة المجانيات" وهي تقنيات تحسِّن دقة النموذج أثناء التدريب دون زيادة تكلفة الاستنتاج. تعد التعديلات في البيانات تقنية شائعة في كشف الكائنات ، والتي تزيد من تنوع صور الإدخال لتحسين قوة الموديل. بعض أمثلة التعديل في البيانات تشمل التشويهات البصرية (ضبط السطوع والتباين والدرجة والتشبع والضوضاء في الصورة) والتشويهات الهندسية (إضافة توزيع عشوائي للتغيير المقياسي والاقتصاص والانعكاس والتدوير). تساعد هذه التقنيات الموديل في التعميم على أنواع مختلفة من الصور.
|
||||
|
||||
## الميزات والأداء
|
||||
|
||||
تم تصميم YOLOv4 لتحقيق سرعة ودقة مثلى في كشف الكائنات. يتضمن تصميم YOLOv4 CSPDarknet53 كظهر ، PANet كرقبة ، و YOLOv3 كرأس كشف. يسمح هذا التصميم لـ YOLOv4 بأداء كشف الكائنات بسرعة مذهلة ، مما يجعله مناسبًا لتطبيقات الوقت الحقيقي. يتفوق YOLOv4 أيضًا في الدقة ، ويحقق نتائج عالية في مقاييس كشف الكائنات.
|
||||
|
||||
## أمثلة الاستخدام
|
||||
|
||||
في وقت كتابة هذا النص ، لا يدعم Ultralytics حاليًا نماذج YOLOv4. لذلك ، سيحتاج أي مستخدمين مهتمين باستخدام YOLOv4 إلى الرجوع مباشرة إلى مستودع YOLOv4 على GitHub للحصول على تعليمات التثبيت والاستخدام.
|
||||
|
||||
إليك نظرة عامة موجزة على الخطوات النموذجية التي يمكن أن تتخذها لاستخدام YOLOv4:
|
||||
|
||||
1. قم بزيارة مستودع YOLOv4 على GitHub: [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet).
|
||||
|
||||
2. اتبع التعليمات المقدمة في ملف README لعملية التثبيت. ينطوي هذا عادة على استنساخ المستودع ، وتثبيت التبعيات اللازمة ، وإعداد أي متغيرات بيئة ضرورية.
|
||||
|
||||
3. بمجرد الانتهاء من التثبيت ، يمكنك تدريب واستخدام النموذج وفقًا لتعليمات الاستخدام المقدمة في المستودع. يتضمن ذلك عادة إعداد مجموعة البيانات الخاصة بك ، وتكوين معاملات النموذج ، وتدريب النموذج ، ثم استخدام النموذج المدرب لأداء اكتشاف الكائنات.
|
||||
|
||||
يرجى ملاحظة أن الخطوات النموذجية قد تختلف اعتمادًا على حالة الاستخدام الخاصة بك وحالة مستودع YOLOv4 الحالي. لذلك ، يُنصح بشدة بالرجوع مباشرة إلى التعليمات المقدمة في مستودع YOLOv4 على GitHub.
|
||||
|
||||
نؤسف على أي إزعاج ، وسنسعى لتحديث هذا المستند بأمثلة استخدام لـ Ultralytics بمجرد تنفيذ الدعم لـ YOLOv4.
|
||||
|
||||
## الاستنتاج
|
||||
|
||||
YOLOv4 هو نموذج قوي وفعال لكشف الكائنات يجمع بين السرعة والدقة. يستخدم الميزات الفريدة وتقنيات الزخم في التدريب للأداء بشكل ممتاز في مهام اكتشاف الكائنات في الوقت الفعلي. يمكن لأي شخص يمتلك وحدة معالجة رسومية تقليدية تدريب YOLOv4 واستخدامها ، مما يجعلها سهلة الوصول وعملية لمجموعة واسعة من التطبيقات.
|
||||
|
||||
## التنويه والتقديرات
|
||||
|
||||
نود أن نعترف بمساهمة أصحاب YOLOv4 في مجال كشف الكائنات الحقيقية الزمنية:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "بيب تكس"
|
||||
|
||||
```bibtex
|
||||
@misc{bochkovskiy2020yolov4,
|
||||
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
|
||||
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
|
||||
year={2020},
|
||||
eprint={2004.10934},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
يمكن العثور على ورقة YOLOv4 الأصلية على [arXiv](https://arxiv.org/pdf/2004.10934.pdf). قام المؤلفون بتوفير عملهم بشكل عام ، ويمكن الوصول إلى قاعدة الشفرات على [GitHub](https://github.com/AlexeyAB/darknet). نقدر جهودهم في تعزيز الميدان وتوفير عملهم للمجتمع العريض.
|
||||
|
|
@ -1,107 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: اكتشف YOLOv5u، وهو إصدار معزز لنموذج YOLOv5 يوفر توازنًا محسنًا بين الدقة والسرعة والعديد من النماذج المدربة مسبقًا لمهام كشف الكائنات المختلفة.
|
||||
keywords: YOLOv5u، كشف الكائنات، النماذج المدربة مسبقًا، Ultralytics، التشخيص، التحقق، YOLOv5، YOLOv8، بدون قاعدة تثبيت العقدة الرئيسية، بدون قيمة الكائن، التطبيقات الفعلية، تعلم الآلة
|
||||
---
|
||||
|
||||
# YOLOv5
|
||||
|
||||
## نظرة عامة
|
||||
|
||||
يمثل YOLOv5u تقدمًا في منهجيات كشف الكائنات. يندرج YOLOv5u تحت البنية المعمارية الأساسية لنموذج [YOLOv5](https://github.com/ultralytics/yolov5) الذي طورته شركة Ultralytics، و يدمج نموذج YOLOv5u ميزة القسمة على جزئين للكائنات المستقلة عن القاعدة التي تم تقديمها في نماذج [YOLOv8](yolov8.md). تحسين هذا النمط يحسن نمط النموذج، مما يؤدي إلى تحسين التوازن بين الدقة والسرعة في مهام كشف الكائنات. بناءً على النتائج التجريبية والمزايا المشتقة منها، يقدم YOLOv5u بديلاً فعالًا لأولئك الذين يسعون لإيجاد حلول قوية في الأبحاث والتطبيقات العملية.
|
||||
|
||||

|
||||
|
||||
## المزايا الرئيسية
|
||||
|
||||
- **رأس Ultralytics للقسمة بدون قاعدة تثبيت العقدة:** يعتمد نماذج كشف الكائنات التقليدية على صناديق قاعدة محددة مسبقًا لتوقع مواقع الكائنات. ومع ذلك، يحدث تحديث في نهج YOLOv5u هذا. من خلال اعتماد رأس Ultralytics المُقسم بدون قاعدة تثبيت العقدة، يضمن هذا النمط آلية كشف أكثر مرونة واندفاعًا، مما يعزز الأداء في سيناريوهات متنوعة.
|
||||
|
||||
- **توازن محسن بين الدقة والسرعة:** تتصارع السرعة والدقة في العديد من الأحيان. ولكن YOLOv5u يتحدى هذا التوازن. يقدم توازنًا معايرًا، ويضمن كشفًا في الوقت الفعلي دون المساومة على الدقة. تعد هذه الميزة ذات قيمة خاصة للتطبيقات التي تتطلب استجابة سريعة، مثل المركبات المستقلة والروبوتات وتحليل الفيديو في الوقت الفعلي.
|
||||
|
||||
- **مجموعة متنوعة من النماذج المدربة مسبقًا:** على فهم الأمور التي تحتاج إلى مجموعات أدوات مختلفة YOLOv5u يوفر العديد من النماذج المدربة مسبقًا. سواء كنت تركز على التشخيص أو التحقق أو التدريب، هناك نموذج مصمم خصيصًا ينتظرك. يضمن هذا التنوع أنك لا تستخدم حلاً من نوع واحد يناسب الجميع، ولكن نموذج موازن حسب حاجتك الفريدة.
|
||||
|
||||
## المهام والأوضاع المدعومة
|
||||
|
||||
تتفوق نماذج YOLOv5u، مع مجموعة متنوعة من الأوزان المدربة مسبقًا، في مهام [كشف الكائنات](../tasks/detect.md). تدعم هذه النماذج مجموعة شاملة من الأوضاع، مما يجعلها مناسبة لتطبيقات متنوعة، من التطوير إلى التنفيذ.
|
||||
|
||||
| نوع النموذج | الأوزان المدربة مسبقًا | المهمة | التشخيص | التحقق | التدريب | التصدير |
|
||||
|-------------|-----------------------------------------------------------------------------------------------------------------------------|------------------------------------|---------|--------|---------|---------|
|
||||
| YOLOv5u | `yolov5nu`, `yolov5su`, `yolov5mu`, `yolov5lu`, `yolov5xu`, `yolov5n6u`, `yolov5s6u`, `yolov5m6u`, `yolov5l6u`, `yolov5x6u` | [كشف الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
يوفر هذا الجدول نظرة عامة مفصلة عن البدائل من نماذج نموذج YOLOv5u، ويسلط الضوء على تطبيقاتها في مهام كشف الكائنات ودعمها لأوضاع تشغيل متنوعة مثل [التشخيص](../modes/predict.md)، [التحقق](../modes/val.md)، [التدريب](../modes/train.md)، و[التصدير](../modes/export.md). يضمن هذا الدعم الشامل أن يمكن للمستخدمين استغلال قدرات نماذج YOLOv5u بشكل كامل في مجموعة واسعة من سيناريوهات كشف الكائنات.
|
||||
|
||||
## الأداء
|
||||
|
||||
!!! الأداء
|
||||
|
||||
=== "كشف"
|
||||
|
||||
راجع [وثائق الكشف](https://docs.ultralytics.com/tasks/detect/) للحصول على أمثلة استخدام مع هذه النماذج المدربة على [COCO](https://docs.ultralytics.com/datasets/detect/coco/)، التي تشمل 80 فئة مدربة مسبقًا.
|
||||
|
||||
| النموذج | يامل | حجم<br><sup>(بكسل) | mAP<sup>val<br>50-95 | سرعة<br><sup>معالج الجهاز ONNX<br>(مللي ثانية) | سرعة<br><sup>حويصلة A100 TensorRT<br>(مللي ثانية) | المعلمات<br><sup>(مليون) | FLOPs<br><sup>(بليون) |
|
||||
|---------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
|
||||
| [yolov5nu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5nu.pt) | [yolov5n.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
|
||||
| [yolov5su.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5su.pt) | [yolov5s.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 43.0 | 120.7 | 1.27 | 9.1 | 24.0 |
|
||||
| [yolov5mu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5mu.pt) | [yolov5m.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 49.0 | 233.9 | 1.86 | 25.1 | 64.2 |
|
||||
| [yolov5lu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5lu.pt) | [yolov5l.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 52.2 | 408.4 | 2.50 | 53.2 | 135.0 |
|
||||
| [yolov5xu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5xu.pt) | [yolov5x.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 53.2 | 763.2 | 3.81 | 97.2 | 246.4 |
|
||||
| | | | | | | | |
|
||||
| [yolov5n6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5n6u.pt) | [yolov5n6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 42.1 | 211.0 | 1.83 | 4.3 | 7.8 |
|
||||
| [yolov5s6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5s6u.pt) | [yolov5s6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 48.6 | 422.6 | 2.34 | 15.3 | 24.6 |
|
||||
| [yolov5m6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5m6u.pt) | [yolov5m6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 53.6 | 810.9 | 4.36 | 41.2 | 65.7 |
|
||||
| [yolov5l6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5l6u.pt) | [yolov5l6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 55.7 | 1470.9 | 5.47 | 86.1 | 137.4 |
|
||||
| [yolov5x6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5x6u.pt) | [yolov5x6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 56.8 | 2436.5 | 8.98 | 155.4 | 250.7 |
|
||||
|
||||
## أمثلة للاستخدام
|
||||
|
||||
يقدم هذا المثال أمثلة بسيطة للغاية للتدريب والتشخيص باستخدام YOLOv5. يُمكن إنشاء نموذج مثيل في البرمجة باستخدام نماذج PyTorch المدربة مسبقًا في صيغة `*.pt` وملفات التكوين `*.yaml`:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
#قم بتحميل نموذج YOLOv5n المدرب مسبقًا على مجموعة بيانات COCO
|
||||
model = YOLO('yolov5n.pt')
|
||||
|
||||
# قم بعرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# قم بتدريب النموذج على مجموعة البيانات COCO8 لمدة 100 دورة
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# قم بتشغيل التشخيص بنموذج YOLOv5n على صورة 'bus.jpg'
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "سطر الأوامر"
|
||||
|
||||
يتاح سطر الأوامر لتشغيل النماذج مباشرة:
|
||||
|
||||
```bash
|
||||
# قم بتحميل نموذج YOLOv5n المدرب مسبقًا على مجموعة بيانات COCO8 وقم بتدريبه لمدة 100 دورة
|
||||
yolo train model=yolov5n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# قم بتحميل نموذج YOLOv5n المدرب مسبقًا على مجموعة بيانات COCO8 وتشغيل حالة التشخيص على صورة 'bus.jpg'
|
||||
yolo predict model=yolov5n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## الاستشهادات والتقدير
|
||||
|
||||
إذا قمت باستخدام YOLOv5 أو YOLOv5u في بحثك، يرجى استشهاد نموذج Ultralytics YOLOv5 بطريقة الاقتباس التالية:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
```bibtex
|
||||
@software{yolov5,
|
||||
title = {Ultralytics YOLOv5},
|
||||
author = {Glenn Jocher},
|
||||
year = {2020},
|
||||
version = {7.0},
|
||||
license = {AGPL-3.0},
|
||||
url = {https://github.com/ultralytics/yolov5},
|
||||
doi = {10.5281/zenodo.3908559},
|
||||
orcid = {0000-0001-5950-6979}
|
||||
}
|
||||
```
|
||||
|
||||
يرجى ملاحظة أن نماذج YOLOv5 متاحة بترخيص [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) و[Enterprise](https://ultralytics.com/license).
|
||||
|
|
@ -1,107 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف نموذج Meituan YOLOv6 للكشف عن الكائنات الحديثة، والذي يوفر توازنًا مذهلاً بين السرعة والدقة، مما يجعله الخيار الأمثل لتطبيقات الوقت الحقيقي. تعرّف على الميزات والنماذج المُدربة مسبقًا واستخدام Python.
|
||||
keywords: Meituan YOLOv6، الكشف عن الكائنات، Ultralytics، YOLOv6 docs، Bi-directional Concatenation، تدريب بمساعدة العناصر، النماذج المدربة مسبقا، تطبيقات الوقت الحقيقي
|
||||
---
|
||||
|
||||
# Meituan YOLOv6
|
||||
|
||||
## نظرة عامة
|
||||
|
||||
[Meituan](https://about.meituan.com/) YOLOv6 هو منظّف الكائنات الحديثة الحديثة الذي يُقدم توازنًا ملحوظًا بين السرعة والدقة، مما يجعله خيارًا شائعًا لتطبيقات الوقت الحقيقي. يُقدم هذا النموذج العديد من التحسينات الملحوظة في بنيته ونظام التدريب، بما في ذلك تطبيق وحدة Bi-directional Concatenation (BiC)، واستراتيجية AAT (anchor-aided training) التي تعتمد على العناصر، وتصميم محسّن للأساس والرقبة لتحقيق أداء على مجموعة بيانات COCO يفوق جميع النماذج الأخرى.
|
||||
|
||||

|
||||

|
||||
**نظرة عامة على YOLOv6.** مخطط بنية النموذج يوضح المكونات المعاد تصميمها واستراتيجيات التدريب التي أدت إلى تحسينات أداء كبيرة. (أ) الرقبة الخاصة بـ YOLOv6 (N و S معروضان). لاحظ أنه بالنسبة لم/n، يتم استبدال RepBlocks بـ CSPStackRep. (ب) هيكل وحدة BiC. (ج) مكون SimCSPSPPF. ([المصدر](https://arxiv.org/pdf/2301.05586.pdf)).
|
||||
|
||||
### ميزات رئيسية
|
||||
|
||||
- **وحدة Bi-directional Concatenation (BiC):** يقدم YOLOv6 وحدة BiC في الرقبة التابعة للكاشف، مما يعزز إشارات التحديد المحلية ويؤدي إلى زيادة الأداء دون التأثير على السرعة.
|
||||
- **استراتيجية التدريب بمساعدة العناصر (AAT):** يقدم هذا النموذج استراتيجية AAT للاستفادة من فوائد النماذج المستندة إلى العناصر وغير المستندة إليها دون التضحية في كفاءة الاستدلال.
|
||||
- **تصميم أساس ورقبة محسّن:** من خلال تعميق YOLOv6 لتشمل مرحلة أخرى في الأساس والرقبة، يحقق هذا النموذج أداءً يفوق جميع النماذج الأخرى على مجموعة بيانات COCO لإدخال عالي الدقة.
|
||||
- **استراتيجية الاستنباط الذاتي:** يتم تنفيذ استراتيجية استنتاج ذاتي جديدة لتعزيز أداء النماذج الصغيرة من YOLOv6، وذلك عن طريق تعزيز فرع الانحدار المساعد خلال التدريب وإزالته في الاستنتاج لتجنب انخفاض السرعة الواضح.
|
||||
|
||||
## معايير الأداء
|
||||
|
||||
يوفر YOLOv6 مجموعة متنوعة من النماذج المدرّبة مسبقًا بمقاييس مختلفة:
|
||||
|
||||
- YOLOv6-N: ٣٧.٥٪ AP في COCO val2017 عندما يتم استخدام بطاقة NVIDIA Tesla T4 GPU وسرعة ١١٨٧ إطار في الثانية.
|
||||
- YOLOv6-S: ٤٥.٠٪ AP وسرعة ٤٨٤ إطار في الثانية.
|
||||
- YOLOv6-M: ٥٠.٠٪ AP وسرعة ٢٢٦ إطار في الثانية.
|
||||
- YOLOv6-L: ٥٢.٨٪ AP وسرعة ١١٦ إطار في الثانية.
|
||||
- YOLOv6-L6: دقة حديثة في الزمن الحقيقي.
|
||||
|
||||
كما يوفر YOLOv6 نماذج مؤنقة (quantized models) بدقات مختلفة ونماذج محسنة للمنصات المحمولة.
|
||||
|
||||
## أمثلة عن الاستخدام
|
||||
|
||||
يقدم هذا المثال أمثلة بسيطة لتدريب YOLOv6 واستنتاجه. للحصول على وثائق كاملة حول هذه وأوضاع أخرى [انظر](../modes/index.md) الى الصفحات التوضيحية لتوسعة الوثائق الفائقة ، [توقع](../modes/predict.md) ، [تدريب](../modes/train.md) ، [التحقق](../modes/val.md) و [التصدير](../modes/export.md).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
يمكن تمرير النماذج المدرّبة مسبقًا بتنسيق `*.pt` في PyTorch وملفات التكوين `*.yaml` لفئة `YOLO()` لإنشاء نموذج في Python:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# إنشاء نموذج YOLOv6n من البداية
|
||||
model = YOLO('yolov6n.yaml')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تدريب النموذج على مجموعة بيانات مثال COCO8 لمدة 100 دورة تدريب
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# تشغيل الاستنتاج بنموذج YOLOv6n على صورة 'bus.jpg'
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
يمكن استخدام أوامر CLI لتشغيل النماذج مباشرةً:
|
||||
|
||||
```bash
|
||||
# إنشاء نموذج YOLOv6n من البداية وتدريبه باستخدام مجموعة بيانات مثال COCO8 لمدة 100 دورة تدريب
|
||||
yolo train model=yolov6n.yaml data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# إنشاء نموذج YOLOv6n من البداية وتشغيل الاستنتاج على صورة 'bus.jpg'
|
||||
yolo predict model=yolov6n.yaml source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## المهام والأوضاع المدعومة
|
||||
|
||||
تقدم سلسلة YOLOv6 مجموعة من النماذج، والتي تم تحسينها للكشف عن الكائنات عالي الأداء. تلبي هذه النماذج احتياجات الكمبيوتيشن المتنوعة ومتطلبات الدقة، مما يجعلها متعددة الاستخدامات في مجموعة واسعة من التطبيقات.
|
||||
|
||||
| نوع النموذج | الأوزان المدربة مسبقًا | المهام المدعومة | الاستنتاج | التحقق | التدريب | التصدير |
|
||||
|-------------|------------------------|-----------------------------------------|-----------|--------|---------|---------|
|
||||
| YOLOv6-N | `yolov6-n.pt` | [الكشف عن الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-S | `yolov6-s.pt` | [الكشف عن الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-M | `yolov6-m.pt` | [الكشف عن الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-L | `yolov6-l.pt` | [الكشف عن الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-L6 | `yolov6-l6.pt` | [الكشف عن الكائنات](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
توفر هذه الجدول نظرة عامة مفصلة على النماذج المختلفة لـ YOLOv6، مع تسليط الضوء على قدراتها في مهام الكشف عن الكائنات وتوافقها مع الأوضاع التشغيلية المختلفة مثل [الاستنتاج](../modes/predict.md) و [التحقق](../modes/val.md) و [التدريب](../modes/train.md) و [التصدير](../modes/export.md). هذا الدعم الشامل يضمن أن يمكن للمستخدمين الاستفادة الكاملة من قدرات نماذج YOLOv6 في مجموعة واسعة من سيناريوهات الكشف عن الكائنات.
|
||||
|
||||
## الاقتباسات والتقديرات
|
||||
|
||||
نحن نود أن نقدّم الشكر للمؤلفين على مساهماتهم الهامة في مجال كشف الكائنات في الوقت الحقيقي:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{li2023yolov6,
|
||||
title={YOLOv6 v3.0: A Full-Scale Reloading},
|
||||
author={Chuyi Li and Lulu Li and Yifei Geng and Hongliang Jiang and Meng Cheng and Bo Zhang and Zaidan Ke and Xiaoming Xu and Xiangxiang Chu},
|
||||
year={2023},
|
||||
eprint={2301.05586},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
يمكن العثور على الورقة الأصلية لـ YOLOv6 على [arXiv](https://arxiv.org/abs/2301.05586). نشر المؤلفون عملهم بشكل عام، ويمكن الوصول إلى الشيفرة المصدرية على [GitHub](https://github.com/meituan/YOLOv6). نحن نقدّر جهودهم في تطوير هذا المجال وجعل عملهم متاحًا للمجتمع بأسره.
|
||||
|
|
@ -1,66 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف YOLOv7 ، جهاز كشف الكائنات في الوقت الحقيقي. تعرف على سرعته الفائقة، ودقته المذهلة، وتركيزه الفريد على تحسين الأمتعة التدريبية تدريبياً.
|
||||
keywords: YOLOv7، كاشف الكائنات في الوقت الحقيقي، الحالة الفنية، Ultralytics، مجموعة بيانات MS COCO، المعيار المعاد تعريفه للنموذج، التسمية الديناميكية، التحجيم الموسع، التحجيم المركب
|
||||
---
|
||||
|
||||
# YOLOv7: حقيبة مجانية قابلة للتدريب
|
||||
|
||||
YOLOv7 هو كاشف الكائنات في الوقت الحقيقي الحديث الحالي الذي يتفوق على جميع كاشفات الكائنات المعروفة من حيث السرعة والدقة في النطاق من 5 إطارات في الثانية إلى 160 إطارًا في الثانية. إنه يتمتع بأعلى دقة (٥٦.٨٪ AP) بين جميع كاشفات الكائنات الحالية في الوقت الحقيقي بسرعة ٣٠ إطارًا في الثانية أو أعلى على GPU V100. علاوة على ذلك, يتفوق YOLOv7 على كاشفات الكائنات الأخرى مثل YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5 والعديد من الآخرين من حيث السرعة والدقة. النموذج مدرب على مجموعة بيانات MS COCO من البداية دون استخدام أي مجموعات بيانات أخرى أو وزن مُعين مُسبقًا. رمز المصدر لـ YOLOv7 متاح على GitHub.
|
||||
|
||||

|
||||
|
||||
**مقارنة بين كاشفات الكائنات الأعلى الفنية.** من النتائج في الجدول 2 نتعرف على أن الطريقة المقترحة لديها أفضل توازن بين السرعة والدقة بشكل شامل. إذا قارنا بين YOLOv7-tiny-SiLU و YOLOv5-N (r6.1) ، يكون الطريقة الحالية أسرع بـ ١٢٧ إطارًا في الثانية وأكثر دقة بنسبة ١٠.٧٪ من حيث AP. بالإضافة إلى ذلك ، YOLOv7 لديها AP بنسبة ٥١.٤٪ في معدل إطار ١٦١ في الثانية ، في حين يكون لـ PPYOLOE-L نفس AP فقط بمعدل إطار ٧٨ في الثانية. من حيث استخدام العوامل ، يكون YOLOv7 أقل بنسبة ٤١٪ من العوامل مقارنةً بـ PPYOLOE-L. إذا قارنا YOLOv7-X بسرعة تواصل بيانات ١١٤ إطارًا في الثانية مع YOLOv5-L (r6.1) مع سرعة تحليل ٩٩ إطارًا في الثانية ، يمكن أن يحسن YOLOv7-X AP بمقدار ٣.٩٪. إذا قورن YOLOv7-X بــ YOLOv5-X (r6.1) بنفس الحجم ، فإن سرعة تواصل البيانات في YOLOv7-X تكون أسرع بـ ٣١ إطارًا في الثانية. بالإضافة إلى ذلك ، من حيث كمية المعاملات والحسابات ، يقلل YOLOv7-X بنسبة ٢٢٪ من المعاملات و٨٪ من الحساب مقارنةً بـ YOLOv5-X (r6.1) ، ولكنه يحسن AP بنسبة ٢.٢٪ ([المصدر](https://arxiv.org/pdf/2207.02696.pdf)).
|
||||
|
||||
## النظرة العامة
|
||||
|
||||
كاشف الكائنات في الوقت الحقيقي هو جزء مهم في العديد من أنظمة رؤية الحاسوب ، بما في ذلك التتبع متعدد الكائنات والقيادة التلقائية والروبوتات وتحليل صور الأعضاء. في السنوات الأخيرة ، تركز تطوير كاشفات الكائنات في الوقت الحقيقي على تصميم هياكل فعالة وتحسين سرعة التحليل لمعالجات الكمبيوتر المركزية ومعالجات الرسومات ووحدات معالجة الأعصاب (NPUs). يدعم YOLOv7 كلاً من GPU المحمول وأجهزة الـ GPU ، من الحواف إلى السحابة.
|
||||
|
||||
على عكس كاشفات الكائنات في الوقت الحقيقي التقليدية التي تركز على تحسين الهياكل ، يُقدم YOLOv7 تركيزًا على تحسين عملية التدريب. يتضمن ذلك وحدات وطرق تحسين تُصمم لتحسين دقة كشف الكائنات دون زيادة تكلفة التحليل ، وهو مفهوم يُعرف بـ "الحقيبة القابلة للتدريب للمجانيات".
|
||||
|
||||
## الميزات الرئيسية
|
||||
|
||||
تُقدم YOLOv7 عدة ميزات رئيسية:
|
||||
|
||||
1. **إعادة تعيين نموذج المعاملات**: يقترح YOLOv7 نموذج معاملات معين مخطط له ، وهو استراتيجية قابلة للتطبيق على الطبقات في شبكات مختلفة باستخدام مفهوم مسار انتشار التدرج.
|
||||
|
||||
2. **التسمية الديناميكية**: تدريب النموذج مع عدة طبقات إخراج يبرز قضية جديدة: "كيفية تعيين أهداف ديناميكية لإخراج الفروع المختلفة؟" لحل هذه المشكلة ، يقدم YOLOv7 طريقة تسمية جديدة تسمى تسمية الهدف المرشدة من الخشن إلى الدقيقة.
|
||||
|
||||
3. **التحجيم الموسع والمركب**: يقترح YOLOv7 طرق "التحجيم الموسع" و "التحجيم المركب" لكاشف الكائنات في الوقت الحقيقي التي يمكن أن تستخدم بشكل فعال في المعاملات والحسابات.
|
||||
|
||||
4. **الكفاءة**: يمكن للطريقة المقترحة بواسطة YOLOv7 تقليل بشكل فعال حوالي 40٪ من المعاملات و 50٪ من الحساب لكاشف الكائنات في الوقت الحقيقي الأولى من حيث الدقة والسرعة في التحليل.
|
||||
|
||||
## أمثلة على الاستخدام
|
||||
|
||||
في وقت كتابة هذا النص ، لا تدعم Ultralytics حاليًا نماذج YOLOv7. لذلك ، سيحتاج أي مستخدمين مهتمين باستخدام YOLOv7 إلى الرجوع مباشرة إلى مستودع YOLOv7 على GitHub للحصول على تعليمات التثبيت والاستخدام.
|
||||
|
||||
وفيما يلي نظرة عامة على الخطوات النموذجية التي يمكنك اتباعها لاستخدام YOLOv7:
|
||||
|
||||
1. قم بزيارة مستودع YOLOv7 على GitHub: [https://github.com/WongKinYiu/yolov7](https://github.com/WongKinYiu/yolov7).
|
||||
|
||||
2. اتبع التعليمات الموجودة في ملف README لعملية التثبيت. يتضمن ذلك عادةً استنساخ المستودع ، وتثبيت التبعيات اللازمة ، وإعداد أي متغيرات بيئة ضرورية.
|
||||
|
||||
3. بمجرد الانتهاء من عملية التثبيت ، يمكنك تدريب النموذج واستخدامه وفقًا لتعليمات الاستخدام الموجودة في المستودع. ينطوي ذلك عادةً على إعداد مجموعة البيانات الخاصة بك ، وتكوين معلمات النموذج ، وتدريب النموذج ، ثم استخدام النموذج المدرب لأداء كشف الكائنات.
|
||||
|
||||
يرجى ملاحظة أن الخطوات المحددة قد تختلف اعتمادًا على حالة الاستخدام الخاصة بك والحالة الحالية لمستودع YOLOv7. لذا ، يُوصى بشدة بالرجوع مباشرة إلى التعليمات المقدمة في مستودع YOLOv7 على GitHub.
|
||||
|
||||
نأسف على أي إزعاج قد يسببه ذلك وسنسعى لتحديث هذا المستند بأمثلة على الاستخدام لـ Ultralytics عندما يتم تنفيذ الدعم لـ YOLOv7.
|
||||
|
||||
## الاقتباسات والشكر
|
||||
|
||||
نود أن نشكر كتاب YOLOv7 على مساهماتهم الهامة في مجال اكتشاف الكائنات في الوقت الحقيقي:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{wang2022yolov7,
|
||||
title={{YOLOv7}: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors},
|
||||
author={Wang, Chien-Yao and Bochkovskiy, Alexey and Liao, Hong-Yuan Mark},
|
||||
journal={arXiv preprint arXiv:2207.02696},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
|
||||
يمكن العثور على ورقة YOLOv7 الأصلية على [arXiv](https://arxiv.org/pdf/2207.02696.pdf). قدم الكتاب عملهم علنياً، ويمكن الوصول إلى قاعدة الشيفرة على [GitHub](https://github.com/WongKinYiu/yolov7). نحن نقدر جهودهم في تقدم المجال وتوفير عملهم للمجتمع بشكل عام.
|
||||
|
|
@ -1,166 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف الميزات المثيرة لـ YOLOv8 ، أحدث إصدار من مكتشف الكائنات الحية الخاص بنا في الوقت الحقيقي! تعرّف على العمارات المتقدمة والنماذج المدرّبة مسبقًا والتوازن المثلى بين الدقة والسرعة التي تجعل YOLOv8 الخيار المثالي لمهام الكشف عن الكائنات الخاصة بك.
|
||||
keywords: YOLOv8, Ultralytics, مكتشف الكائنات الحية الخاص بنا في الوقت الحقيقي, النماذج المدرّبة مسبقًا, وثائق, الكشف عن الكائنات, سلسلة YOLO, العمارات المتقدمة, الدقة, السرعة
|
||||
---
|
||||
|
||||
# YOLOv8
|
||||
|
||||
## نظرة عامة
|
||||
|
||||
YOLOv8 هو التطور الأخير في سلسلة YOLO لمكتشفات الكائنات الحية الخاصة بنا في الوقت الحقيقي ، والذي يقدم أداءً متقدمًا في مجال الدقة والسرعة. بناءً على التقدمات التي تم إحرازها في إصدارات YOLO السابقة ، يقدم YOLOv8 ميزات وتحسينات جديدة تجعله الخيار المثالي لمهام الكشف عن الكائنات في مجموعة واسعة من التطبيقات.
|
||||
|
||||

|
||||
|
||||
## الميزات الرئيسية
|
||||
|
||||
- **العمارات المتقدمة للظهر والعنق:** يعتمد YOLOv8 على عمارات الظهر والعنق على أحدث طراز ، مما يؤدي إلى تحسين استخراج الميزات وأداء الكشف عن الكائنات.
|
||||
- **Ultralytics Head بدون إثبات خطافي:** يعتمد YOLOv8 على Ultralytics Head بدون إثبات خطافي ، مما يسهم في زيادة الدقة وتوفير وقت مكشف أكثر كفاءة مقارنةً بالطرق التي تعتمد على الإثبات.
|
||||
- **توازن مثالي بين الدقة والسرعة محسَّن:** بتركيزه على الحفاظ على توازن مثالي بين الدقة والسرعة ، فإن YOLOv8 مناسب لمهام الكشف عن الكائنات في الوقت الحقيقي في مجموعة متنوعة من المجالات التطبيقية.
|
||||
- **تشكيلة من النماذج المدرّبة مسبقًا:** يقدم YOLOv8 مجموعة من النماذج المدرّبة مسبقًا لتلبية متطلبات المهام المختلفة ومتطلبات الأداء ، مما يجعل من السهل إيجاد النموذج المناسب لحالتك الاستخدامية الخاصة.
|
||||
|
||||
## المهام والأوضاع المدعومة
|
||||
|
||||
تقدم سلسلة YOLOv8 مجموعة متنوعة من النماذج ، يتم تخصيص كلًا منها للمهام المحددة في رؤية الحاسوب. تم تصميم هذه النماذج لتلبية متطلبات مختلفة ، بدءًا من الكشف عن الكائنات إلى مهام أكثر تعقيدًا مثل تقسيم الصور إلى أجزاء واكتشاف نقاط المفاتيح والتصنيف.
|
||||
|
||||
تمت تحسين كل نوع من سلسلة YOLOv8 للمهام التي تخصها ، مما يضمن أداء ودقة عاليين. بالإضافة إلى ذلك ، تتوافق هذه النماذج مع أوضاع تشغيل مختلفة بما في ذلك [الاستدلال](../modes/predict.md) ، [التحقق](../modes/val.md) ، [التدريب](../modes/train.md) و [التصدير](../modes/export.md) ، مما يسهل استخدامها في مراحل مختلفة من عملية التطوير والتنفيذ.
|
||||
|
||||
| النموذج | أسماء الملف | المهمة | استدلال | التحقق | التدريب | التصدير |
|
||||
|-------------|----------------------------------------------------------------------------------------------------------------|----------------------------------------------|---------|--------|---------|---------|
|
||||
| YOLOv8 | `yolov8n.pt` `yolov8s.pt` `yolov8m.pt` `yolov8l.pt` `yolov8x.pt` | [الكشف](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv8-seg | `yolov8n-seg.pt` `yolov8s-seg.pt` `yolov8m-seg.pt` `yolov8l-seg.pt` `yolov8x-seg.pt` | [تقسيم الصور إلى أجزاء](../tasks/segment.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv8-pose | `yolov8n-pose.pt` `yolov8s-pose.pt` `yolov8m-pose.pt` `yolov8l-pose.pt` `yolov8x-pose.pt` `yolov8x-pose-p6.pt` | [المواقق/نقاط المفاتيح](../tasks/pose.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv8-cls | `yolov8n-cls.pt` `yolov8s-cls.pt` `yolov8m-cls.pt` `yolov8l-cls.pt` `yolov8x-cls.pt` | [التصنيف](../tasks/classify.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
توفر هذه الجدولة نظرة عامة على متغيرات نموذج YOLOv8 ، مما يسلط الضوء على قابليتها للتطبيق في مهام محددة وتوافقها مع أوضاع تشغيل مختلفة مثل الاستدلال والتحقق والتدريب والتصدير. يعرض مرونة وقوة سلسلة YOLOv8 ، مما يجعلها مناسبة لمجموعة متنوعة من التطبيقات في رؤية الحاسوب.
|
||||
|
||||
## مقاييس الأداء
|
||||
|
||||
!!! الأداء
|
||||
|
||||
=== "الكشف (COCO)"
|
||||
|
||||
انظر إلى [وثائق الكشف](https://docs.ultralytics.com/tasks/detect/) لأمثلة عن الاستخدام مع هذه النماذج المدربة مسبقًا على [COCO](https://docs.ultralytics.com/datasets/detect/coco/) ، التي تضم 80 فئة مدربة مسبقًا.
|
||||
|
||||
| النموذج | حجم<br><sup>(بيكسل) | معدل الكشف<sup>التحقق<br>50-95 | سرعة<br><sup>CPU ONNX<br>(متوسط) | سرعة<br><sup>A100 TensorRT<br>(متوسط) | معلمات<br><sup>(مليون) | FLOPs<br><sup>(مليون) |
|
||||
| ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
|
||||
|
||||
=== "الكشف (صور مفتوحة V7)"
|
||||
|
||||
انظر إلى [وثائق الكشف](https://docs.ultralytics.com/tasks/detect/) لأمثلة عن الاستخدام مع هذه النماذج المدربة مسبقًا على [Open Image V7](https://docs.ultralytics.com/datasets/detect/open-images-v7/)، والتي تضم 600 فئة مدربة مسبقًا.
|
||||
|
||||
| النموذج | حجم<br><sup>(بيكسل) | معدل الكشف<sup>التحقق<br>50-95 | سرعة<br><sup>CPU ONNX<br>(متوسط) | سرعة<br><sup>A100 TensorRT<br>(متوسط) | معلمات<br><sup>(مليون) | FLOPs<br><sup>(مليون) |
|
||||
| ----------------------------------------------------------------------------------------- | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
|
||||
|
||||
=== "تقسيم الصور إلى أجزاء (COCO)"
|
||||
|
||||
انظر إلى [وثائق التقسيم](https://docs.ultralytics.com/tasks/segment/) لأمثلة عن الاستخدام مع هذه النماذج المدرّبة مسبقًا على [COCO](https://docs.ultralytics.com/datasets/segment/coco/)، والتي تضم 80 فئة مدربة مسبقًا.
|
||||
|
||||
| النموذج | حجم<br><sup>(بيكسل) | معدل التقسيم<sup>التحقق<br>50-95 | معدل التقسيم<sup>الأقنعة<br>50-95 | سرعة<br><sup>CPU ONNX<br>(متوسط) | سرعة<br><sup>A100 TensorRT<br>(متوسط) | معلمات<br><sup>(مليون) | FLOPs<br><sup>(مليون) |
|
||||
| -------------------------------------------------------------------------------------------- | --------------------- | -------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
|
||||
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
|
||||
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
|
||||
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
|
||||
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
|
||||
|
||||
=== "التصنيف (ImageNet)"
|
||||
|
||||
انظر إلى [وثائق التصنيف](https://docs.ultralytics.com/tasks/classify/) لأمثلة عن الاستخدام مع هذه النماذج المدرّبة مسبقًا على [ImageNet](https://docs.ultralytics.com/datasets/classify/imagenet/)، والتي تضم 1000 فئة مدربة مسبقًا.
|
||||
|
||||
| النموذج | حجم<br><sup>(بيكسل) | دقة أعلى<br><sup>أعلى 1 | دقة أعلى<br><sup>أعلى 5 | سرعة<br><sup>CPU ONNX<br>(متوسط) | سرعة<br><sup>A100 TensorRT<br>(متوسط) | معلمات<br><sup>(مليون) | FLOPs<br><sup>(مليون) عند 640 |
|
||||
| -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ------------------------------ | ----------------------------------- | ------------------ | ------------------------ |
|
||||
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
|
||||
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
|
||||
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
|
||||
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
|
||||
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
|
||||
|
||||
=== "المواقف (COCO)"
|
||||
|
||||
انظر إلى [وثائق تقدير المواقع] (https://docs.ultralytics.com/tasks/pose/) لأمثلة على الاستخدام مع هذه النماذج المدربة مسبقًا على [COCO](https://docs.ultralytics.com/datasets/pose/coco/)، والتي تتضمن فئة واحدة مدربة مسبقًا ، 'شخص'.
|
||||
|
||||
| النموذج | حجم<br><sup>(بيكسل) | معدل التوضيح<sup>التحقق<br>50-95 | معدل التوضيح<sup>50 | سرعة<br><sup>CPU ONNX<br>(متوسط) | سرعة<br><sup>A100 TensorRT<br>(متوسط) | معلمات<br><sup>(مليون) | FLOPs<br><sup>(مليون) |
|
||||
| ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
|
||||
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
|
||||
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
|
||||
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
|
||||
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
|
||||
|
||||
## أمثلة استخدام
|
||||
|
||||
يوفر هذا المثال أمثلة بسيطة للتدريب والتنبؤ باستخدام YOLOv8. للحصول على وثائق كاملة حول هذه وغيرها من [الأوضاع](../modes/index.md) ، انظر إلى صفحات وثائق [تنبؤ](../modes/predict.md) ، [تدريب](../modes/train.md) ، [التحقق](../modes/val.md) و [التصدير](../modes/export.md) .
|
||||
|
||||
يرجى ملاحظة أن المثال أدناه يتعلق بطراز YOLOv8 [Detect](../tasks/detect.md) للكشف عن الكائنات. لمهام مدعومة إضافية ، انظر إلى وثائق [تقسيم](../tasks/segment.md) ، [تحديد إنتماء](../tasks/classify.md) و [تصوير (Pose)](../tasks/pose.md) .
|
||||
|
||||
!!!
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
يمكن تمرير نماذج الـ PyTorch المُدرّبة المُحفوظة بالامتداد `*.pt` بالإضافة إلى ملفات التكوين بامتداد `*.yaml` إلى فئة `YOLO()` لإنشاء نموذج في لغة بايثون:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرّب مسبقًا على COCO
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# عرض معلومات النموذج (اختياري)
|
||||
model.info()
|
||||
|
||||
# تدريب النموذج على مجموعة بيانات المُدخلات coco8 على سبيل المثال لمدة 100 دورة
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# تشغيل التنبؤ باستخدام نموذج YOLOv8n على صورة 'bus.jpg'
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
تتوفر أوامر CLI لتشغيل النماذج مباشرة:
|
||||
|
||||
```bash
|
||||
# تحميل نموذج YOLOv8n المدرّب مسبقًا على COCO واختباره على مجموعة بيانات coco8
|
||||
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرّب مسبقًا على COCO والتنبؤ به على صورة 'bus.jpg'
|
||||
yolo predict model=yolov8n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## الاقتباسات والتقديرات
|
||||
|
||||
إذا استخدمت نموذج YOLOv8 أو أي برنامج آخر من هذا المستودع في عملك ، فيرجى استشهاده باستخدام التنسيق التالي:
|
||||
|
||||
!!!،
|
||||
|
||||
!!! quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@software{yolov8_ultralytics,
|
||||
author = {Glenn Jocher and Ayush Chaurasia and Jing Qiu},
|
||||
title = {Ultralytics YOLOv8},
|
||||
version = {8.0.0},
|
||||
year = {2023},
|
||||
url = {https://github.com/ultralytics/ultralytics},
|
||||
orcid = {0000-0001-5950-6979, 0000-0002-7603-6750, 0000-0003-3783-7069},
|
||||
license = {AGPL-3.0}
|
||||
}
|
||||
```
|
||||
|
||||
يرجى ملاحظة أن وجود معرف الكائن الرقمي (DOI) قيد الانتظار وسيتم إضافته إلى الاقتباس بمجرد توفره. تُقدم نماذج YOLOv8 بموجب [رخصة AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) و [الرخصة المؤسسية](https://ultralytics.com/license).
|
||||
|
|
@ -1,94 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعرف على كيفية قياس سرعة ودقة YOLOv8 عبر تنسيقات التصدير المختلفة. احصل على رؤى حول مقاييس mAP50-95 وaccuracy_top5 والمزيد.
|
||||
keywords: Ultralytics، YOLOv8، اختبار الأداء، قياس السرعة، قياس الدقة، مقاييس mAP50-95 وaccuracy_top5، ONNX، OpenVINO، TensorRT، تنسيقات تصدير YOLO
|
||||
---
|
||||
|
||||
# اختبار النموذج باستخدام Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO ecosystem and integrations">
|
||||
|
||||
## المقدمة
|
||||
|
||||
بمجرد أن يتم تدريب نموذجك وتحقق صحته ، فإن الخطوة التالية بشكل منطقي هي تقييم أدائه في سيناريوهات العالم الحقيقي المختلفة. يوفر وضع الاختبار في Ultralytics YOLOv8 هذا الهدف من خلال توفير إطار قوي لتقييم سرعة ودقة النموذج عبر مجموعة من صيغ التصدير.
|
||||
|
||||
## لماذا هو اختبار الأداء مهم؟
|
||||
|
||||
- **قرارات مستنيرة:** اكتساب رؤى حول التنازلات بين السرعة والدقة.
|
||||
- **تخصيص الموارد:** فهم كيفية أداء تنسيقات التصدير المختلفة على أجهزة مختلفة.
|
||||
- **تحسين:** تعلم أي تنسيق تصدير يقدم أفضل أداء لحالتك الاستخدامية المحددة.
|
||||
- **كفاءة التكلفة:** استخدام الموارد الأجهزة بشكل أكثر كفاءة بناءً على نتائج الاختبار.
|
||||
|
||||
### المقاييس الرئيسية في وضع الاختبار
|
||||
|
||||
- **mAP50-95:** لكشف الكائنات وتقسيمها وتحديد الوضع.
|
||||
- **accuracy_top5:** لتصنيف الصور.
|
||||
- **وقت التتبع:** الوقت المستغرق لكل صورة بالميلي ثانية.
|
||||
|
||||
### تنسيقات التصدير المدعومة
|
||||
|
||||
- **ONNX:** لأفضل أداء على وحدة المعالجة المركزية.
|
||||
- **TensorRT:** لأقصى استفادة من وحدة المعالجة الرسومية.
|
||||
- **OpenVINO:** لتحسين الأجهزة من إنتل.
|
||||
- **CoreML و TensorFlow SavedModel وما إلى ذلك:** لتلبية احتياجات النشر المتنوعة.
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
* قم بتصدير إلى نموذج ONNX أو OpenVINO لزيادة سرعة وحدة المعالجة المركزية بمقدار 3 مرات.
|
||||
* قم بتصدير إلى نموذج TensorRT لزيادة سرعة وحدة المعالجة الرسومية بمقدار 5 مرات.
|
||||
|
||||
## أمثلة على الاستخدام
|
||||
|
||||
قم بتشغيل اختبارات YOLOv8n على جميع تنسيقات التصدير المدعومة بما في ذلك ONNX و TensorRT وما إلى ذلك. انظر القسم الموجود أدناه للحصول على قائمة كاملة من وسيطات التصدير.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics.utils.benchmarks import benchmark
|
||||
|
||||
# اختبار على وحدة المعالجة الرسومية
|
||||
benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
|
||||
```
|
||||
|
||||
## وسيطات
|
||||
|
||||
توفر الوسائط مثل `model` و `data` و `imgsz` و `half` و `device` و `verbose` مرونة للمستخدمين لضبط الاختبارات حسب احتياجاتهم المحددة ومقارنة أداء تنسيقات التصدير المختلفة بسهولة.
|
||||
|
||||
| المفتاح | القيمة | الوصف |
|
||||
|-----------|---------|---------------------------------------------------------------------------------------------------|
|
||||
| `model` | `None` | مسار إلى ملف النموذج ، على سبيل المثال yolov8n.pt ، yolov8n.yaml |
|
||||
| `data` | `None` | مسار إلى YAML يشير إلى مجموعة بيانات اختبار الأداء (بتحتوى على بيانات `val`) |
|
||||
| `imgsz` | `640` | حجم الصورة كرقم ، أو قائمة (h ، w) ، على سبيل المثال (640، 480) |
|
||||
| `half` | `False` | تقليل دقة العدد العشرى للأبعاد (FP16 quantization) |
|
||||
| `int8` | `False` | تقليل دقة العدد الصحيح 8 بت (INT8 quantization) |
|
||||
| `device` | `None` | الجهاز الذى ستعمل عليه العملية ، على سبيل المثال cuda device=0 أو device=0,1,2,3 أو device=cpu |
|
||||
| `verbose` | `False` | عدم المتابعة عند حدوث خطأ (مقدار منطقى)، أو مستوى الكشف عند تجاوز حد القيمة المطلوبة (قيمة عائمة) |
|
||||
|
||||
## صيغ التصدير
|
||||
|
||||
سيحاول التطبيق تشغيل الاختبارات تلقائيًا على جميع صيغ التصدير الممكنة الموجودة أدناه.
|
||||
|
||||
| Format | `format` Argument | Model | Metadata | Arguments |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras`, `int8` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
انظر تفاصيل التصدير الكاملة في الصفحة [Export](https://docs.ultralytics.com/modes/export/)
|
||||
|
|
@ -1,108 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: دليل خطوة بخطوة حول تصدير نماذج YOLOv8 الخاصة بك إلى تنسيقات مختلفة مثل ONNX و TensorRT و CoreML وغيرها للنشر. استكشف الآن!.
|
||||
keywords: YOLO، YOLOv8، Ultralytics، تصدير النموذج، ONNX، TensorRT، CoreML، TensorFlow SavedModel، OpenVINO، PyTorch، تصدير النموذج
|
||||
---
|
||||
|
||||
# تصدير النموذج باستخدام يولو من Ultralytics
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="إكوسيستم يولو من Ultralytics والتكاملات">
|
||||
|
||||
## مقدمة
|
||||
|
||||
الهدف النهائي لتدريب نموذج هو نشره لتطبيقات العالم الحقيقي. يوفر وضع التصدير في يولو من Ultralytics مجموعة متنوعة من الخيارات لتصدير النموذج المدرب إلى تنسيقات مختلفة، مما يجعله يمكن استخدامه في مختلف الأنظمة والأجهزة. يهدف هذا الدليل الشامل إلى مساعدتك في فهم تفاصيل تصدير النموذج، ويعرض كيفية تحقيق أقصى توافق وأداء.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/WbomGeoOT_k?si=aGmuyooWftA0ue9X"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> كيفية تصدير نموذج Ultralytics YOLOv8 التدريب المخصص وتشغيل الاستدلال المباشر على كاميرا الويب.
|
||||
</p>
|
||||
|
||||
## لماذا اختيار وضع تصدير YOLOv8؟
|
||||
|
||||
- **التنوع:** تصدير إلى تنسيقات متعددة بما في ذلك ONNX و TensorRT و CoreML ، وغيرها.
|
||||
- **الأداء:** الحصول على سرعة تسريع تصل إلى 5 أضعاف باستخدام TensorRT وسرعة تسريع معالج الكمبيوتر المركزي بنسبة 3 أضعاف باستخدام ONNX أو OpenVINO.
|
||||
- **التوافقية:** جعل النموذج قابلاً للنشر على الأجهزة والبرامج المختلفة.
|
||||
- **سهولة الاستخدام:** واجهة سطر الأوامر البسيطة وواجهة برمجة Python لتصدير النموذج بسرعة وسهولة.
|
||||
|
||||
### الميزات الرئيسية لوضع التصدير
|
||||
|
||||
إليك بعض من الميزات المميزة:
|
||||
|
||||
- **تصدير بنقرة واحدة:** أوامر بسيطة لتصدير إلى تنسيقات مختلفة.
|
||||
- **تصدير الدُفعات:** تصدير نماذج قادرة على العمل مع الدُفعات.
|
||||
- **تنفيذ محسَّن:** يتم تحسين النماذج المصدرة لتوفير وقت تنفيذ أسرع.
|
||||
- **فيديوهات تعليمية:** مرشدين وفيديوهات تعليمية لتجربة تصدير سلسة.
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
* صدّر إلى ONNX أو OpenVINO للحصول على تسريع معالج الكمبيوتر المركزي بنسبة 3 أضعاف.
|
||||
* صدّر إلى TensorRT للحصول على تسريع وحدة المعالجة الرسومية بنسبة 5 أضعاف.
|
||||
|
||||
## أمثلة للاستخدام
|
||||
|
||||
قم بتصدير نموذج YOLOv8n إلى تنسيق مختلف مثل ONNX أو TensorRT. انظر الجدول أدناه للحصول على قائمة كاملة من وسائط التصدير.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "بايثون"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل نموذج
|
||||
model = YOLO('yolov8n.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مدرب مخصص
|
||||
|
||||
# قم بتصدير النموذج
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "واجهة سطر الأوامر"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # تصدير نموذج رسمي
|
||||
yolo export model=path/to/best.pt format=onnx # تصدير نموذج مدرب مخصص
|
||||
```
|
||||
|
||||
## الوسائط
|
||||
|
||||
تشير إعدادات تصدير YOLO إلى التكوينات والخيارات المختلفة المستخدمة لحفظ أو تصدير النموذج للاستخدام في بيئات أو منصات أخرى. يمكن أن تؤثر هذه الإعدادات على أداء النموذج وحجمه وتوافقه مع الأنظمة المختلفة. تشمل بعض إعدادات تصدير YOLO الشائعة تنسيق ملف النموذج المصدر (مثل ONNX وتنسيق TensorFlow SavedModel) والجهاز الذي سيتم تشغيل النموذج عليه (مثل المعالج المركزي أو وحدة المعالجة الرسومية) ووجود ميزات إضافية مثل الأقنعة أو التسميات المتعددة لكل مربع. قد تؤثر عوامل أخرى قد تؤثر عملية التصدير تشمل المهمة النموذجة المحددة التي يتم استخدام النموذج لها ومتطلبات أو قيود البيئة أو المنصة المستهدفة. من المهم أن ننظر بعناية ونقوم بتكوين هذه الإعدادات لضمان أن النموذج المصدر هو محسَّن للحالة الاستخدام المقصودة ويمكن استخدامه بشكل فعال في البيئة المستهدفة.
|
||||
|
||||
| المفتاح | القيمة | الوصف |
|
||||
|-------------|-----------------|-----------------------------------------------------------------------|
|
||||
| `format` | `'torchscript'` | التنسيق المراد تصديره |
|
||||
| `imgsz` | `640` | حجم الصورة كمقدار علمي أو قائمة (h ، w) ، على سبيل المثال (640 ، 480) |
|
||||
| `keras` | `False` | استخدام Keras لتصدير TF SavedModel |
|
||||
| `optimize` | `False` | TorchScript: الأمثل للجوال |
|
||||
| `half` | `False` | تكميم FP16 |
|
||||
| `int8` | `False` | تكميم INT8 |
|
||||
| `dynamic` | `False` | ONNX/TensorRT: المحاور الديناميكية |
|
||||
| `simplify` | `False` | ONNX/TensorRT: تبسيط النموذج |
|
||||
| `opset` | `None` | ONNX: إصدار opset (اختياري ، الافتراضي هو الأحدث) |
|
||||
| `workspace` | `4` | TensorRT: حجم مساحة العمل (GB) |
|
||||
| `nms` | `False` | CoreML: إضافة NMS |
|
||||
|
||||
## تنسيقات التصدير
|
||||
|
||||
صيغ تصدير YOLOv8 المتاحة في الجدول أدناه. يمكنك التصدير إلى أي تنسيق باستخدام الوسيطة `format` ، مثل `format='onnx'` أو `format='engine'`.
|
||||
|
||||
| التنسيق | وسيطة format | النموذج | البيانات الوصفية | الوسائط |
|
||||
|--------------------------------------------------------------------|---------------|---------------------------|------------------|-----------------------------------------------------|
|
||||
| [بايثورش](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `تورتشسيريبت` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras`, `int8` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
|
@ -1,77 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: من التدريب إلى التتبع، استفد من YOLOv8 مع Ultralytics. احصل على نصائح وأمثلة لكل وضع مدعوم بما في ذلك التحقق والتصدير واختبار الأداء.
|
||||
keywords: Ultralytics, YOLOv8, التعلم الآلي، كشف الكائنات، التدريب، التحقق، التنبؤ، التصدير، التتبع، اختبار الأداء
|
||||
---
|
||||
|
||||
# أوضاع Ultralytics YOLOv8
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="بيئة عمل Ultralytics YOLO والتكاملات">
|
||||
|
||||
## المقدمة
|
||||
|
||||
YOLOv8 من Ultralytics ليست مجرد نموذج لكشف الكائنات آخر؛ إنها إطار متعدد الاستخدامات مصمم لتغطية دورة حياة نماذج التعلم الآلي بأكملها - من امتصاص البيانات وتدريب النموذج إلى التحقق والنشر وتتبع الواقع الحقيقي. يخدم كل وضع غرضًا محددًا وهو مصمم لتوفير المرونة والكفاءة المطلوبة للمهام والحالات الاستخدام المختلفة.
|
||||
|
||||
!!! Note "ملاحظة"
|
||||
|
||||
🚧 توثيقنا متعدد اللغات قيد الإنشاء حاليًا، ونحن نعمل بجهد لتحسينه. شكرًا لك على صبرك! 🙏
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/j8uQc0qB91s?si=dhnGKgqvs7nPgeaM"
|
||||
title="مشغل فيديو يوتيوب" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> برنامج التعليم Ultralytics: تدريب، التحقق، التنبؤ، التصدير، واختبار الأداء.
|
||||
</p>
|
||||
|
||||
### أوضاع مختصرة
|
||||
|
||||
فهم ال**أوضاع** المختلفة المدعومة بواسطة Ultralytics YOLOv8 مهم جدًا للاستفادة القصوى من النماذج الخاصة بك:
|
||||
|
||||
- وضع **التدريب**: قم بضبط نموذجك على مجموعة بيانات مخصصة أو محملة مسبقًا.
|
||||
- وضع **التحقق**: نقطة فحص بعد التدريب لتقييم أداء النموذج.
|
||||
- وضع **التنبؤ**: اطلق قوة التنبؤ الخاصة بنموذجك على البيانات الحقيقية.
|
||||
- وضع **التصدير**: قم بتجهيز نموذجك للاستخدام في صيغ مختلفة.
|
||||
- وضع **التتبع**: قم بتوسيع نموذج الكشف عن الكائنات الخاص بك إلى تطبيقات التتبع في الوقت الحقيقي.
|
||||
- وضع **اختبار الأداء**: قم بتحليل سرعة ودقة نموذجك في بيئات نشر متنوعة.
|
||||
|
||||
يهدف هذا الدليل الشامل إلى تقديم لمحة عامة ونصائح عملية حول كل وضع، لمساعدتك في استغلال كامل إمكانات YOLOv8.
|
||||
|
||||
## [وضع التدريب](train.md)
|
||||
|
||||
يتم استخدام وضع التدريب لتدريب نموذج YOLOv8 على مجموعة بيانات مخصصة. في هذا الوضع، يتم تدريب النموذج باستخدام مجموعة البيانات والمعلمات الهايبر للحصول على دقة في توقع الفئات ومواقع الكائنات في الصورة.
|
||||
|
||||
[أمثلة التدريب](train.md){ .md-button }
|
||||
|
||||
## [وضع التحقق](val.md)
|
||||
|
||||
يتم استخدام وضع التحقق للتحقق من نموذج YOLOv8 بعد تدريبه. في هذا الوضع، يتم تقييم النموذج على مجموعة التحقق لقياس دقته وأداء التعميم. يمكن استخدام هذا الوضع لتعديل المعلمات الهايبر للنموذج لتحسين أدائه.
|
||||
|
||||
[أمثلة التحقق](val.md){ .md-button }
|
||||
|
||||
## [وضع التنبؤ](predict.md)
|
||||
|
||||
يتم استخدام وضع التنبؤ لإجراء تنبؤات باستخدام نموذج YOLOv8 المدرب على صور أو فيديوهات جديدة. في هذا الوضع، يتم تحميل النموذج من ملف الفحص، ويمكن للمستخدم توفير الصور أو مقاطع الفيديو لإجراء استدلال. يقوم النموذج بتوقع الفئات ومواقع الكائنات في الصور أو مقاطع الفيديو المدخلة.
|
||||
|
||||
[أمثلة التنبؤ](predict.md){ .md-button }
|
||||
|
||||
## [وضع التصدير](export.md)
|
||||
|
||||
يتم استخدام وضع التصدير لتصدير نموذج YOLOv8 إلى صيغة يمكن استخدامها للنشر. في هذا الوضع، يتم تحويل النموذج إلى صيغة يمكن استخدامها من قبل تطبيقات البرامج الأخرى أو الأجهزة الأجهزة. يكون هذا الوضع مفيدًا عند نشر النموذج في بيئات الإنتاج.
|
||||
|
||||
[أمثلة التصدير](export.md){ .md-button }
|
||||
|
||||
## [وضع التتبع](track.md)
|
||||
|
||||
يتم استخدام وضع التتبع لتتبع الكائنات في الوقت الحقيقي باستخدام نموذج YOLOv8. في هذا الوضع، يتم تحميل النموذج من ملف الفحص، ويمكن للمستخدم توفير تيار فيديو مباشر لأداء تتبع الكائنات في الوقت الفعلي. يكون هذا الوضع مفيدًا لتطبيقات مثل أنظمة المراقبة أو السيارات ذاتية القيادة.
|
||||
|
||||
[أمثلة التتبع](track.md){ .md-button }
|
||||
|
||||
## [وضع اختبار الأداء](benchmark.md)
|
||||
|
||||
يتم استخدام وضع اختبار الأداء لتقييم سرعة ودقة صيغ التصدير المختلفة لـ YOLOv8. تقدم الاختبارات معلومات حول حجم الصيغة المصدر، معيار الأداء `mAP50-95` (لكشف الكائنات والتقسيم والتصوير) أو المعيار `accuracy_top5` (للتصنيف)، ووقت الاستدلال بالملي ثانية لكل صورة في صيغ التصدير المختلفة مثل ONNX و OpenVINO و TensorRT وغيرها. يمكن لهذه المعلومات مساعدة المستخدمين على اختيار صيغة التصدير الأمثل لحالتهم الاستخدامية المحددة بناءً على متطلبات السرعة والدقة.
|
||||
|
||||
[أمثلة اختبار الأداء](benchmark.md){ .md-button }
|
||||
|
|
@ -1,217 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: اكتشف كيفية استخدام وضع التنبؤ YOLOv8 لمهام مختلفة. تعرّف على مصادر التنبؤ المختلفة مثل الصور ومقاطع الفيديو وتنسيقات البيانات المختلفة.
|
||||
keywords: Ultralytics، YOLOv8، وضع التنبؤ، مصادر التنبؤ، مهام التنبؤ، وضع التدفق، معالجة الصور، معالجة الفيديو، التعلم الآلي، الذكاء الاصطناعي
|
||||
---
|
||||
|
||||
# التنبؤ بالنموذج باستخدام Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="البيئة والتكامل الخاصة بنظام Ultralytics YOLO">
|
||||
|
||||
## المقدمة
|
||||
|
||||
في عالم التعلم الآلي ورؤية الحاسوب، يُطلق على عملية استخلاص المعنى من البيانات البصرية اسم "الاستدلال" أو "التنبؤ". يوفر YOLOv8 من Ultralytics ميزة قوية تُعرف بـ**وضع التنبؤ** والتي تم تصميمها خصيصًا للاستدلال في الوقت الحقيقي وبأداء عال على مجموعة واسعة من مصادر البيانات.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/QtsI0TnwDZs?si=ljesw75cMO2Eas14"
|
||||
title="مشغل الفيديو" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> كيفية استخراج النتائج من نموذج Ultralytics YOLOv8 لمشاريع مخصصة.
|
||||
</p>
|
||||
|
||||
## التطبيقات في العالم الحقيقي
|
||||
|
||||
| التصنيع | الرياضة | السلامة |
|
||||
|:-------------------------------------------------:|:----------------------------------------------------:|:-------------------------------------------:|
|
||||
| ![Vehicle Spare Parts Detection][car spare parts] | ![Football Player Detection][football player detect] | ![People Fall Detection][human fall detect] |
|
||||
| كشف قطع غيار المركبات | كشف لاعبي كرة القدم | كشف سقوط الأشخاص |
|
||||
|
||||
## لماذا يجب استخدام Ultralytics YOLO لعمليات التنبؤ؟
|
||||
|
||||
فيما يلي الأسباب التي يجب أخذها في الاعتبار عند الاستفادة من وضع التنبؤ YOLOv8 لاحتياجات التنبؤ المختلفة:
|
||||
|
||||
- **التنوع:** قادر على التنبؤ على الصور ومقاطع الفيديو، وحتى التدفقات الحية.
|
||||
- **الأداء:** مصمم للتطبيقات في الوقت الحقيقي والمعالجة عالية السرعة دون التضحية بالدقة.
|
||||
- **سهولة الاستخدام:** واجهات Python والواجهة السطرية لتسريع النشر والاختبار.
|
||||
- **قابلية التخصيص العالية:** إعدادات ومعلمات مختلفة لضبط سلوك التنبؤ النموذج وفقًا لمتطلباتك المحددة.
|
||||
|
||||
### الميزات الرئيسية لوضع التنبؤ
|
||||
|
||||
تم تصميم وضع التنبؤ الخاص بـ YOLOv8 ليكون قويًا ومتعدد الاستخدامات، ويتميز بما يلي:
|
||||
|
||||
- **توافق متعدد مصادر البيانات:** سواء كانت بياناتك عبارة عن صور فردية أو مجموعة من الصور أو ملفات فيديو أو تدفقات فيديو في الوقت الحقيقي، سيتمكن وضع التنبؤ من التعامل معها جميعًا.
|
||||
- **وضع التدفق الحي:** استخدم ميزة التدفق لإنشاء مولد فعّال لكائنات "النتائج" باستخدام الذاكرة. قم بتمكين هذا بتعيين `stream=True` في طريقة استدعاء المتنبئ.
|
||||
- **معالجة دُفعات:** القدرة على معالجة العديد من الصور أو إطارات الفيديو في دُفعة واحدة، مما يزيد أكثر من سرعة التنبؤ.
|
||||
- **سهل التكامل:** يسهل الدمج مع خطوط الأنابيب البيانية الحالية ومكونات البرامج الأخرى بفضل واجهة برمجة التطبيقات المرنة.
|
||||
|
||||
تُرجع نماذج Ultralytics YOLO إما قائمة Python من كائنات "النتائج" أو مُنشئ برمجياً فعّال لكائنات الـ "النتائج" في حال تم تمرير `stream=True` إلى النموذج أثناء عملية التنبؤ:
|
||||
|
||||
!!! Example "التنبؤ"
|
||||
|
||||
=== "العودة بقائمة واحدة باستخدام `stream=False`"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج
|
||||
model = YOLO('yolov8n.pt') # نموذج YOLOv8n المُدرَّب مسبقًا
|
||||
|
||||
# تشغيل التنبؤ بدُفعة على قائمة من الصور
|
||||
results = model(['im1.jpg', 'im2.jpg']) # العودة بقائمة من كائنات 'النتائج'
|
||||
|
||||
# معالجة قائمة النتائج
|
||||
for result in results:
|
||||
boxes = result.boxes # كائن Boxes لمخرجات bbox
|
||||
masks = result.masks # كائن Masks لمخرجات قنوات الفصل العنقودي
|
||||
keypoints = result.keypoints # كائن Keypoints لمخرجات الاتجاهات
|
||||
probs = result.probs # كائن Probs لمخرجات التصنيف
|
||||
```
|
||||
|
||||
=== "العودة بمُنشئ فعال مع `stream=True`"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج
|
||||
model = YOLO('yolov8n.pt') # نموذج YOLOv8n المُدرَّب مسبقًا
|
||||
|
||||
# تشغيل التنبؤ بدُفعة على قائمة من الصور
|
||||
results = model(['im1.jpg', 'im2.jpg'], stream=True) # العودة بمُنشئ فعال لكائنات 'النتائج'
|
||||
|
||||
# معالجة المُنشئ الفعال
|
||||
for result in results:
|
||||
boxes = result.boxes # كائن Boxes لمخرجات bbox
|
||||
masks = result.masks # كائن Masks لمخرجات قنوات الفصل العنقودي
|
||||
keypoints = result.keypoints # كائن Keypoints لمخرجات الاتجاهات
|
||||
probs = result.probs # كائن Probs لمخرجات التصنيف
|
||||
```
|
||||
|
||||
## مصادر التنبؤ
|
||||
|
||||
يمكن لـ YOLOv8 معالجة أنواع مختلفة من مصادر الإدخال لعملية الاستدلال، على النحو الموضح في الجدول أدناه. تشمل المصادر الصور الثابتة وتيارات الفيديو وتنسيقات مختلفة للبيانات. يشير الجدول أيضًا إلى ما إذا كان يمكن استخدام كل مصدر في وضع التدفق باستخدام الوسيط `stream=True` ✅. يعتبر وضع التدفق مفيدًا لمعالجة مقاطع الفيديو أو التدفقات الحية حيث يقوم بإنشاء مُنشئ للنتائج بدلاً من تحميل جميع الإطارات في الذاكرة.
|
||||
|
||||
!!! Tip "طراز"
|
||||
|
||||
استخدم `stream=True` لمعالجة مقاطع الفيديو الطويلة أو مجموعات البيانات الكبيرة لإدارة الذاكرة بكفاءة. عندما تكون القيمة مساوية لـ `stream=False`، يتم تخزين النتائج لجميع الإطارات أو نقاط البيانات في الذاكرة، والتي يمكن أن تتراكم بسرعة وتُسبِّب أخطاء الذاكرة غير الكافية للمدخلات الكبيرة. على النقيض من ذلك، يستخدم التدفق `stream=True` مولدًا يُبقي نتائج الإطار الحالي أو نقطة البيانات الحالية في الذاكرة فقط، مما يقلل بشكل كبير من استهلاك الذاكرة ويمنع مشكلات عدم كفاية الذاكرة.
|
||||
|
||||
| مصدر | الوسيط | النوع | الملاحظات |
|
||||
|------------------|--------------------------------------------|-----------------|----------------------------------------------------------------------------------------------|
|
||||
| صورة | `'صورة.jpg'` | `str` or `Path` | ملف صورة واحدة. |
|
||||
| رابط URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | رابط URL لصورة ما. |
|
||||
| لقطة شاشة برمجية | `'الشاشة'` | `str` | قم بالتقاط لقطة شاشة برمجية. |
|
||||
| PIL | `Image.open('im.jpg')` | `PIL.Image` | الصيغة HWC مع قنوات RGB. |
|
||||
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | الصيغة HWC مع قنوات BGR `uint8 (0-255)`. |
|
||||
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | الصيغة HWC مع قنوات BGR `uint8 (0-255)`. |
|
||||
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | الصيغة BCHW مع قنوات RGB `float32 (0.0-1.0)`. |
|
||||
| CSV | `'المصادر.csv'` | `str` or `Path` | ملف CSV يحتوي على مسارات الصور أو مقاطع الفيديو أو المجلدات. |
|
||||
| فيديو ✅ | `'الفيديو.mp4'` | `str` or `Path` | ملف فيديو بتنسيقات مثل MP4 و AVI وما إلى ذلك. |
|
||||
| الدليل ✅ | `'المسار/'` | `str` or `Path` | مسار إلى مجلد يحتوي على صور أو مقاطع فيديو. |
|
||||
| glob ✅ | `'المسار/*.jpg'` | `str` | نمط glob لمطابقة عدة ملفات. استخدم حرف `*` كحرطوم. |
|
||||
| يوتيوب ✅ | `'https://youtu.be/LNwODJXcvt4'` | `str` | رابط URL إلى فيديو يوتيوب. |
|
||||
| تدفق ✅ | `'rtsp://example.com/media.mp4'` | `str` | عنوان URL لبروتوكولات التدفق مثل RTSP و RTMP و TCP أو عنوان IP. |
|
||||
| تدفق متعدد ✅ | `'list.streams'` | `str` or `Path` | ملف نصي `*.streams` مع عنوان تدفق URL في كل صف، على سبيل المثال 8 تدفقات ستعمل بحجم دُفعة 8. |
|
||||
|
||||
فيما يلي أمثلة تعليمات برمجية لاستخدام كل نوع من مصدر:
|
||||
|
||||
!!! Example "مصادر التنبؤ"
|
||||
|
||||
=== "الصورة"
|
||||
قم بأجراء عملية التنبؤ على ملف صورة.
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرب مسبقًا
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# تنشيط عملية التنبؤ لملف الصورة
|
||||
source = 'المسار/إلى/الصورة.jpg'
|
||||
|
||||
# الجمع بين التنبؤ على المصدر
|
||||
results = model(source) # قائمة كائنات النتائج
|
||||
```
|
||||
|
||||
=== "لقطة شاشة برمجية"
|
||||
قم بأجراء عملية التنبؤ على محتوى الشاشة الحالي كلقطة شاشة.
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرب مسبقًا
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# تعريف اللقطة الحالية كمصدر
|
||||
source = 'الشاشة'
|
||||
|
||||
# الجمع بين التنبؤ على المصدر
|
||||
results = model(source) # قائمة كائنات النتائج
|
||||
```
|
||||
|
||||
=== "رابط URL"
|
||||
قم بأجراء عملية التنبؤ على صورة موجودة على الإنترنت أو فيديو.
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرب مسبقًا
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# تعريف رابط الصورة أو الفيديو على الإنترنت
|
||||
source = 'https://ultralytics.com/images/bus.jpg'
|
||||
|
||||
# الجمع بين التنبؤ على المصدر
|
||||
results = model(source) # قائمة كائنات النتائج
|
||||
```
|
||||
|
||||
=== "PIL"
|
||||
قم بأجراء عملية التنبؤ على صورة مفتوحة بواسطة مكتبة Python Imaging Library (PIL).
|
||||
```python
|
||||
from PIL import Image
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرب مسبقًا
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# فتح صورة باستخدام PIL
|
||||
source = Image.open('المسار/إلى/الصورة.jpg')
|
||||
|
||||
# الجمع بين التنبؤ على المصدر
|
||||
results = model(source) # قائمة كائنات النتائج
|
||||
```
|
||||
|
||||
=== "OpenCV"
|
||||
قم بأجراء عملية التنبؤ على صورة مُقروءة بواسطة OpenCV.
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرب مسبقًا
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# قراءة صورة باستخدام OpenCV
|
||||
source = cv2.imread('المسار/إلى/الصورة.jpg')
|
||||
|
||||
# الجمع بين التنبؤ على المصدر
|
||||
results = model(source) # قائمة كائنات النتائج
|
||||
```
|
||||
|
||||
=== "numpy"
|
||||
قم بأجراء عملية التنبؤ على صورة مُمثلة كمصفوفة numpy.
|
||||
```python
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج YOLOv8n المدرب مسبقًا
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# إنشاء مصفوفة numpy عشوائية في صيغة HWC (640, 640, 3) بقيم بين [0, 255] ونوع uint8
|
||||
source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
|
||||
|
||||
# الجمع بين التنبؤ على المصدر
|
||||
results = model(source) # قائمة كائنات النتائج
|
||||
```
|
||||
|
||||
[car spare parts]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a0f802a8-0776-44cf-8f17-93974a4a28a1
|
||||
|
||||
[football player detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/7d320e1f-fc57-4d7f-a691-78ee579c3442
|
||||
|
||||
[human fall detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/86437c4a-3227-4eee-90ef-9efb697bdb43
|
||||
|
|
@ -1,360 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعرف على كيفية استخدام Ultralytics YOLO لتتبع الكائنات في تدفقات الفيديو. أدلة لاستخدام مختلف المتتبعين وتخصيص إعدادات المتتبع.
|
||||
keywords: Ultralytics، YOLO، تتبع الكائنات، تدفقات الفيديو، BoT-SORT، ByteTrack، دليل Python، دليل خط الأوامر (CLI)
|
||||
---
|
||||
|
||||
# تتبع عدة كائنات باستخدام Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418637-1d6250fd-1515-4c10-a844-a32818ae6d46.png" alt="Multi-object tracking examples">
|
||||
|
||||
يعد تتبع الكائنات في مجال تحليل الفيديو مهمة حرجة ليس فقط في تحديد موقع وفئة الكائنات داخل الإطار، ولكن أيضًا في الحفاظ على هوية فريدة لكل كائن يتم اكتشافه مع تقدم الفيديو. تكاد التطبيقات لا تعد ولا تحصى - تتراوح من المراقبة والأمان إلى تحليل الرياضة الفورية.
|
||||
|
||||
## لماذا يجب اختيار Ultralytics YOLO لتتبع الكائنات؟
|
||||
|
||||
إن مخرجات المتتبعين في Ultralytics متسقة مع كشف الكائنات القياسي ولها قيمة مضافة من هويات الكائنات. هذا يجعل من السهل تتبع الكائنات في تدفقات الفيديو وأداء التحليلات التالية. إليك لماذا يجب أن تفكر في استخدام Ultralytics YOLO لتلبية احتياجات تتبع الكائنات الخاصة بك:
|
||||
|
||||
- **الكفاءة:** معالجة تدفقات الفيديو في الوقت الحقيقي دون المساومة على الدقة.
|
||||
- **المرونة:** يدعم العديد من خوارزميات التتبع والتكوينات.
|
||||
- **سهولة الاستخدام:** واجهة برمجة تطبيقات بسيطة للغاية وخيارات سطر الأوامر للاستدماج السريع والنشر.
|
||||
- **إمكانية التخصيص:** سهل الاستخدام مع نماذج YOLO مدربة مخصصة، مما يسمح بالاكتمال في التطبيقات ذات النطاق الخاص.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/hHyHmOtmEgs?si=VNZtXmm45Nb9s-N-"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> كشف الكائنات وتتبعها باستخدام Ultralytics YOLOv8.
|
||||
</p>
|
||||
|
||||
## تطبيقات في العالم الحقيقي
|
||||
|
||||
| النقل | البيع بالتجزئة | الاستزراع المائي |
|
||||
|:----------------------------------:|:--------------------------------:|:----------------------------:|
|
||||
| ![Vehicle Tracking][vehicle track] | ![People Tracking][people track] | ![Fish Tracking][fish track] |
|
||||
| تتبع المركبات | تتبع الأشخاص | تتبع الأسماك |
|
||||
|
||||
## ملامح بلمحة
|
||||
|
||||
يوفر Ultralytics YOLO ميزات كشف الكائنات لتوفير تتبع فعال ومتعدد الاستخدامات للكائنات:
|
||||
|
||||
- **تتبع فوري:** تتبع الكائنات بسلاسة في مقاطع الفيديو ذات معدل الإطارات العالي.
|
||||
- **دعم عدة متتبعين:** اختيار بين مجموعة متنوعة من خوارزميات التتبع المعتمدة.
|
||||
- **تخصيص تكوينات المتتبع المتاحة:** ضبط خوارزمية التتبع لتلبية المتطلبات المحددة عن طريق ضبط مختلف المعلمات.
|
||||
|
||||
## متتبعون متاحون
|
||||
|
||||
يدعم Ultralytics YOLO الخوارزميات التالية للتتبع. يمكن تمكينها عن طريق تمرير ملف تكوين YAML ذي الصلة مثل "tracker=tracker_type.yaml":
|
||||
|
||||
* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - استخدم `botsort.yaml` لتمكين هذا المتتبع.
|
||||
* [ByteTrack](https://github.com/ifzhang/ByteTrack) - استخدم `bytetrack.yaml` لتمكين هذا المتتبع.
|
||||
|
||||
المتتبع الافتراضي هو BoT-SORT.
|
||||
|
||||
## تتبع
|
||||
|
||||
لتشغيل المتتبع على تدفقات الفيديو، استخدم نموذج تحديد (Detect) أو قطع (Segment) أو وضع (Pose) مدرب مثل YOLOv8n و YOLOv8n-seg و YOLOv8n-pose.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل نموذج رسمي أو مخصص
|
||||
model = YOLO('yolov8n.pt') # قم بتحميل نموذج رسمي Detect
|
||||
model = YOLO('yolov8n-seg.pt') # قم بتحميل نموذج رسمي Segment
|
||||
model = YOLO('yolov8n-pose.pt') # قم بتحميل نموذج رسمي Pose
|
||||
model = YOLO('path/to/best.pt') # قم بتحميل نموذج مخصص مدرب
|
||||
|
||||
# قم بتنفيذ التتبع باستخدام النموذج
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True) # التتبع باستخدام المتتبع الافتراضي
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # التتبع باستخدام متتبع ByteTrack
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# قم بتنفيذ التتبع باستخدام مختلف النماذج باستخدام واجهة سطر الأوامر
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" # نموذج Detect رسمي
|
||||
yolo track model=yolov8n-seg.pt source="https://youtu.be/LNwODJXcvt4" # نموذج Segment رسمي
|
||||
yolo track model=yolov8n-pose.pt source="https://youtu.be/LNwODJXcvt4" # نموذج Pose رسمي
|
||||
yolo track model=path/to/best.pt source="https://youtu.be/LNwODJXcvt4" # تم تدريب نموذج مخصص
|
||||
|
||||
# تتبع عن طريق ByteTrack متتبع
|
||||
yolo track model=path/to/best.pt tracker="bytetrack.yaml"
|
||||
```
|
||||
|
||||
كما يظهر في الاستخدام أعلاه، يتوفر التتبع لجميع نماذج Detect و Segment و Pose التي تعمل على مقاطع الفيديو أو مصادر البث.
|
||||
|
||||
## الاعدادات
|
||||
|
||||
### معاملات التتبع
|
||||
|
||||
تتشارك إعدادات التتبع الخصائص مع وضع التوقعات (Predict)، مثل `conf` و `iou` و `show`. للحصول على مزيد من التكوينات، راجع صفحة النموذج [Predict](../modes/predict.md#inference-arguments).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتكوين معلمات التتبع وقم بتشغيل التتبع
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# قم بتكوين معلمات التتبع وقم بتشغيل التتبع باستخدام واجهة سطر الأوامر
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
|
||||
```
|
||||
|
||||
### اختيار المتتبع
|
||||
|
||||
يتيح لك Ultralytics أيضًا استخدام ملف تكوين متتبع معدل. للقيام بذلك، أنقل نسخة من ملف تكوين المتتبع (مثل `custom_tracker.yaml`) من [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) وقم بتعديل أي تكوينات (باستثناء `tracker_type`) حسب احتياجاتك.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل النموذج وتشغيل التتبع باستخدام ملف تكوين مخصص
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker='custom_tracker.yaml')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# قم بتحميل النموذج وتشغيل التتبع باستخدام ملف تكوين مخصص باستخدام واجهة سطر الأوامر
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
|
||||
```
|
||||
|
||||
للحصول على قائمة شاملة من وسائط تتبع، راجع الصفحة [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers).
|
||||
|
||||
## أمثلة Python
|
||||
|
||||
### الحفاظ على المسارات التكرارية
|
||||
|
||||
فيما يلي سكريبت Python باستخدام OpenCV (cv2) و YOLOv8 لتشغيل تتبع الكائنات على إطارات الفيديو. يفترض هذا السكريبت أنك قد قمت بالفعل بتثبيت الحزم اللازمة (opencv-python و ultralytics). المعامل `persist=True` يخبر المتتبع أن الصورة الحالية أو الإطار التالي في التسلسل ومن المتوقع أن يتوفر مسارات من الصورة السابقة في الصورة الحالية.
|
||||
|
||||
!!! Example "For-loop للتدفق مع التتبع"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# حمّل نموذج YOLOv8
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# افتح ملف الفيديو
|
||||
video_path = "path/to/video.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# تحلق عبر إطارات الفيديو
|
||||
while cap.isOpened():
|
||||
# قراءة الإطار من الفيديو
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# تشغيل تتبع YOLOv8 على الإطار ، وحفظ المسارات بين الإطارات
|
||||
results = model.track(frame, persist=True)
|
||||
|
||||
# تصور النتائج على الإطار
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# عرض الإطار المعلق
|
||||
cv2.imshow("YOLOv8 Tracking", annotated_frame)
|
||||
|
||||
# كسر اللوب في حالة الضغط على 'q'
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# كسر اللوب في نهاية الفيديو
|
||||
break
|
||||
|
||||
# إطلاق كائن التقاط الفيديو وإغلاق نافذة العرض
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
يرجى ملاحظة التغيير من `model(frame)` إلى `model.track(frame)` ، مما يمكن التتبع بدلاً من الكشف البسيط. سيتم تشغيل البرنامج المعدل على كل إطار فيديو وتصور النتائج وعرضها في نافذة. يمكن الخروج من الحلقة عن طريق الضغط على 'q'.
|
||||
|
||||
### رسم المسارات عبر الوقت
|
||||
|
||||
يمكن أن يوفر رسم المسارات الكائنية عبر الإطارات المتتالية إشارات قيمة حول أنماط الحركة والسلوك للكائنات المكتشفة في الفيديو. باستخدام Ultralytics YOLOv8 ، يعد تصوير هذه المسارات عملية سلسة وفعالة.
|
||||
|
||||
في المثال التالي ، نوضح كيفية استخدام قدرات يوكو 8 YOLO لتتبع الكائنات لرسم حركة الكائنات المكتشفة عبر إطارات الفيديو المتعددة. يتضمن هذا البرنامج فتح ملف فيديو وقراءته إطارًا بإطار ، واستخدام نموذج YOLO لتحديد وتتبع العديد من الكائنات. عن طريق الاحتفاظ بنقاط الوسط لمربعات الحدود المكتشفة وتوصيلها ، يمكننا رسم خطوط تمثل المسارات التي تم اتباعها بواسطة الكائنات التي تمت متابعتها.
|
||||
|
||||
!!! Example "رسم المسارات عبر إطارات الفيديو المتعددة"
|
||||
|
||||
```python
|
||||
from collections import defaultdict
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
from ultralytics import YOLO
|
||||
|
||||
# حمّل نموذج YOLOv8
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# افتح ملف الفيديو
|
||||
video_path = "path/to/video.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# احفظ تاريخ المسارات
|
||||
track_history = defaultdict(lambda: [])
|
||||
|
||||
# تحلق عبر إطارات الفيديو
|
||||
while cap.isOpened():
|
||||
# قراءة الإطار من الفيديو
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# تشغيل تتبع YOLOv8 على الإطار ، وحفظ المسارات بين الإطارات
|
||||
results = model.track(frame, persist=True)
|
||||
|
||||
# الحصول على المربعات ومعرفات المسار
|
||||
boxes = results[0].boxes.xywh.cpu()
|
||||
track_ids = results[0].boxes.id.int().cpu().tolist()
|
||||
|
||||
# تصور النتائج على الإطار
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# رسم المسارات
|
||||
for box, track_id in zip(boxes, track_ids):
|
||||
x, y, w, h = box
|
||||
track = track_history[track_id]
|
||||
track.append((float(x), float(y))) # x, y نقطة الوسط
|
||||
if len(track) > 30: # احتفظ بـ 90 مسارًا لـ 90 إطارًا
|
||||
track.pop(0)
|
||||
|
||||
# رسم خطوط التتبع
|
||||
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
|
||||
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
|
||||
|
||||
# عرض الإطار المعلق
|
||||
cv2.imshow("YOLOv8 Tracking", annotated_frame)
|
||||
|
||||
# كسر اللوب في حالة الضغط على 'q'
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# كسر اللوب في نهاية الفيديو
|
||||
break
|
||||
|
||||
# إطلاق كائن التقاط الفيديو وإغلاق نافذة العرض
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### التتبع متعدد الخيوط
|
||||
|
||||
يوفر التتبع متعدد الخيوط القدرة على تشغيل تتبع الكائنات على عدة تدفقات فيديو في وقت واحد. هذا مفيد بشكل خاص عند التعامل مع مدخلات فيديو متعددة ، مثل من كاميرات المراقبة المتعددة ، حيث يمكن أن يعزز المعالجة المتزامنة الكفاءة والأداء بشكل كبير.
|
||||
|
||||
في السكريبت البايثون المقدم ، نستخدم وحدة `threading` في Python لتشغيل عدة نسخ متزامنة من المتتبع. يكون لكل موضوع مسؤولية تشغيل المتتبع على ملف فيديو واحد ، وتعمل جميع الخيوط في الخلفية في نفس الوقت.
|
||||
|
||||
للتأكد من أن كل خيط يتلقى المعلمات الصحيحة (ملف الفيديو والنموذج المستخدم وفهرس الملف) ، نحدد وظيفة `run_tracker_in_thread` التي تقبل هذه المعلمات وتحتوي على حلقة المتابعة الرئيسية. هذه الوظيفة تقرأ إطار الفيديو الخاصة بالفيديو مباشرة من مصدر الملف الواحد ، وتشغيل المتتبع ، وعرض النتائج.
|
||||
|
||||
تستخدم في هذا المثال نموذجين مختلفين: 'yolov8n.pt' و 'yolov8n-seg.pt' ، يقوم كل منهما بتتبع الكائنات في ملف فيديو مختلف. تم تحديد ملفات الفيديو في `video_file1` و `video_file2`.
|
||||
|
||||
تعديل معلمات `daemon=True` في `threading.Thread` يعني أن هذه الخيوط ستتم إغلاقها بمجرد انتهاء البرنامج الرئيسي. ثم نبدأ الخيوط باستخدام `start ()` واستخدم `join ()` لجعل الخيط الرئيسي ينتظر حتى ينتهي خيطي المتتبع.
|
||||
|
||||
أخيرًا ، بعد اكتمال جميع الخيوط لمهمتها ، يتم إغلاق النوافذ التي تعرض النتائج باستخدام `cv2.destroyAllWindows()`.
|
||||
|
||||
!!! Example "Streaming for-loop with tracking"
|
||||
|
||||
```python
|
||||
import threading
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
|
||||
def run_tracker_in_thread(filename, model, file_index):
|
||||
"""
|
||||
يشغل ملف فيديو أو مصدر تيار الكاميرا بالتزامن مع YOLOv8 النموذج باستخدام تعدد الخيوط.
|
||||
|
||||
هذه الوظيفة تلتقط إطارات الفيديو من ملف أو مصدر الكاميرا المعروف ، وتستخدم نموذج YOLOv8 لتتبع الكائنات.
|
||||
يعمل البرنامج في خيطه الخاص للمعالجة المتزامنة.
|
||||
|
||||
Args:
|
||||
filename (str): مسار ملف الفيديو أو معرف مصدر كاميرا الويب / خارجية.
|
||||
model (obj): كائن نموذج YOLOv8.
|
||||
file_index (int): مؤشر لتحديد الملف بشكل فريد ، يُستخدم لأغراض العرض.
|
||||
|
||||
ملاحظة:
|
||||
اضغط على 'q' لإنهاء نافذة عرض الفيديو.
|
||||
"""
|
||||
video = cv2.VideoCapture(filename) # قراءة ملف الفيديو
|
||||
|
||||
while True:
|
||||
ret, frame = video.read() # قراءة إطارات الفيديو
|
||||
|
||||
# إنهاء الدورة إذا لم يتبقى إطارات على الفيديوين
|
||||
if not ret:
|
||||
break
|
||||
|
||||
# تتبع كائنات في الإطارات إذا توفرت
|
||||
results = model.track(frame, persist=True)
|
||||
res_plotted = results[0].plot()
|
||||
cv2.imshow(f"Tracking_Stream_{file_index}", res_plotted)
|
||||
|
||||
key = cv2.waitKey(1)
|
||||
if key == ord('q'):
|
||||
break
|
||||
|
||||
# إطلاق مصدري الفيديو
|
||||
video.release()
|
||||
|
||||
|
||||
# حمّل النماذج
|
||||
model1 = YOLO('yolov8n.pt')
|
||||
model2 = YOLO('yolov8n-seg.pt')
|
||||
|
||||
# حدد ملفات الفيديو للمتابعين
|
||||
video_file1 = "path/to/video1.mp4" # مسار ملف الفيديو ، 0 لكاميرا الويب
|
||||
video_file2 = 0 # مسار ملف الفيديو ، 0 لكاميرا الويب ، 1 لكاميرا خارجية
|
||||
|
||||
# إنشاء خيوط المتابع
|
||||
tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1 ,1), daemon=True)
|
||||
tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2, 2), daemon=True)
|
||||
|
||||
# بدء خيوط المتابع
|
||||
tracker_thread1.start()
|
||||
tracker_thread2.start()
|
||||
|
||||
# انتظر حتى ينتهي خيط المتابع
|
||||
tracker_thread1.join()
|
||||
tracker_thread2.join()
|
||||
|
||||
# Clean up and close windows
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
يمكن بسهولة توسيع هذا المثال للتعامل مع ملفات فيديو ونماذج أخرى من خلال إنشاء مزيد من الخيوط وتطبيق نفس المنهجية.
|
||||
|
||||
## المساهمة في المتتبعون الجديدون
|
||||
|
||||
هل أنت ماهر في التتبع متعدد الكائنات وقد نفذت أو صيغت بنجاح خوارزمية تتبع باستخدام Ultralytics YOLO؟ ندعوك للمشاركة في قسم المتتبعين لدينا في [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers)! قد تكون التطبيقات في العالم الحقيقي والحلول التي تقدمها لا تقدر بثمن للمستخدمين العاملين على مهام التتبع.
|
||||
|
||||
من خلال المساهمة في هذا القسم ، تساعد في توسيع نطاق حلول التتبع المتاحة في إطار Ultralytics YOLO ، مضيفًا طبقة أخرى من الوظائف والفعالية للمجتمع.
|
||||
|
||||
لبدء المساهمة ، يرجى الرجوع إلى [دليل المساهمة الخاص بنا](https://docs.ultralytics.com/help/contributing) للحصول على تعليمات شاملة حول تقديم طلب سحب (PR) 🛠️. نتطلع بشكل كبير إلى ما ستجلبه للطاولة!
|
||||
|
||||
لنعزز معًا قدرات عملية التتبع لأجهزة Ultralytics YOLO 🙏!
|
||||
|
||||
[vehicle track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/ee6e6038-383b-4f21-ac29-b2a1c7d386ab
|
||||
|
||||
[people track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/93bb4ee2-77a0-4e4e-8eb6-eb8f527f0527
|
||||
|
||||
[fish track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a5146d0f-bfa8-4e0a-b7df-3c1446cd8142
|
||||
|
|
@ -1,286 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: دليل خطوة بخطوة لتدريب نماذج YOLOv8 باستخدام Ultralytics YOLO بما في ذلك أمثلة على التدريب باستخدام بطاقة رسومات منفصلة ومتعددة البطاقات الرسومية
|
||||
keywords: Ultralytics، YOLOv8، YOLO، كشف الكائنات، وضع تدريب، مجموعة بيانات مخصصة، تدريب بطاقة رسومات، متعددة البطاقات الرسومية، معلمات تكبير، أمثلة سطر الأوامر، أمثلة بايثون
|
||||
---
|
||||
|
||||
# تدريب النموذج باستخدام Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="بيئة ومدمجات Ultralytics YOLO">
|
||||
|
||||
## المقدمة
|
||||
|
||||
يتضمن تدريب نموذج التعلم العميق تزويده بالبيانات وضبط معلماته بحيث يتمكن من إجراء توقعات دقيقة. يتم تصميم وضع التدريب في Ultralytics YOLOv8 لتدريب فعال وفعال لنماذج كشف الكائنات، مستغلاً تمامًا إمكانات الأجهزة الحديثة. يهدف هذا الدليل إلى شرح جميع التفاصيل التي تحتاج إلى البدء في تدريب النماذج الخاصة بك باستخدام مجموعة متينة من ميزات YOLOv8.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/LNwODJXcvt4?si=7n1UvGRLSd9p5wKs"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> كيفية تدريب نموذج YOLOv8 على مجموعة البيانات المخصصة الخاصة بك في Google Colab.
|
||||
</p>
|
||||
|
||||
## لماذا اختيار Ultralytics YOLO للتدريب؟
|
||||
|
||||
إليك بعض الأسباب المقنعة لاختيار وضع التدريب في YOLOv8:
|
||||
|
||||
- **الكفاءة:** استفد إلى أقصى حد من الأجهزة الخاصة بك، سواء كنت تستخدم بطاقة رسومات واحدة أو توسيعها عبر عدة بطاقات رسومات.
|
||||
- **تعدد الاستخدامات:** قم بالتدريب على مجموعات البيانات المخصصة بالإضافة إلى المجموعات المتاحة بسهولة مثل COCO و VOC و ImageNet.
|
||||
- **سهل الاستخدام:** واجهة سطر الأوامر CLI وواجهة Python البسيطة والقوية لتجربة تدريب مباشرة.
|
||||
- **مرونة المعلمات:** مجموعة واسعة من المعلمات القابلة للتخصيص لضبط أداء النموذج.
|
||||
|
||||
### الميزات الرئيسية لوضع التدريب
|
||||
|
||||
تتمثل الميزات البارزة لوضع التدريب في YOLOv8 في ما يلي:
|
||||
|
||||
- **تنزيل مجموعة البيانات تلقائيًا:** تقوم مجموعات البيانات القياسية مثل COCO و VOC و ImageNet بالتنزيل تلقائيًا عند أول استخدام.
|
||||
- **دعم متعدد البطاقات الرسومية:** قم بتوزيع العمليات التدريبية بسلاسة عبر عدة بطاقات رسومات لتسريع العملية.
|
||||
- **ضبط المعلمات:** الخيار لتعديل المعلمات التكبير من خلال ملفات تكوين YAML أو وسائط سطر الأوامر.
|
||||
- **مراقبة وتتبع:** تتبع في الوقت الفعلي لمقاييس التدريب وتصور عملية التعلم لتحقيق رؤى أفضل.
|
||||
|
||||
!!! Example "نصيحة"
|
||||
|
||||
* يتم تنزيل مجموعات YOLOv8 القياسية مثل COCO و VOC و ImageNet وغيرها تلقائيًا عند الاستخدام الأول، على سبيل المثال: `yolo train data=coco.yaml`
|
||||
|
||||
## أمثلة استخدام
|
||||
|
||||
تدريب YOLOv8n على مجموعة بيانات COCO128 لمدة 100 حقبة بحجم صورة 640. يمكن تحديد جهاز التدريب باستخدام الوسيطة `device`. إذا لم يتم تمرير وسيطة، سيتم استخدام الجهاز بطاقة الرسومات "device=0" إذا كانت متاحة، وإلا سيتم استخدام `device=cpu`. استعرض الجدول الزمني أدناه للحصول على قائمة كاملة بوسائط التدريب.
|
||||
|
||||
!!! Example "أمثلة سطر الأوامر للتدريب باستخدام بطاقة رسومات مستقلة ومعالج مركزي"
|
||||
|
||||
يتم تحديد الجهاز تلقائيًا. إذا كانت بطاقة رسومات متاحة، سيتم استخدامها، وإلا ستبدأ التدريب على المعالج المركزي.
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n.yaml') # إنشاء نموذج جديد من ملف YAML
|
||||
model = YOLO('yolov8n.pt') # تحميل نموذج مدرب مسبقًا (الأكثر توصية للتدريب)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # إنشاء من ملف YAML ونقل الأوزان
|
||||
|
||||
# تدريب النموذج
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "سطر الأوامر"
|
||||
```bash
|
||||
# إنشاء نموذج جديد من ملف YAML وبدء التدريب من البداية
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# بدء التدريب من نموذج *.pt مدرب مسبقًا
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# إنشاء نموذج جديد من ملف YAML ونقل الأوزان المدربة مسبقًا وبدء التدريب
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### التدريب متعدد البطاقات الرسومية
|
||||
|
||||
يتيح التدريب متعدد البطاقات الرسومية استخدام الموارد الأجهزة المتاحة بكفاءة أكبر من خلال توزيع أعباء التدريب عبر عدة بطاقات رسومية. هذه الميزة متاحة من خلال واجهة برمجة التطبيقات باستخدام Python وسطر الأوامر. لتمكين التدريب متعدد البطاقات الرسومية، حدد معرفات أجهزة GPU التي ترغب في استخدامها.
|
||||
|
||||
!!! Example "أمثلة على التدريب متعدد البطاقات الرسومية"
|
||||
|
||||
للتدريب باستخدام أجهزتي GPU، جهاز CUDA 0 و 1، استخدم الأوامر التالية. قم بتوسيعها لاستخدام المزيد من البطاقات.
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n.pt') # تحميل نموذج مدرب مسبقًا (الأكثر توصية للتدريب)
|
||||
|
||||
# تدريب النموذج بأجهزة GPU 2
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
|
||||
```
|
||||
|
||||
=== "سطر الأوامر"
|
||||
```bash
|
||||
# بدء التدريب من نموذج *.pt مدرب مسبقًا باستخدام بطاقات GPU 0 و 1
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
|
||||
```
|
||||
|
||||
### التدريب باستخدام Apple M1 و M2 MPS
|
||||
|
||||
مع دعم شرائح Apple M1 و M2 المدمج في نماذج Ultralytics YOLO، يمكنك الآن تدريب نماذجك على الأجهزة التي تستخدم نظام Metal Performance Shaders (MPS) القوي. يوفر MPS طريقة عالية الأداء لتنفيذ المهام الحسابية ومعالجة الصور على شرائح السيليكون المخصصة لعبة Apple.
|
||||
|
||||
لتمكين التدريب على شرائح Apple M1 و M2، يجب عليك تحديد "mps" كجهازك عند بدء عملية التدريب. فيما يلي مثال لكيفية القيام بذلك في بايثون وعبر سطر الأوامر:
|
||||
|
||||
!!! Example "مثال على التدريب بواسطة MPS"
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n.pt') # تحميل نموذج مدرب مسبقًا (الأكثر توصية للتدريب)
|
||||
|
||||
# تدريب النموذج باستخدام 2 بطاقات GPU
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
|
||||
```
|
||||
|
||||
=== "سطر الأوامر"
|
||||
```bash
|
||||
# بدء التدريب من نموذج *.pt مدرب مسبقًا باستخدام بطاقات GPU 0 و 1
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
|
||||
```
|
||||
|
||||
عند الاستفادة من قدرة المعالجة الحاسوبية لشرائح M1/M2، يتيح لك هذا الحمل أداءً أكثر كفاءة لمهام التدريب. للحصول على إرشادات أكثر تفصيلاً وخيارات تكوين متقدمة، يرجى الرجوع إلى [وثائق PyTorch MPS](https://pytorch.org/docs/stable/notes/mps.html).
|
||||
|
||||
### استئناف التدريب المقطوع
|
||||
|
||||
يعتبر استئناف التدريب من الحالات التخزين السابقة ميزة حاسمة عند العمل مع نماذج التعلم العميق. يمكن أن يكون هذا مفيدًا في العديد من السيناريوهات، مثل عند تعطل عملية التدريب بشكل غير متوقع، أو عند الرغبة في متابعة تدريب نموذج بيانات جديدة أو لفترة زمنية أطول.
|
||||
|
||||
عند استئناف التدريب، يقوم Ultralytics YOLO بتحميل الأوزان من آخر نموذج محفوظ وأيضًا استعادة حالة المحسن، وجدولة معدل التعلم، وعدد الحقبة. هذا يتيح لك متابعة عملية التدريب بشكل سلس من حيث توقفت.
|
||||
|
||||
يمكنك بسهولة استئناف التدريب في Ultralytics YOLO عن طريق تعيين الوسيطة `resume` إلى `True` عند استدعاء طريقة `train`، وتحديد المسار إلى ملف `.pt` الذي يحتوي على أوزان النموذج المدرب جزئيًا.
|
||||
|
||||
فيما يلي مثال لكيفية استئناف تدريب مقطوع باستخدام بايثون وعبر سطر الأوامر:
|
||||
|
||||
!!! Example "مثال على استئناف التدريب"
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('path/to/last.pt') # تحميل نموذج مدرب جزئيًا
|
||||
|
||||
# استئناف التدريب
|
||||
results = model.train(resume=True)
|
||||
```
|
||||
|
||||
=== "سطر الأوامر"
|
||||
```bash
|
||||
# استئناف تدريب متقطع
|
||||
yolo train resume model=path/to/last.pt
|
||||
```
|
||||
|
||||
من خلال تعيين `resume=True`، ستواصل وظيفة 'train' التدريب من حيث توقفت، باستخدام الحالة المخزنة في ملف 'path/to/last.pt'. إذا تم حذف الوسيطة `resume` أو تعيينها على `False`، ستبدأ وظيفة 'train' جلسة تدريب جديدة.
|
||||
|
||||
تذكر أنه يتم حفظ نقاط التفتيش في نهاية كل حقبة افتراضياً، أو في فترة ثابتة باستخدام وسيطة 'save_period'، لذا يجب عليك إتمام حقبة واحدة على الأقل لاستئناف تشغيل تدريب.
|
||||
|
||||
## الوسائط
|
||||
|
||||
تتعلق إعدادات التدريب لنماذج YOLO بالمعلمات والتكوينات المختلفة المستخدمة لتدريب النموذج على مجموعة بيانات ما. يمكن أن تؤثر هذه الإعدادات على أداء النموذج وسرعته ودقته. تتضمن بعض إعدادات YOLO التدريب الشائعة حجم الدُفعات، معدل التعلم، الزخم، والتقليل القيمي للأوزان. العوامل الأخرى التي قد تؤثر في عملية التدريب تشمل اختيار المحسن، اختيار دالة الخسارة، وحجم وتركيب مجموعة البيانات التدريب. من المهم ضبط وتجربة هذه الإعدادات بعناية لتحقيق أفضل أداء ممكن لمهمة معينة.
|
||||
|
||||
| المفتاح | القيمة | الوصف |
|
||||
|-------------------|----------|---------------------------------------------------------------------------------------------------------------------------|
|
||||
| `model` | `None` | مسار إلى ملف النموذج، على سبيل المثال yolov8n.pt، yolov8n.yaml |
|
||||
| `data` | `None` | مسار إلى ملف البيانات، على سبيل المثال coco128.yaml |
|
||||
| `epochs` | `100` | عدد الحقب للتدريب ل |
|
||||
| `patience` | `50` | حقب للانتظار بدون تحسن ظاهر لإيقاف التدريب مبكرا |
|
||||
| `batch` | `16` | عدد الصور في كل دُفعة (-1 for AutoBatch) |
|
||||
| `imgsz` | `640` | حجم الصور الدخل بصورة مثالية |
|
||||
| `save` | `True` | حال إنقاذ النقاط المفتوحة للتدريب ونتائج الكشف |
|
||||
| `save_period` | `-1` | حفظ النقطة الفاصلة كل x حقبة (تكون معطلة إذا كانت < 1) |
|
||||
| `cache` | `False` | صحيح / ذاكرة عشوائية أو قرص / غير صحيح. استخدم ذاكرة التخزين المؤقت في تحميل البيانات |
|
||||
| `device` | `None` | الجهاز لتشغيل التدريب عليه، على سبيل المثال جهاز الرسومات cuda=0 أو جهاز الرسومات cuda=0,1,2,3 أو جهاز المعالج المركزيcpu |
|
||||
| `workers` | `8` | عدد خيوط العاملة لتحميل البيانات (لكل RANK إذا كان DDP) |
|
||||
| `project` | `None` | اسم المشروع |
|
||||
| `name` | `None` | اسم التجربة |
|
||||
| `exist_ok` | `False` | ما إذا كان سيتم الكتابة فوق تجربة موجودة |
|
||||
| `pretrained` | `True` | (bool أو str) ما إذا كان سيتم استخدام نموذج متدرب مسبقًا (bool) أو نموذج لتحميل الأوزان منه (str) |
|
||||
| `optimizer` | `'auto'` | المحسن لاستخدامه، الخيارات=[SGD، Adam، Adamax، AdamW، NAdam، RAdam، RMSProp، Auto] |
|
||||
| `verbose` | `False` | ما إذا كان سيتم طباعة مخرجات مفصلة |
|
||||
| `seed` | `0` | البذرة العشوائية لإعادة الإنتاجية |
|
||||
| `deterministic` | `True` | ما إذا كان يتم تمكين الوضع المحدد |
|
||||
| `single_cls` | `False` | يجب تدريب بيانات متعددة الفئات كفئة واحدة |
|
||||
| `rect` | `False` | تدريب مستطيل باستخدام تجميع الدُفعات للحد الأدنى من الحشو |
|
||||
| `cos_lr` | `False` | استخدم جدولة معدل التعلم بتوقيت الكوسا |
|
||||
| `close_mosaic` | `10` | (int) تعطيل التكبير التجانبي للحجم للحقب النهائية (0 للتعطيل) |
|
||||
| `resume` | `False` | استأنف التدريب من النقطة الأخيرة |
|
||||
| `amp` | `True` | تدريب دقة مختلطة تلقائية (AMP)، الخيارات=[True، False] |
|
||||
| `fraction` | `1.0` | نسبة مجموعة البيانات المراد تدريبها (الافتراضي هو 1.0، جميع الصور في مجموعة التدريب) |
|
||||
| `profile` | `False` | قم بتشغيل بروفايل السرعة لمشغلات ONNX و TensorRT أثناء التدريب للمسجلات |
|
||||
| `freeze` | `None` | (int أو list، اختياري) تجميد أول n طبقة، أو قائمة طبقات الفهرس خلال التدريب |
|
||||
| `lr0` | `0.01` | معدل التعلم الأولي (على سبيل المثال SGD=1E-2، Adam=1E-3) |
|
||||
| `lrf` | `0.01` | معدل التعلم النهائي (lr0 * lrf) |
|
||||
| `momentum` | `0.937` | الزخم SGD / Adam beta1 |
|
||||
| `weight_decay` | `0.0005` | تقليل الأوزان للمحسن (5e-4) |
|
||||
| `warmup_epochs` | `3.0` | حقب الاحماء (الأجزاء المئوية مقبولة) |
|
||||
| `warmup_momentum` | `0.8` | الزخم الأولي للتدفق الأعلى |
|
||||
| `warmup_bias_lr` | `0.1` | نسبة تعلم الانحياز الأولي للتدفق العلوي |
|
||||
| `box` | `7.5` | وزن فاقد الصندوق |
|
||||
| `cls` | `0.5` | وزن فاقد التصنيف (تناسب مع البكسل) |
|
||||
| `dfl` | `1.5` | وزن الخسارة الأمامية للتصنيف والصندوق |
|
||||
| `pose` | `12.0` | وزن فاقد الوضع (الوضع فقط) |
|
||||
| `kobj` | `2.0` | وزن فاقد نقطة المفتاح (الوضع فقط) |
|
||||
| `label_smoothing` | `0.0` | التسوية الغموض (كسر) |
|
||||
| `nbs` | `64` | حجم الدُفعة الاسمي |
|
||||
| `overlap_mask` | `True` | التحجيم يجب أن يتداخل أقنعة التدريب (التدريب الفصلي فقط) |
|
||||
| `mask_ratio` | `4` | معدل تحجيم أقنعة (التدريب الفصلي فقط) |
|
||||
| `dropout` | `0.0` | استخدام تنظيم الإسقاط (التدريب التطبيقي فقط) |
|
||||
| `val` | `True` | التحقق/الاختبار خلال التدريب |
|
||||
|
||||
## تسجيل
|
||||
|
||||
عند تدريب نموذج YOLOv8، قد تجد أنه من المفيد تتبع أداء النموذج مع مرور الوقت. هنا يأتي دور تسجيل. يوفر Ultralytics' YOLO دعمًا لثلاثة أنواع من أجهزة السجل - Comet و ClearML و TensorBoard.
|
||||
|
||||
لاستخدام سجل، حدده من قائمة السحب أسفل الكود وقم بتشغيله. سيتم تثبيت السجل المختار وتهيئته.
|
||||
|
||||
### Comet
|
||||
|
||||
[Comet](../../../integrations/comet.md) هو منصة تسمح لعلماء البيانات والمطورين بمتابعة ومقارنة وشرح وتحسين التجارب والنماذج. يوفر وظائف مثل المقاييس الزمنية في الوقت الحقيقي وفروقات الشفرة وتتبع المعلمات.
|
||||
|
||||
لاستخدام Comet:
|
||||
|
||||
!!! Example "أمثلة بايثون"
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
# pip install comet_ml
|
||||
import comet_ml
|
||||
|
||||
comet_ml.init()
|
||||
```
|
||||
|
||||
تذكر تسجيل الدخول إلى حسابك في Comet على موقعهم على الويب والحصول على مفتاح API الخاص بك. ستحتاج إلى إضافته إلى الإعدادات المتغيرة في البيئة الخاصة بك أو برنامج النص الخاص بك لتسجيل التجارب الخاصة بك.
|
||||
|
||||
### ClearML
|
||||
|
||||
[ClearML](https://www.clear.ml/) هي منصة مفتوحة المصدر تعمل على تتبع التجارب وتسهيل مشاركة الموارد بكفاءة. تم تصميمه لمساعدة الفرق في إدارة وتنفيذ وإعادة إنتاج عملهم في مجال تعلم الآلة بكفاءة أكبر.
|
||||
|
||||
لاستخدام ClearML:
|
||||
|
||||
!!! Example "أمثلة بايثون"
|
||||
|
||||
=== "بايثون"
|
||||
```python
|
||||
# pip install clearml
|
||||
import clearml
|
||||
|
||||
clearml.browser_login()
|
||||
```
|
||||
|
||||
بعد تشغيل هذا السكريبت، ستحتاج إلى تسجيل الدخول إلى حساب ClearML الخاص بك على المستعرض ومصادقة جلستك.
|
||||
|
||||
## TensorBoard
|
||||
|
||||
[TensorBoard](https://www.tensorflow.org/tensorboard) هي مجموعة أدوات لتصور TensorFlow ، تسمح لك بتصور نموذج TensorFlow الخاص بك ، ورسم المقاييس الكمية حول تنفيذ النموذج الخاص بك ، وعرض بيانات إضافية مثل الصور التي تمر عبرها.
|
||||
|
||||
للاستفادة من TensorBoard في [Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb):
|
||||
|
||||
!!! Example "أمثلة سطر الأوامر"
|
||||
|
||||
=== "سطر الأوامر"
|
||||
```bash
|
||||
load_ext tensorboard
|
||||
tensorboard --logdir ultralytics/runs # استبدل بالدليل 'runs'
|
||||
```
|
||||
|
||||
لاستخدام TensorBoard محليًا، قم بتشغيل الأمر أدناه واعرض النتائج على الرابط http://localhost:6006/.
|
||||
|
||||
!!! Example "أمثلة سطر الأوامر"
|
||||
|
||||
=== "سطر الأوامر"
|
||||
```bash
|
||||
tensorboard --logdir ultralytics/runs # استبدل بالدليل 'runs'
|
||||
```
|
||||
|
||||
سيتم تحميل TensorBoard وتوجيهه إلى الدليل الذي يتم حفظ سجلات التدريب فيه.
|
||||
|
||||
بعد إعداد السجل الخاص بك، يمكنك الاستمرار في تدريب النموذج. سيتم سجل جميع مقاييس التدريب تلقائيًا في المنصة التي اخترتها، ويمكنك الوصول إلى هذه السجلات لمراقبة أداء النموذج الخاص بك مع مرور الوقت ومقارنة نماذج مختلفة وتحديد المجالات التي يمكن تحسينها.
|
||||
|
|
@ -1,86 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: دليل لاختبار نماذج YOLOv8 الصحيحة. تعرف على كيفية تقييم أداء نماذج YOLO الخاصة بك باستخدام إعدادات ومقاييس التحقق من الصحة مع أمثلة برمجية باللغة البايثون وواجهة سطر الأوامر.
|
||||
keywords: Ultralytics, YOLO Docs, YOLOv8, التحقق من الصحة, تقييم النموذج, المعلمات الفرعية, الدقة, المقاييس, البايثون, واجهة سطر الأوامر
|
||||
---
|
||||
|
||||
# التحقق من النماذج باستخدام Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="بيئة النظام البيئي والتكاملات لـ Ultralytics YOLO">
|
||||
|
||||
## مقدمة
|
||||
|
||||
يعتبر التحقق من النموذج خطوة حاسمة في خط أنابيب التعلم الآلي، حيث يتيح لك تقييم جودة النماذج المدربة. يوفر وضع الـ Val في Ultralytics YOLOv8 مجموعة أدوات ومقاييس قوية لتقييم أداء نماذج الكشف عن الكائنات الخاصة بك. يعمل هذا الدليل كمصدر كامل لفهم كيفية استخدام وضع الـ Val بشكل فعال لضمان أن نماذجك دقيقة وموثوقة.
|
||||
|
||||
## لماذا يوفر Ultralytics YOLO التحقق من الصحة
|
||||
|
||||
هنا هي الأسباب التي تجعل استخدام وضع الـ Val في YOLOv8 مفيدًا:
|
||||
|
||||
- **الدقة:** الحصول على مقاييس دقيقة مثل mAP50 و mAP75 و mAP50-95 لتقييم نموذجك بشكل شامل.
|
||||
- **الراحة:** استخدم الميزات المدمجة التي تتذكر إعدادات التدريب، مما يبسط عملية التحقق من الصحة.
|
||||
- **مرونة:** قم بالتحقق من النموذج باستخدام نفس المجموعات البيانات وأحجام الصور أو مجموعات بيانات وأحجام صور مختلفة.
|
||||
- **ضبط المعلمات الفرعية:** استخدم المقاييس التحقق لضبط نموذجك لتحسين الأداء.
|
||||
|
||||
### الميزات الرئيسية لوضع الـ Val
|
||||
|
||||
هذه هي الوظائف المميزة التي يوفرها وضع الـ Val في YOLOv8:
|
||||
|
||||
- **الإعدادات التلقائية:** يتذكر النماذج إعدادات التدريب الخاصة بها للتحقق من الصحة بسهولة.
|
||||
- **دعم متعدد المقاييس:** قيم نموذجك بناءً على مجموعة من مقاييس الدقة.
|
||||
- **واجهة سطر الأوامر وواجهة برمجة Python:** اختر بين واجهة سطر الأوامر أو واجهة برمجة Python حسب تفضيلك للتحقق من الصحة.
|
||||
- **توافق البيانات:** يعمل بسلاسة مع مجموعات البيانات المستخدمة خلال مرحلة التدريب بالإضافة إلى مجموعات البيانات المخصصة.
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
* تتذكر نماذج YOLOv8 إعدادات التدريب تلقائيًا، لذا يمكنك التحقق من النموذج بنفس حجم الصورة وعلى مجموعة البيانات الأصلية بسهولة باستخدام "yolo val model=yolov8n.pt" أو "model('yolov8n.pt').val()"
|
||||
|
||||
## أمثلة الاستخدام
|
||||
|
||||
تحقق من دقة النموذج المدرب YOLOv8n على مجموعة بيانات COCO128. لا يلزم تمرير أي وسيطة كوسيطة يتذكر الـ model التدريب والوسيطات كسمات النموذج. انظر الجدول أدناه للحصول على قائمة كاملة من وسيطات التصدير.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "البايثون"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n.pt') # تحميل النموذج الرسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مخصص
|
||||
|
||||
# التحقق من النموذج
|
||||
metrics = model.val() # لا يلزم أي وسيطات، يتذكر التكوين والوسيطات
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # قائمة تحتوي على map50-95 لكل فئة
|
||||
```
|
||||
=== "واجهة سطر الأوامر"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # تجريب نموذج رسمي
|
||||
yolo detect val model=path/to/best.pt # تجٌَرب نموذج مخصص
|
||||
```
|
||||
|
||||
## الوسيطات
|
||||
|
||||
تشير إعدادات التحقق بالنسبة لنماذج YOLO إلى المعلمات الفرعية والتكوينات المختلفة المستخدمة لتقييم أداء النموذج على مجموعة بيانات التحقق. هذه الإعدادات يمكن أن تؤثر على أداء النموذج وسرعته ودقته. تشمل بعض إعدادات التحقق الشائعة في YOLO حجم الدفعة وتكرارات تنفيذ التحقق أثناء التدريب والمقاييس المستخدمة لتقييم أداء النموذج. العوامل الأخرى التي قد تؤثر على العملية الخاصة بالتحقق تشمل حجم وتركيب مجموعة البيانات التحقق والمهمة المحددة التي يتم استخدام النموذج فيها. من المهم ضبط هذه الإعدادات وتجربتها بعناية لضمان أداء جيد للنموذج على مجموعة بيانات التحقق وكشف ومنع الحالة التي يتم فيها ضبط الطراز بشكل جيد.
|
||||
|
||||
| مفتاح | القيمة | الوصف |
|
||||
|---------------|---------|------------------------------------------------------------------------------------|
|
||||
| `data` | `None` | مسار إلى ملف البيانات، على سبيل المثال coco128.yaml |
|
||||
| `imgsz` | `640` | حجم الصور الداخلية باعتبارها عدد صحيح |
|
||||
| `batch` | `16` | عدد الصور لكل دفعة (-1 للدفع الآلي) |
|
||||
| `save_json` | `False` | حفظ النتائج في ملف JSON |
|
||||
| `save_hybrid` | `False` | حفظ النسخة المختلطة للتسميات (التسميات + التنبؤات الإضافية) |
|
||||
| `conf` | `0.001` | حد الثقة في كشف الكائن |
|
||||
| `iou` | `0.6` | حد تداخل على المتحدة (IoU) لعملية الجمع والطرح |
|
||||
| `max_det` | `300` | العدد الأقصى من الكشفات لكل صورة |
|
||||
| `half` | `True` | استخدم التنصت نصف الدقة (FP16) |
|
||||
| `device` | `None` | الجهاز الذي يتم تشغيله عليه، على سبيل المثال جهاز Cuda=0/1/2/3 أو جهاز=معالج (CPU) |
|
||||
| `dnn` | `False` | استخدم OpenCV DNN لعملية التنصت الأمثل |
|
||||
| `plots` | `False` | إظهار الرسوم البيانية أثناء التدريب |
|
||||
| `rect` | `False` | تحقق صيغة *rectangular* مع تجميع كل دفعة للحصول على الحد الأدنى من التعبئة |
|
||||
| `split` | `val` | اختر تقسيم البيانات للتحقق من الصحة، على سبيل المثال "val"، "test" أو "train" |
|
||||
|
|
||||
|
|
@ -1,326 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: استكشف أساليب مختلفة لتثبيت Ultralytics باستخدام pip و conda و git و Docker. تعرّف على كيفية استخدام Ultralytics مع واجهة سطر الأوامر أو ضمن مشاريع Python الخاصة بك.
|
||||
keywords: تثبيت Ultralytics, pip install Ultralytics, Docker install Ultralytics, Ultralytics command line interface, Ultralytics Python interface
|
||||
---
|
||||
|
||||
## تثبيت Ultralytics
|
||||
|
||||
يوفر Ultralytics طرق تثبيت مختلفة بما في ذلك pip و conda و Docker. يمكنك تثبيت YOLOv8 عن طريق حزمة `ultralytics` من خلال pip للإصدار الأحدث والمستقر أو من خلال استنساخ [مستودع Ultralytics على GitHub](https://github.com/ultralytics/ultralytics) للحصول على الإصدار الأحدث. يمكن استخدام Docker لتنفيذ الحزمة في حاوية معزولة، وتجنب التثبيت المحلي.
|
||||
|
||||
!!! Note "ملاحظة"
|
||||
|
||||
🚧 تم بناء وثائقنا متعددة اللغات حاليًا، ونعمل بجد لتحسينها. شكرًا لك على صبرك! 🙏
|
||||
|
||||
!!! Example "تثبيت"
|
||||
|
||||
=== "تثبيت باستخدام pip (الموصَى به)"
|
||||
قم بتثبيت حزمة `ultralytics` باستخدام pip، أو قم بتحديث التثبيت الحالي عن طريق تشغيل `pip install -U ultralytics`. قم بزيارة مؤشر Python Package Index (PyPI) للحصول على مزيد من التفاصيل حول حزمة `ultralytics`: [https://pypi.org/project/ultralytics/](https://pypi.org/project/ultralytics/).
|
||||
|
||||
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
||||
|
||||
```bash
|
||||
# قم بتثبيت حزمة ultralytics من PyPI
|
||||
pip install ultralytics
|
||||
```
|
||||
|
||||
يمكنك أيضًا تثبيت حزمة `ultralytics` مباشرة من مستودع GitHub [repository](https://github.com/ultralytics/ultralytics). قد يكون ذلك مفيدًا إذا كنت ترغب في الحصول على الإصدار التجريبي الأحدث. تأكد من تثبيت أداة الأوامر Git على نظامك. يُثبّت الأمر `@main` الفرع `main` ويمكن تعديله إلى فرع آخر، على سبيل المثال `@my-branch`، أو يمكن إزالته تمامًا للانتقال إلى الفرع الرئيسي `main`.
|
||||
|
||||
```bash
|
||||
# قم بتثبيت حزمة ultralytics من GitHub
|
||||
pip install git+https://github.com/ultralytics/ultralytics.git@main
|
||||
```
|
||||
|
||||
|
||||
=== "تثبيت باستخدام conda"
|
||||
Conda هو مدير حزم بديل لـ pip ويمكن استخدامه أيضًا للتثبيت. قم بزيارة Anaconda للحصول على مزيد من التفاصيل على [https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics). يمكن العثور على مستودع Ultralytics feedstock لتحديث حزمة conda على [https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/).
|
||||
|
||||
|
||||
[](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics)
|
||||
|
||||
```bash
|
||||
# قم بتثبيت حزمة ultralytics باستخدام conda
|
||||
conda install -c conda-forge ultralytics
|
||||
```
|
||||
|
||||
!!! Note "ملاحظة"
|
||||
|
||||
إذا كنت تقوم بالتثبيت في بيئة CUDA، فإن الممارسة الجيدة هي تثبيت `ultralytics`, `pytorch` و `pytorch-cuda` في نفس الأمر للسماح لمدير حزم conda بحل أي تعارضات، أو وإلا فقوم بتثبيت `pytorch-cuda` في نهاية الأمر للسماح له بتجاوز حزمة `pytorch` المحددة لوحدة المعالجة المركزية إذا لزم الأمر.
|
||||
```bash
|
||||
# قم بتثبيت كافة الحزم معًا باستخدام conda
|
||||
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
|
||||
```
|
||||
|
||||
### صورة Docker في Conda
|
||||
|
||||
تتوفر أيضًا صور Docker لـ Conda لـ Ultralytics من [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics). تستند هذه الصور إلى [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) وهي وسيلة بسيطة لبدء استخدام `ultralytics` في بيئة Conda.
|
||||
|
||||
```bash
|
||||
# قم بتعيين اسم الصورة بوصفه متغير
|
||||
t=ultralytics/ultralytics:latest-conda
|
||||
|
||||
# اسحب أحدث صورة ultralytics من Docker Hub
|
||||
sudo docker pull $t
|
||||
|
||||
# قم بتشغيل صورة ultralytics في حاوية مع دعم GPU
|
||||
sudo docker run -it --ipc=host --gpus all $t # all GPUs
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # قد يتم تحديد GPUs
|
||||
```
|
||||
|
||||
=== "استنساخ Git"
|
||||
قم بنسخ مستودع `ultralytics` إذا كنت مهتمًا بالمساهمة في التطوير أو ترغب في تجربة الشفرة المصدرية الأحدث. بعد الاستنساخ، انتقل إلى الدليل وقم بتثبيت الحزمة في وضع التحرير `-e` باستخدام pip.
|
||||
```bash
|
||||
# قم بنسخ مستودع ultralytics
|
||||
git clone https://github.com/ultralytics/ultralytics
|
||||
|
||||
# انتقل إلى الدليل المنسوخ
|
||||
cd ultralytics
|
||||
|
||||
# قم بتثبيت الحزمة في وضع التحرير
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
=== "Docker"
|
||||
|
||||
تمكنك من استخدام Docker بسهولة لتنفيذ حزمة `ultralytics` في حاوية معزولة، مما يضمن أداءً سلسًا ومتسقًا في مختلف البيئات. عن طريق اختيار إحدى صور Docker الأصلية لـ `ultralytics` من [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics)، لن تتجنب فقط تعقيد التثبيت المحلي ولكنك ستستفيد أيضًا من وصول إلى بيئة عمل متحققة وفعالة. يقدم Ultralytics 5 صور Docker مدعومة رئيسية، يتم تصميم كل منها لتوفير توافق عالي وكفاءة لمنصات وحالات استخدام مختلفة:
|
||||
|
||||
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
- **Dockerfile:** صورة GPU الموصى بها للتدريب.
|
||||
- **Dockerfile-arm64:** محسّن لبنية ARM64، مما يتيح النشر على أجهزة مثل Raspberry Pi ومنصات أخرى تعتمد على ARM64.
|
||||
- **Dockerfile-cpu:** إصدار مناسب للتحكم بوحدة المعالجة المركزية فقط بدون دعم لل GPU.
|
||||
- **Dockerfile-jetson:** مصمم خصيصًا لأجهزة NVIDIA Jetson، ويدمج دعمًا لل GPU المحسن لهذه المنصات.
|
||||
- **Dockerfile-python:** صورة صغيرة بها فقط Python والتبعيات الضرورية، مثالية للتطبيقات والتطوير الخفيف.
|
||||
- **Dockerfile-conda:** قائمة على Miniconda3 مع تثبيت conda لحزمة ultralytics.
|
||||
|
||||
فيما يلي الأوامر للحصول على أحدث صورة وتشغيلها:
|
||||
|
||||
```bash
|
||||
# قم بتعيين اسم الصورة بوصفه متغير
|
||||
t=ultralytics/ultralytics:latest
|
||||
|
||||
# اسحب أحدث صورة ultralytics من Docker Hub
|
||||
sudo docker pull $t
|
||||
|
||||
# قم بتشغيل صورة ultralytics في حاوية مع دعم GPU
|
||||
sudo docker run -it --ipc=host --gpus all $t # all GPUs
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # قد يتم تحديد GPUs
|
||||
```
|
||||
|
||||
يقوم الأمر أعلاه بتهيئة حاوية Docker بأحدث صورة `ultralytics`. يُسند العلامة `-it` جهازًا افتراضيًا TTY ويحافظ على فتح stdin لتمكينك من التفاعل مع الحاوية. تعيين العلامة `--ipc=host` مساحة اسم IPC (Inter-Process Communication) إلى المضيف، وهو أمر ضروري لمشاركة الذاكرة بين العمليات. تُمكّن العلامة `--gpus all` الوصول إلى كل وحدات المعالجة المركزية الرسومية المتاحة داخل الحاوية، مما هو أمر حاسم للمهام التي تتطلب حسابات GPU.
|
||||
|
||||
ملاحظة: للعمل مع الملفات على جهازك المحلي داخل الحاوية، استخدم مجلدات Docker لتوصيل دليل محلي بالحاوية:
|
||||
|
||||
```bash
|
||||
# مجلد الدليل المحلي بالحاوية
|
||||
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
|
||||
```
|
||||
|
||||
قم بتغيير `/path/on/host` بمسار الدليل على جهازك المحلي، و `/path/in/container` باالمسار المطلوب داخل حاوية Docker للوصول إليه.
|
||||
|
||||
للاستفادة القصوى من استخدام Docker المتقدم، لا تتردد في استكشاف [دليل Ultralytics Docker](https://docs.ultralytics.com/guides/docker-quickstart/).
|
||||
|
||||
راجع ملف `requirements.txt` الخاص بـ `ultralytics` [هنا](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) للحصول على قائمة المتطلبات. يُرجى ملاحظة أن جميع الأمثلة أعلاه يتم تثبيت جميع المتطلبات المطلوبة.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/_a7cVL9hqnk"
|
||||
title="YouTube player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> دليل فتع Ultralytics YOLO السريع
|
||||
</p>
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
يختلف متطلبات PyTorch حسب نظام التشغيل ومتطلبات CUDA، لذا يُوصَى بتثبيت PyTorch أولاً باستخدام التعليمات الموجودة في [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
|
||||
|
||||
<a href="https://pytorch.org/get-started/locally/">
|
||||
<img width="800" alt="PyTorch تعليمات التثبيت" src="https://user-images.githubusercontent.com/26833433/228650108-ab0ec98a-b328-4f40-a40d-95355e8a84e3.png">
|
||||
</a>
|
||||
|
||||
## استخدم Ultralytics مع واجهة سطر الأوامر (CLI)
|
||||
|
||||
تتيح واجهة سطر الأوامر (CLI) في Ultralytics تشغيل أوامر بسيطة بدون الحاجة إلى بيئة Python. لا تحتاج CLI إلى أي تخصيص أو كود Python. يمكنك ببساطة تشغيل جميع المهام من الطرفية باستخدام الأمر `yolo`. تحقق من [دليل CLI](/../usage/cli.md) لمعرفة المزيد حول استخدام YOLOv8 من سطر الأوامر.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "الصيغة"
|
||||
تستخدم أوامر Ultralytics `yolo` الصيغة التالية:
|
||||
```bash
|
||||
yolo TASK MODE ARGS
|
||||
```
|
||||
|
||||
- `TASK` (اختياري) أحد التالي ([detect](tasks/detect.md), [segment](tasks/segment.md), [classify](tasks/classify.md), [pose](tasks/pose.md))
|
||||
- `MODE` (مطلوب) واحد من ([train](modes/train.md), [val](modes/val.md), [predict](modes/predict.md), [export](modes/export.md), [track](modes/track.md))
|
||||
- `ARGS` (اختياري) أزواج "arg=value" مثل `imgsz=640` التي تستبدل القيم الافتراضية.
|
||||
|
||||
راجع جميع `ARGS` [هنا](/../usage/cfg.md) أو باستخدام الأمر `yolo cfg` في سطر الأوامر.
|
||||
|
||||
=== "التدريب"
|
||||
قم بتدريب نموذج اكتشاف لمدة 10 حلقات مع سعر تعلم بدءي 0.01
|
||||
```bash
|
||||
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||
```
|
||||
|
||||
=== "التنبؤ"
|
||||
تنبؤ بفيديو YouTube باستخدام نموذج تجزئة معتمد مسبقًا عند حجم الصورة 320:
|
||||
```bash
|
||||
yolo predict model=yolov8n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
|
||||
```
|
||||
|
||||
=== "التحقق"
|
||||
التحقق من نموذج اكتشاف معتمد مسبقًا على دُفعَة واحدة وحجم صورة قدره 640:
|
||||
```bash
|
||||
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||
```
|
||||
|
||||
=== "التصدير"
|
||||
قم بتصدير نموذج فئة YOLOv8n إلى تنسيق ONNX على حجم صورة 224 بواسطة 128 (لا يلزم TASK)
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
|
||||
```
|
||||
|
||||
=== "خاص"
|
||||
قم بتشغيل أوامر خاصة لعرض الإصدارة وعرض الإعدادات وتشغيل عمليات التحقق والمزيد:
|
||||
```bash
|
||||
yolo help
|
||||
yolo checks
|
||||
yolo version
|
||||
yolo settings
|
||||
yolo copy-cfg
|
||||
yolo cfg
|
||||
```
|
||||
|
||||
!!! Warning "تحذير"
|
||||
يجب تمرير الوسوم كأزواج "arg=val"، وأن تُفصل بعلامة تساوي `=` وأن تُفصل بمسافات بين الأزواج. لا تستخدم بادئات الوسوم `--` أو فواصل `,` بين الوسوم.
|
||||
|
||||
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
|
||||
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌ (مفقود العلامة المساواة)
|
||||
- `yolo predict model=yolov8n.pt, imgsz=640, conf=0.25` ❌ (لا تستخدم `,`)
|
||||
- `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌ (لا تستخدم `--`)
|
||||
|
||||
[دليل CLI](/../usage/cli.md){ .md-button }
|
||||
|
||||
## استخدم Ultralytics مع Python
|
||||
|
||||
تسمح واجهة Python في YOLOv8 بالتكامل السلس في مشاريع Python الخاصة بك، مما يجعل من السهل تحميل النموذج وتشغيله ومعالجة نتائجه. المصممة ببساطة وسهولة الاستخدام في الاعتبار، تمكن واجهة Python المستخدمين من تنفيذ الكشف على الكائنات والتجزئة والتصنيف في مشاريعهم. يجعل هذا واجهة YOLOv8 Python أداة قيمة لأي شخص يرغب في دمج هذه الوظائف في مشاريعهم باسياتو.
|
||||
|
||||
على سبيل المثال، يمكن للمستخدمين تحميل نموذج، تدريبه، تقييم أدائه على مجموعة التحقق، وحتى تصديره إلى تنسيق ONNX ببضعة أسطر فقط من الشفرة. تحقق من [دليل Python](/../usage/python.md) لمعرفة المزيد حول استخدام YOLOv8 داخل مشاريعك الخاصة.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# أنشئ نموذج YOLO جديد من البداية
|
||||
model = YOLO('yolov8n.yaml')
|
||||
|
||||
# قم بتحميل نموذج YOLO معتمد مسبقًا (موصَى به للتدريب)
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# قم بتدريب النموذج باستخدام مجموعة البيانات 'coco128.yaml' لمدة 3 حلقات
|
||||
results = model.train(data='coco128.yaml', epochs=3)
|
||||
|
||||
# قم بتقييم أداء النموذج على مجموعة التحقق
|
||||
results = model.val()
|
||||
|
||||
# قم بإجراء الكشف على صورة باستخدام النموذج
|
||||
results = model('https://ultralytics.com/images/bus.jpg')
|
||||
|
||||
# قم بتصدير النموذج إلى تنسيق ONNX
|
||||
success = model.export(format='onnx')
|
||||
```
|
||||
|
||||
[دليل Python](/../usage/python.md){.md-button .md-button--primary}
|
||||
|
||||
## إعدادات Ultralytics
|
||||
|
||||
يوفر مكتبة Ultralytics نظامًا قويًا لإدارة الإعدادات لتمكين التحكم بمحاكاة تفصيلية لتجاربك. من خلال استخدام `SettingsManager` في الوحدة `ultralytics.utils`، يمكن للمستخدمين الوصول بسهولة إلى إعداداتهم وتعديلها. يتم تخزينها في ملف YAML ويمكن عرضها أو تعديلها إما مباشرة في بيئة Python أو من خلال واجهة سطر الأوامر (CLI).
|
||||
|
||||
### فحص الإعدادات
|
||||
|
||||
للحصول على فهم للتكوين الحالي لإعداداتك، يمكنك عرضها مباشرةً:
|
||||
|
||||
!!! Example "عرض الإعدادات"
|
||||
|
||||
=== "Python"
|
||||
يُمكنك استخدام Python لعرض الإعدادات الخاصة بك. ابدأ بـاستيراد الكائن `settings` من وحدة `ultralytics`. استخدم الأوامر التالية لطباعة الإعدادات والعودة منها:
|
||||
```python
|
||||
from ultralytics import settings
|
||||
|
||||
# عرض كل الإعدادات
|
||||
print(settings)
|
||||
|
||||
# إرجاع إعداد محدد
|
||||
value = settings['runs_dir']
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
بدلاً من ذلك، واجهة سطر الأوامر تسمح لك بالتحقق من الإعدادات الخاصة بك باستخدام أمر بسيط:
|
||||
```bash
|
||||
yolo settings
|
||||
```
|
||||
|
||||
### تعديل الإعدادات
|
||||
|
||||
يسمح لك Ultralytics بتعديل الإعدادات بسهولة. يمكن تنفيذ التغييرات بالطرق التالية:
|
||||
|
||||
!!! Example "تحديث الإعدادات"
|
||||
|
||||
=== "Python"
|
||||
داخل بيئة Python، اطلب الطريقة `update` على الكائن `settings` لتغيير إعداداتك:
|
||||
|
||||
```python
|
||||
from ultralytics import settings
|
||||
|
||||
# تحديث إعداد واحد
|
||||
settings.update({'runs_dir': '/path/to/runs'})
|
||||
|
||||
# تحديث إعدادات متعددة
|
||||
settings.update({'runs_dir': '/path/to/runs', 'tensorboard': False})
|
||||
|
||||
# إعادة الإعدادات إلى القيم الافتراضية
|
||||
settings.reset()
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
إذا كنت تفضل استخدام واجهة سطر الأوامر، يمكنك استخدام الأوامر التالية لتعديل إعداداتك:
|
||||
|
||||
```bash
|
||||
# تحديث إعداد واحد
|
||||
yolo settings runs_dir='/path/to/runs'
|
||||
|
||||
# تحديث إعدادات متعددة
|
||||
yolo settings runs_dir='/path/to/runs' tensorboard=False
|
||||
|
||||
# إعادة الإعدادات إلى القيم الافتراضية
|
||||
yolo settings reset
|
||||
```
|
||||
|
||||
### فهم الإعدادات
|
||||
|
||||
يوفر الجدول أدناه نظرة عامة على الإعدادات المتاحة للضبط في Ultralytics. يتم توضيح كل إعداد بالإضافة إلى قيمة مثالية ونوع البيانات ووصف موجز.
|
||||
|
||||
| الاسم | القيمة المثالية | نوع البيانات | الوصف |
|
||||
|--------------------|-----------------------|--------------|-------------------------------------------------------------------------------------------------------------|
|
||||
| `settings_version` | `'0.0.4'` | `str` | إصدار إعدادات Ultralytics (مختلف عن إصدار Ultralytics [pip](https://pypi.org/project/ultralytics/)) |
|
||||
| `datasets_dir` | `'/path/to/datasets'` | `str` | المسار الذي يتم تخزينه فيه مجموعات البيانات |
|
||||
| `weights_dir` | `'/path/to/weights'` | `str` | المسار الذي يتم تخزينه فيه أوزان النموذج |
|
||||
| `runs_dir` | `'/path/to/runs'` | `str` | المسار الذي يتم تخزينه فيه تشغيل التجارب |
|
||||
| `uuid` | `'a1b2c3d4'` | `str` | مُعرِّف فريد لإعدادات الحالية |
|
||||
| `sync` | `True` | `bool` | ما إذا كان يتم مزامنة التحليلات وحوادث الأعطال إلى HUB |
|
||||
| `api_key` | `''` | `str` | HUB الخاص بـ Ultralytics [API Key](https://hub.ultralytics.com/settings?tab=api+keys) |
|
||||
| `clearml` | `True` | `bool` | ما إذا كان يتم استخدام ClearML لتسجيل التجارب |
|
||||
| `comet` | `True` | `bool` | ما إذا كان يتم استخدام [Comet ML](https://bit.ly/yolov8-readme-comet) لتتبع وتصور التجارب |
|
||||
| `dvc` | `True` | `bool` | ما إذا كان يتم استخدام [DVC لتتبع التجارب](https://dvc.org/doc/dvclive/ml-frameworks/yolo) والتحكم في النسخ |
|
||||
| `hub` | `True` | `bool` | ما إذا كان يتم استخدام [Ultralytics HUB](https://hub.ultralytics.com) للتكامل |
|
||||
| `mlflow` | `True` | `bool` | ما إذا كان يتم استخدام MLFlow لتتبع التجارب |
|
||||
| `neptune` | `True` | `bool` | ما إذا كان يتم استخدام Neptune لتتبع التجارب |
|
||||
| `raytune` | `True` | `bool` | ما إذا كان يتم استخدام Ray Tune لضبط الحساسية |
|
||||
| `tensorboard` | `True` | `bool` | ما إذا كان يتم استخدام TensorBoard للتصور |
|
||||
| `wandb` | `True` | `bool` | ما إذا كان يتم استخدام Weights & Biases لتسجيل البيانات |
|
||||
|
||||
أثناء تنقلك في مشاريعك أو تجاربك، تأكد من مراجعة هذه الإعدادات لضمان تكوينها بشكل مثالي وفقًا لاحتياجاتك.
|
||||
|
|
@ -1,172 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعرّف على نماذج YOLOv8 Classify لتصنيف الصور. احصل على معلومات مفصلة حول قائمة النماذج المدرّبة مسبقًا وكيفية التدريب والتحقق والتنبؤ وتصدير النماذج.
|
||||
keywords: Ultralytics، YOLOv8، تصنيف الصور، النماذج المدربة مسبقًا، YOLOv8n-cls، التدريب، التحقق، التنبؤ، تصدير النماذج
|
||||
---
|
||||
|
||||
# تصنيف الصور
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418606-adf35c62-2e11-405d-84c6-b84e7d013804.png" alt="أمثلة على تصنيف الصور">
|
||||
|
||||
تعتبر عملية تصنيف الصور أبسط المهام الثلاثة وتنطوي على تصنيف صورة كاملة في إحدى الفئات المحددة سابقًا.
|
||||
|
||||
ناتج نموذج تصنيف الصور هو تسمية فئة واحدة ودرجة ثقة. يكون تصنيف الصور مفيدًا عندما تحتاج فقط إلى معرفة فئة الصورة ولا تحتاج إلى معرفة موقع الكائنات التابعة لتلك الفئة أو شكلها الدقيق.
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
تستخدم نماذج YOLOv8 Classify اللاحقة "-cls"، مثالًا "yolov8n-cls.pt" وتم تدريبها على [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml).
|
||||
|
||||
## [النماذج](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
تظهر هنا النماذج المدرّبة مسبقًا لـ YOLOv8 للتصنيف. تم تدريب نماذج الكشف والشعبة والموضع على مجموعة البيانات [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)، بينما تم تدريب نماذج التصنيف مسبقًا على مجموعة البيانات [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml).
|
||||
|
||||
يتم تنزيل [النماذج](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) تلقائيًا من أحدث إصدار لـ Ultralytics [releases](https://github.com/ultralytics/assets/releases) عند الاستخدام الأول.
|
||||
|
||||
| النموذج | الحجم<br><sup>(بكسل) | دقة (أعلى 1)<br><sup>acc | دقة (أعلى 5)<br><sup>acc | سرعة التنفيذ<br><sup>ONNX للوحدة المركزية<br>(مللي ثانية) | سرعة التنفيذ<br><sup>A100 TensorRT<br>(مللي ثانية) | المعلمات<br><sup>(مليون) | FLOPs<br><sup>(مليار) لحجم 640 |
|
||||
|----------------------------------------------------------------------------------------------|----------------------|--------------------------|--------------------------|-----------------------------------------------------------|----------------------------------------------------|--------------------------|--------------------------------|
|
||||
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
|
||||
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
|
||||
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
|
||||
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
|
||||
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
|
||||
|
||||
- قيمة **acc** هي دقة النماذج على مجموعة بيانات التحقق [ImageNet](https://www.image-net.org/).
|
||||
<br>لإعادة إنتاج ذلك، استخدم `yolo val classify data=path/to/ImageNet device=0`
|
||||
- يتم حساب سرعة **Speed** بناءً على متوسط صور التحقق من ImageNet باستخدام [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/).
|
||||
<br>لإعادة إنتاج ذلك، استخدم `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`
|
||||
|
||||
## التدريب
|
||||
|
||||
قم بتدريب YOLOv8n-cls على مجموعة بيانات MNIST160 لمدة 100 دورة عند حجم الصورة 64 بكسل. للحصول على قائمة كاملة بالوسائط المتاحة، اطلع على صفحة [تكوين](/../usage/cfg.md).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج
|
||||
model = YOLO('yolov8n-cls.yaml') # إنشاء نموذج جديد من نموذج YAML
|
||||
model = YOLO('yolov8n-cls.pt') # تحميل نموذج مدرّب مسبقًا (موصى به للتدريب)
|
||||
model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # إنشاء من YAML ونقل الأوزان
|
||||
|
||||
# تدريب النموذج
|
||||
results = model.train(data='mnist160', epochs=100, imgsz=64)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# إنشاء نموذج جديد من YAML وبدء التدريب من البداية
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.yaml epochs=100 imgsz=64
|
||||
|
||||
# بدء التدريب من نموذج مدرّب بصيغة pt
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64
|
||||
|
||||
# إنشاء نموذج جديد من YAML ونقل الأوزان المدرّبة مسبقًا وبدء التدريب
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.yaml pretrained=yolov8n-cls.pt epochs=100 imgsz=64
|
||||
```
|
||||
|
||||
### تنسيق مجموعة البيانات
|
||||
|
||||
يمكن العثور على تنسيق مجموعة بيانات تصنيف YOLO بالتفصيل في [مرشد المجموعة](../../../datasets/classify/index.md).
|
||||
|
||||
## التحقق
|
||||
|
||||
قم بتحديد دقة النموذج YOLOv8n-cls المدرّب على مجموعة بيانات MNIST160. لا يلزم تمرير أي وسيطة حيث يحتفظ `model` ببيانات التدريب والوسائط كسمات النموذج.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج
|
||||
model = YOLO('yolov8n-cls.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مخصص
|
||||
|
||||
# التحقق من النموذج
|
||||
metrics = model.val() # لا تحتاج إلى وسائط، يتم تذكر مجموعة البيانات والإعدادات النموذج
|
||||
metrics.top1 # دقة أعلى 1
|
||||
metrics.top5 # دقة أعلى 5
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo classify val model=yolov8n-cls.pt # تحقق من النموذج الرسمي
|
||||
yolo classify val model=path/to/best.pt # تحقق من النموذج المخصص
|
||||
```
|
||||
|
||||
## التنبؤ
|
||||
|
||||
استخدم نموذج YOLOv8n-cls المدرّب لتنفيذ تنبؤات على الصور.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج
|
||||
model = YOLO('yolov8n-cls.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مخصص
|
||||
|
||||
# تنبؤ باستخدام النموذج
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # تنبؤ على صورة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' # تنبؤ باستخدام النموذج الرسمي
|
||||
yolo classify predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # تنبؤ باستخدام النموذج المخصص
|
||||
```
|
||||
|
||||
راجع تفاصيل كاملة حول وضع `predict` في الصفحة [Predict](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## تصدير
|
||||
|
||||
قم بتصدير نموذج YOLOv8n-cls إلى تنسيق مختلف مثل ONNX، CoreML، وما إلى ذلك.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل نموذج
|
||||
model = YOLO('yolov8n-cls.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مدرّب مخصص
|
||||
|
||||
# تصدير النموذج
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx # تصدير النموذج الرسمي
|
||||
yolo export model=path/to/best.pt format=onnx # تصدير نموذج مدرّب مخصص
|
||||
```
|
||||
|
||||
تتوفر صيغ تصدير YOLOv8-cls في الجدول أدناه. يمكنك تنبؤ أو التحقق من الصحة مباشرةً على النماذج المصدر، أي "yolo predict model=yolov8n-cls.onnx". يتم عرض أمثلة لاستخدام النموذج الخاص بك بعد الانتهاء من التصدير.
|
||||
|
||||
| الصيغة | وسيطة الصيغة | النموذج | البيانات الوصفية | الوسيطات |
|
||||
|--------------------------------------------------------------------|---------------|-------------------------------|------------------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-cls.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-cls.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-cls.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-cls_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-cls.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-cls.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-cls_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-cls.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-cls.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-cls_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-cls_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-cls_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-cls_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
راجع التفاصيل الكاملة حول `export` في الصفحة [Export](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1,185 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: وثائق رسمية لـ YOLOv8 بواسطة Ultralytics. تعلم كيفية تدريب و التحقق من صحة و التنبؤ و تصدير النماذج بتنسيقات مختلفة. تتضمن إحصائيات الأداء التفصيلية.
|
||||
keywords: YOLOv8, Ultralytics, التعرف على الكائنات, النماذج المدربة من قبل, التدريب, التحقق من الصحة, التنبؤ, تصدير النماذج, COCO, ImageNet, PyTorch, ONNX, CoreML
|
||||
---
|
||||
|
||||
# التعرف على الكائنات
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418624-5785cb93-74c9-4541-9179-d5c6782d491a.png" alt="Beispiele für die Erkennung von Objekten">
|
||||
|
||||
Task التعرف على الكائنات هو عبارة عن تعرف على موقع و فئة الكائنات في صورة أو فيديو.
|
||||
|
||||
مخرجات جهاز الاستشعار هي مجموعة من مربعات تحيط بالكائنات في الصورة، مع تصنيف الفئة ودرجات وثقة لكل مربع. التعرف على الكائنات هو اختيار جيد عندما تحتاج إلى تحديد كائنات مهمة في مشهد، ولكنك لا تحتاج إلى معرفة بالضبط أين يكمن الكائن أو شكله الدقيق.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/5ku7npMrW40?si=6HQO1dDXunV8gekh"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> التعرف على الكائنات باستخدام نموذج Ultralytics YOLOv8 مع تدريب مسبق.
|
||||
</p>
|
||||
|
||||
!!! Tip "تلميح"
|
||||
|
||||
نماذج YOLOv8 Detect هي النماذج الافتراضية YOLOv8، أي `yolov8n.pt` و هي مدربة مسبقًا على [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
|
||||
|
||||
## [النماذج](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
تُعرض هنا النماذج المدربة مسبقًا لـ YOLOv8 Detect. النماذج Detect و Segment و Pose معتمدة على مجموعة البيانات [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)، بينما النماذج Classify معتمدة على مجموعة البيانات [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml).
|
||||
|
||||
تُقوم النماذج بالتنزيل تلقائيًا من أحدث [إصدار Ultralytics](https://github.com/ultralytics/assets/releases) عند الاستخدام لأول مرة.
|
||||
|
||||
| النموذج | الحجم<br><sup>(بكسل) | mAP<sup>val<br>50-95 | السرعة<br><sup>CPU ONNX<br>(مللي ثانية) | السرعة<br><sup>A100 TensorRT<br>(مللي ثانية) | الوزن<br><sup>(ميغا) | FLOPs<br><sup>(مليار) |
|
||||
|--------------------------------------------------------------------------------------|----------------------|----------------------|-----------------------------------------|----------------------------------------------|----------------------|-----------------------|
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
|
||||
|
||||
- قيم mAP<sup>val</sup> تنطبق على مقياس نموذج واحد-مقياس واحد على مجموعة بيانات [COCO val2017](http://cocodataset.org).
|
||||
<br>اعيد حسابها بواسطة `yolo val detect data=coco.yaml device=0`
|
||||
- السرعةتمت متوسطة على صور COCO val باستخدام [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||
instance.
|
||||
<br>اعيد حسابها بواسطة `yolo val detect data=coco128.yaml batch=1 device=0|cpu`
|
||||
|
||||
## تدريب
|
||||
|
||||
قم بتدريب YOLOv8n على مجموعة البيانات COCO128 لمدة 100 دورة على حجم صورة 640. للحصول على قائمة كاملة بالوسائط المتاحة انظر الصفحة [التكوين](/../usage/cfg.md).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل نموذج
|
||||
model = YOLO('yolov8n.yaml') # بناء نموذج جديد من YAML
|
||||
model = YOLO('yolov8n.pt') # قم بتحميل نموذج مدرب مسبقًا (موصى به للتدريب)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # بناء من YAML و نقل الأوزان
|
||||
|
||||
# قم بتدريب النموذج
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# قم ببناء نموذج جديد من YAML وابدأ التدريب من الصفر
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# ابدأ التدريب من نموذج *.pt مدرب مسبقًا
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# بناء نموذج جديد من YAML، ونقل الأوزان المدربة مسبقاً إلى النموذج وابدأ التدريب
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### تنسيق مجموعة بيانات
|
||||
|
||||
يمكن العثور على تنسيق مجموعة بيانات التعرف على الكائنات بالتفصيل في [دليل مجموعة البيانات](../../../datasets/detect/index.md). لتحويل مجموعة البيانات الحالية من تنسيقات أخرى (مثل COCO الخ) إلى تنسيق YOLO، يرجى استخدام أداة [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) المقدمة من Ultralytics.
|
||||
|
||||
## التحقق من الصحة
|
||||
|
||||
قم بتحقق من دقة النموذج المدرب مسبقًا YOLOv8n على مجموعة البيانات COCO128. ليس هناك حاجة إلى تمرير أي وسيطات حيث يحتفظ النموذج ببياناته التدريبية والوسيطات كسمات النموذج.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل نموذج
|
||||
model = YOLO('yolov8n.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مخصص
|
||||
|
||||
# قم بالتحقق من النموذج
|
||||
metrics = model.val() # لا حاجة لأي بيانات، يتذكر النموذج بيانات التدريب و الوسيطات
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # قائمة تحتوي map50-95 لكل فئة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # التحقق من النموذج الرسمي
|
||||
yolo detect val model=path/to/best.pt # التحقق من النموذج المخصص
|
||||
```
|
||||
|
||||
## التنبؤ
|
||||
|
||||
استخدم نموذج YOLOv8n المدرب مسبقًا لتشغيل التنبؤات على الصور.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل نموذج
|
||||
model = YOLO('yolov8n.pt') # قم بتحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # قم بتحميل نموذج مخصص
|
||||
|
||||
# أجرِ التنبؤ باستخدام النموذج
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # التنبؤ على صورة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # التنبؤ باستخدام النموذج الرسمي
|
||||
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # التنبؤ بالنموذج المخصص
|
||||
```
|
||||
|
||||
انظر تفاصيل وضع الـ `predict` الكامل في صفحة [Predict](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## تصدير
|
||||
|
||||
قم بتصدير نموذج YOLOv8n إلى تنسيق مختلف مثل ONNX، CoreML وغيرها.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل نموذج
|
||||
model = YOLO('yolov8n.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مدرب مخصص
|
||||
|
||||
# قم بتصدير النموذج
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # تصدير النموذج الرسمي
|
||||
yolo export model=path/to/best.pt format=onnx # تصدير النموذج المدرب مخصص
|
||||
```
|
||||
|
||||
التنسيقات المدعومة لتصدير YOLOv8 مدرجة في الجدول أدناه. يمكنك التنبؤ أو التحقق من صحة النماذج المصدرة مباشرة، على سبيل المثال `yolo predict model=yolov8n.onnx`. سيتم عرض أمثلة استخدام لنموذجك بعد اكتمال التصدير.
|
||||
|
||||
| الشكل | مسافة `format` | النموذج | بيانات الوصف | وسيطات |
|
||||
|--------------------------------------------------------------------|----------------|---------------------------|--------------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - أو | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras`, `int8` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
انظر تفاصيل كاملة للـ `export` في صفحة [Export](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1,55 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعرّف على المهام الأساسية لتقنية YOLOv8 للرؤية الحاسوبية والتي تشمل الكشف، التجزئة، التصنيف وتقدير الوضعية. تعرف على استخداماتها في مشاريع الذكاء الاصطناعي الخاصة بك.
|
||||
keywords: Ultralytics، YOLOv8، الكشف، التجزئة، التصنيف، تقدير الوضعية، الإطار الذكي للذكاء الاصطناعي، المهام الرؤية الحاسوبية
|
||||
---
|
||||
|
||||
# مهام Ultralytics YOLOv8
|
||||
|
||||
<br>
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/im/banner-tasks.png" alt="مهام Ultralytics YOLOv8 المدعومة">
|
||||
|
||||
YOLOv8 هو إطار ذكاء اصطناعي يدعم عدة **مهام** للرؤية الحاسوبية. يمكن استخدام الإطار لأداء [الكشف](detect.md)، [التجزئة](segment.md)، [التصنيف](classify.md)، و[تقدير الوضعية](pose.md). كل من هذه المهام لها هدف مختلف واستخدام محدد.
|
||||
|
||||
!!! Note "ملاحظة"
|
||||
|
||||
🚧 يجري بناء وثائقنا متعددة اللغات حاليًا، ونعمل جاهدين على تحسينها. شكرًا لصبرك! 🙏
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/NAs-cfq9BDw"
|
||||
title="مشغل فيديو يوتيوب" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> استكشف مهام Ultralytics YOLO: كشف الكائنات، التجزئة، التتبع وتقدير الوضعية.
|
||||
</p>
|
||||
|
||||
## [الكشف](detect.md)
|
||||
|
||||
الكشف هو المهمة الأساسية المدعومة بواسطة YOLOv8. يتضمن الكشف اكتشاف الكائنات في صورة أو إطار فيديو ورسم مربعات محيطة حولها. يتم تصنيف الكائنات المكتشفة إلى فئات مختلفة استنادًا إلى ميزاتها. يمكن لـ YOLOv8 اكتشاف أكثر من كائن واحد في صورة أو إطار فيديو واحد بدقة وسرعة عالية.
|
||||
|
||||
[أمثلة للكشف](detect.md){ .md-button }
|
||||
|
||||
## [التجزئة](segment.md)
|
||||
|
||||
التجزئة هي مهمة تتضمن تقسيم صورة إلى مناطق مختلفة استنادًا إلى محتوى الصورة. يتم تعيين علامة لكل منطقة استنادًا إلى محتواها. تعتبر هذه المهمة مفيدة في تطبيقات مثل تجزئة الصور وتصوير الطبية. يستخدم YOLOv8 نسخة معدلة من هندسة U-Net لأداء التجزئة.
|
||||
|
||||
[أمثلة للتجزئة](segment.md){ .md-button }
|
||||
|
||||
## [التصنيف](classify.md)
|
||||
|
||||
التصنيف هو مهمة تتضمن تصنيف صورة إلى فئات مختلفة. يمكن استخدام YOLOv8 لتصنيف الصور استنادًا إلى محتواها. يستخدم نسخة معدلة من هندسة EfficientNet لأداء التصنيف.
|
||||
|
||||
[أمثلة للتصنيف](classify.md){ .md-button }
|
||||
|
||||
## [تقدير الوضعية](pose.md)
|
||||
|
||||
تقدير الوضعية/النقاط الرئيسية هو مهمة تتضمن اكتشاف نقاط محددة في صورة أو إطار فيديو. يُشار إلى هذه النقاط بمصطلح النقاط الرئيسية وتُستخدم لتتبع الحركة أو تقدير الوضعية. يمكن لـ YOLOv8 اكتشاف النقاط الرئيسية في صورة أو إطار فيديو بدقة وسرعة عالية.
|
||||
|
||||
[أمثلة لتقدير الوضعية](pose.md){ .md-button }
|
||||
|
||||
## الاستنتاج
|
||||
|
||||
يدعم YOLOv8 مهام متعددة، بما في ذلك الكشف، التجزئة، التصنيف، وكشف النقاط الرئيسية. لكل من هذه المهام أهداف واستخدامات مختلفة. عن طريق فهم الاختلافات بين هذه المهام، يمكنك اختيار المهمة المناسبة لتطبيق الرؤية الحاسوبية الخاص بك.
|
||||
|
|
@ -1,186 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعرّف على كيفية استخدام Ultralytics YOLOv8 لمهام تقدير الوضعية. اعثر على نماذج مدرّبة مسبقًا، وتعلم كيفية التدريب والتحقق والتنبؤ وتصدير نموذجك الخاص.
|
||||
keywords: Ultralytics، YOLO، YOLOv8، تقدير الوضعية ، كشف نقاط المفاتيح ، كشف الكائنات ، نماذج مدرّبة مسبقًا ، تعلم الآلة ، الذكاء الاصطناعي
|
||||
---
|
||||
|
||||
# تقدير الوضعية
|
||||
|
||||
تقدير الوضعية هو مهمة تنطوي على تحديد موقع نقاط محددة في الصورة ، وعادةً ما يشار إليها بنقاط الوضوح. يمكن أن تمثل نقاط الوضوح أجزاءً مختلفةً من الكائن مثل المفاصل أو العلامات المميزة أو الميزات البارزة الأخرى. عادةً ما يتم تمثيل مواقع نقاط الوضوح كمجموعة من الإحداثيات 2D `[x ، y]` أو 3D `[x ، y ، visible]`.
|
||||
|
||||
يكون ناتج نموذج تقدير الوضعية مجموعة من النقاط التي تمثل نقاط الوضوح على كائن في الصورة ، عادةً مع نقاط الثقة لكل نقطة. تقدير الوضعية هو خيار جيد عندما تحتاج إلى تحديد أجزاء محددة من كائن في مشهد، وموقعها بالنسبة لبعضها البعض.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/Y28xXQmju64?si=pCY4ZwejZFu6Z4kZ"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>شاهد:</strong> تقدير الوضعية مع Ultralytics YOLOv8.
|
||||
</p>
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
النماذج التي تحتوي على البادئة "-pose" تستخدم لنماذج YOLOv8 pose ، على سبيل المثال `yolov8n-pose.pt`. هذه النماذج مدربة على [مجموعة بيانات نقاط الوضوح COCO]("https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml") وهي مناسبة لمجموعة متنوعة من مهام تقدير الوضعية.
|
||||
|
||||
## [النماذج]("https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8")
|
||||
|
||||
تعرض نماذج مدرّبة مسبقًا لـ YOLOv8 التي تستخدم لتقدير الوضعية هنا. النماذج للكشف والشريحة والوضعية يتم تدريبها على [مجموعة بيانات COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)، بينما تتم تدريب نماذج التصنيف على مجموعة بيانات ImageNet.
|
||||
|
||||
يتم تنزيل النماذج من [آخر إصدار Ultralytics]("https://github.com/ultralytics/assets/releases") تلقائيًا عند استخدامها لأول مرة.
|
||||
|
||||
| النموذج | الحجم (بالبكسل) | mAP<sup>الوضعية 50-95 | mAP<sup>الوضعية 50 | سرعة<sup>الوحدة المركزية ONNX<sup>(ms) | سرعة<sup>A100 TensorRT<sup>(ms) | المعلمات (مليون) | FLOPs (بالمليار) |
|
||||
|------------------------------------------------------------------------------------------------------|-----------------|-----------------------|--------------------|----------------------------------------|---------------------------------|------------------|------------------|
|
||||
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
|
||||
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
|
||||
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
|
||||
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
|
||||
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
|
||||
|
||||
- تعتبر القيم **mAP<sup>val</sup>** لنموذج واحد ومقياس واحد فقط على [COCO Keypoints val2017](http://cocodataset.org)
|
||||
مجموعة البيانات.
|
||||
<br>يمكن إعادة إنتاجه بواسطة `يولو val pose data=coco-pose.yaml device=0`
|
||||
- يتم حساب **السرعة** من خلال متوسط صور COCO val باستخدام [المروحة الحرارية Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||
مثيل.
|
||||
<br>يمكن إعادة إنتاجه بواسطة `يولو val pose data=coco8-pose.yaml batch=1 device=0|cpu`
|
||||
|
||||
## التدريب
|
||||
|
||||
يتم تدريب نموذج YOLOv8-pose على مجموعة بيانات COCO128-pose.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n-pose.yaml') # بناء نموذج جديد من ملف YAML
|
||||
model = YOLO('yolov8n-pose.pt') # تحميل نموذج مدرّب مسبقًا (موصى به للتدريب)
|
||||
model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # بناء نموذج من YAML ونقل الوزن
|
||||
|
||||
# تدريب النموذج
|
||||
results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# بناء نموذج جديد من YAML وبدء التدريب من البداية.
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640
|
||||
|
||||
# البدء في التدريب من نموذج مدرب مسبقًا *.pt
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
|
||||
# بناء نموذج جديد من YAML ، ونقل الأوزان المدرّبة مسبقًا إليه ، والبدء في التدريب.
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml pretrained=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### تنسيق مجموعة البيانات
|
||||
|
||||
يمكن العثور على تنسيق مجموعات بيانات نقاط الوضوح YOLO في [دليل المجموعة البيانات](../../../datasets/pose/index.md). لتحويل مجموعة البيانات الحالية التي لديك من تنسيقات أخرى (مثل COCO إلخ) إلى تنسيق YOLO ، يرجى استخدام أداة [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) من Ultralytics.
|
||||
|
||||
## التحقق من الصحة
|
||||
|
||||
تحقق من دقة نموذج YOLOv8n-pose المدرّب على مجموعة بيانات COCO128-pose. لا يلزم تمرير سبب ما كوسيط إلى `model`
|
||||
عند استدعاء.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n-pose.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مخصص
|
||||
|
||||
# التحقق من النموذج
|
||||
metrics = model.val() # لا يوجد حاجة لأي سبب، يتذكر النموذج البيانات والوسائط كمجالات للنموذج
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # قائمة تحتوي على map50-95 لكل فئة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo pose val model=yolov8n-pose.pt # التحقق من النموذج الرسمي
|
||||
yolo pose val model=path/to/best.pt # التحقق من النموذج المخصص
|
||||
```
|
||||
|
||||
## التنبؤ
|
||||
|
||||
استخدم نموذج YOLOv8n-pose المدرّب لتشغيل توقعات على الصور.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n-pose.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مخصص
|
||||
|
||||
# التنبؤ باستخدام النموذج
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # التنبؤ بصورة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg' # التنبؤ باستخدام النموذج الرسمي
|
||||
yolo pose predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # التنبؤ باستخدام النموذج المخصص
|
||||
```
|
||||
|
||||
انظر تفاصيل `predict` كاملة في [صفحة التنبؤ](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## التصدير
|
||||
|
||||
قم بتصدير نموذج YOLOv8n-pose إلى تنسيق مختلف مثل ONNX، CoreML، الخ.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# تحميل النموذج
|
||||
model = YOLO('yolov8n-pose.pt') # تحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # تحميل نموذج مدرب مخصص
|
||||
|
||||
# تصدير النموذج
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-pose.pt format=onnx # تصدير نموذج رسمي
|
||||
yolo export model=path/to/best.pt format=onnx # تصدير نموذج مخصص
|
||||
```
|
||||
|
||||
تتوفر تنسيقات تصدير YOLOv8-pose في الجدول أدناه. يمكنك التنبؤ أو التحقق مباشرةً على النماذج المصدرة ، على سبيل المثال `yolo predict model=yolov8n-pose.onnx`. توجد أمثلة استخدام متاحة لنموذجك بعد اكتمال عملية التصدير.
|
||||
|
||||
| تنسيق | إجراء `format` | النموذج | البيانات الوصفية | الوسائط |
|
||||
|--------------------------------------------------------------------|----------------|--------------------------------|------------------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-pose.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-pose.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-pose.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-pose_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-pose.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-pose.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-pose_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-pose.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-pose.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-pose_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-pose_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-pose_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-pose_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
انظر تفاصيل `export` كاملة في [صفحة التصدير](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1,189 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: تعلم كيفية استخدام نماذج فصل الأشكال الفردية مع Ultralytics YOLO. تعليمات حول التدريب والتحقق من الصحة وتوقع الصورة وتصدير النموذج.
|
||||
keywords: yolov8 ، فصل الأشكال الفردية ، Ultralytics ، مجموعة بيانات COCO ، تجزئة الصورة ، كشف الكائنات ، تدريب النموذج ، التحقق من صحة النموذج ، توقع الصورة ، تصدير النموذج
|
||||
---
|
||||
|
||||
# فصل الأشكال الفردية
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418644-7df320b8-098d-47f1-85c5-26604d761286.png" alt="أمثلة على فصل الأشكال الفردية">
|
||||
|
||||
يذهب فصل الأشكال الفردية خطوة أبعد من كشف الكائنات وينطوي على تحديد الكائنات الفردية في صورة وتجزيئها عن بقية الصورة.
|
||||
|
||||
ناتج نموذج فصل الأشكال الفردية هو مجموعة من الأقنعة أو الحدود التي تحدد كل كائن في الصورة ، جنبًا إلى جنب مع تصنيف الصنف ونقاط الثقة لكل كائن. يكون فصل الأشكال الفردية مفيدًا عندما تحتاج إلى معرفة ليس فقط أين توجد الكائنات في الصورة ، ولكن أيضًا ما هو شكلها الدقيق.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/o4Zd-IeMlSY?si=37nusCzDTd74Obsp"
|
||||
title="مشغل فيديو YouTube" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>المشاهدة:</strong> تشغيل فصل الأشكال مع نموذج Ultralytics YOLOv8 مدرب مسبقًا باستخدام Python.
|
||||
</p>
|
||||
|
||||
!!! Tip "نصيحة"
|
||||
|
||||
تستخدم نماذج YOLOv8 Seg اللاحقة `-seg`، أي `yolov8n-seg.pt` وتكون مدربة مسبقًا على [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
|
||||
|
||||
## [النماذج](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
تُعرض هنا النماذج الجاهزة المدربة مسبقًا لـ YOLOv8 Segment. يتم تدريب نماذج الكشف والتجزيء والمواقف على مجموعة البيانات [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) ، بينما تدرب نماذج التصنيف على مجموعة البيانات [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml).
|
||||
|
||||
تتم تنزيل [النماذج](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) تلقائيًا من [الإصدار](https://github.com/ultralytics/assets/releases) الأخير لـ Ultralytics عند أول استخدام.
|
||||
|
||||
| النموذج | الحجم<br><sup>بكسل | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | السرعة<br><sup>CPU ONNX<br>(مللي ثانية) | السرعة<br><sup>A100 TensorRT<br>(مللي ثانية) | المعلمات<br><sup>(مليون) | FLOPs<br><sup>(مليار) |
|
||||
|----------------------------------------------------------------------------------------------|--------------------|----------------------|-----------------------|-----------------------------------------|----------------------------------------------|--------------------------|-----------------------|
|
||||
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
|
||||
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
|
||||
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
|
||||
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
|
||||
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
|
||||
|
||||
- تُستخدم قيم **mAP<sup>val</sup>** لنموذج واحد وحجم واحد على مجموعة بيانات [COCO val2017](http://cocodataset.org).
|
||||
<br>يمكن إعادة إنتاجها باستخدام `yolo val segment data=coco.yaml device=0`
|
||||
- **تُحسب السرعة** كمتوسط على صور COCO val باستخدام [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||
instance.
|
||||
<br>يمكن إعادة إنتاجها باستخدام `yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`
|
||||
|
||||
## التدريب
|
||||
|
||||
قم بتدريب YOLOv8n-seg على مجموعة بيانات COCO128-seg لمدة 100 دورة عند حجم صورة 640. للحصول على قائمة كاملة بالوسائط المتاحة ، راجع صفحة [التكوين](/../usage/cfg.md).
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل النموذج
|
||||
model = YOLO('yolov8n-seg.yaml') # قم ببناء نموذج جديد من ملف YAML
|
||||
model = YOLO('yolov8n-seg.pt') # قم بتحميل نموذج مدرب مسبقًا (موصى به للتدريب)
|
||||
model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # قم ببنائه من YAML ونقل الوزن
|
||||
|
||||
# قم بتدريب النموذج
|
||||
results = model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# قم ببناء نموذج جديد من ملف YAML وبدء التدريب من البداية
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml epochs=100 imgsz=640
|
||||
|
||||
# قم ببدء التدريب من نموذج *.pt مدرب مسبقًا
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
|
||||
# قم ببناء نموذج جديد من YAML ونقل الأوزان المدربة مسبَقًا إليه وابدأ التدريب
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml pretrained=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### تنسيق مجموعة البيانات
|
||||
|
||||
يمكن العثور على تنسيق مجموعة بيانات تجزيء YOLO بالتفصيل في [دليل مجموعة البيانات](../../../datasets/segment/index.md). لتحويل مجموعة البيانات الحالية التي تتبع تنسيقات أخرى (مثل COCO إلخ) إلى تنسيق YOLO ، يُرجى استخدام أداة [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) من Ultralytics.
|
||||
|
||||
## التحقق من الصحة
|
||||
|
||||
قم بالتحقق من دقة نموذج YOLOv8n-seg المدرب على مجموعة بيانات COCO128-seg. لا حاجة لتمرير أي وسيطة كما يحتفظ النموذج ببيانات "تدريبه" والوسيطات كسمات النموذج.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل النموذج
|
||||
model = YOLO('yolov8n-seg.pt') # قم بتحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # قم بتحميل نموذج مخصص
|
||||
|
||||
# قم بالتحقق من النموذج
|
||||
metrics = model.val() # لا حاجة إلى أي وسيطة ، يتذكر النموذج بيانات التدريب والوسيطات كسمات النموذج
|
||||
metrics.box.map # map50-95(B)
|
||||
metrics.box.map50 # map50(B)
|
||||
metrics.box.map75 # map75(B)
|
||||
metrics.box.maps # قائمة تحتوي على map50-95(B) لكل فئة
|
||||
metrics.seg.map # map50-95(M)
|
||||
metrics.seg.map50 # map50(M)
|
||||
metrics.seg.map75 # map75(M)
|
||||
metrics.seg.maps # قائمة تحتوي على map50-95(M) لكل فئة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo segment val model=yolov8n-seg.pt # التحقق من النموذج الرسمي
|
||||
yolo segment val model=path/to/best.pt # التحقق من النموذج المخصص
|
||||
```
|
||||
|
||||
## التنبؤ
|
||||
|
||||
استخدم نموذج YOLOv8n-seg المدرب للقيام بالتنبؤات على الصور.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل النموذج
|
||||
model = YOLO('yolov8n-seg.pt') # قم بتحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # قم بتحميل نموذج مخصص
|
||||
|
||||
# التنبؤ باستخدام النموذج
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # التنبؤ على صورة
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' # التنبؤ باستخدام النموذج الرسمي
|
||||
yolo segment predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # التنبؤ باستخدام النموذج المخصص
|
||||
```
|
||||
|
||||
انظر تفاصيل "التنبؤ" الكاملة في [الصفحة](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## التصدير
|
||||
|
||||
قم بتصدير نموذج YOLOv8n-seg إلى تنسيق مختلف مثل ONNX و CoreML وما إلى ذلك.
|
||||
|
||||
!!! Example "مثال"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# قم بتحميل النموذج
|
||||
model = YOLO('yolov8n-seg.pt') # قم بتحميل نموذج رسمي
|
||||
model = YOLO('path/to/best.pt') # قم بتحميل نموذج مدرب مخصص
|
||||
|
||||
# قم بتصدير النموذج
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-seg.pt format=onnx # تصدير نموذج رسمي
|
||||
yolo export model=path/to/best.pt format=onnx # تصدير نموذج مدرب مخصص
|
||||
```
|
||||
|
||||
صيغ تصدير YOLOv8-seg المتاحة في الجدول أدناه. يمكنك التنبؤ أو التحقق من صحة الموديل المصدر بشكل مباشر ، أي `yolo predict model=yolov8n-seg.onnx`. يتم عرض أمثلة عن الاستخدام لنموذجك بعد اكتمال التصدير.
|
||||
|
||||
| الصيغة | `format` Argument | النموذج | التعليمات | الخيارات |
|
||||
|--------------------------------------------------------------------|-------------------|-------------------------------|-----------|-------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-seg.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-seg.torchscript` | ✅ | `الحجم ، الأمان` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-seg.onnx` | ✅ | `الحجم ، half ، dynamic ، simplify ، opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-seg_openvino_model/` | ✅ | `الحجم ، half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-seg.engine` | ✅ | `الحجم ، half ، dynamic ، simplify ، workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-seg.mlpackage` | ✅ | `الحجم ، half ، int8 ، nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-seg_saved_model/` | ✅ | `الحجم ، keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-seg.pb` | ❌ | `الحجم` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-seg.tflite` | ✅ | `الحجم ، half ، int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-seg_edgetpu.tflite` | ✅ | `الحجم` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-seg_web_model/` | ✅ | `الحجم` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-seg_paddle_model/` | ✅ | `الحجم` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-seg_ncnn_model/` | ✅ | `الحجم ، half` |
|
||||
|
||||
انظر تفاصيل "التصدير" الكاملة في [الصفحة](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1,116 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
"""
|
||||
This Python script is designed to automate the building and post-processing of MkDocs documentation, particularly for
|
||||
projects with multilingual content. It streamlines the workflow for generating localized versions of the documentation
|
||||
and updating HTML links to ensure they are correctly formatted.
|
||||
|
||||
Key Features:
|
||||
- Automated building of MkDocs documentation: The script compiles both the main documentation and
|
||||
any localized versions specified in separate MkDocs configuration files.
|
||||
- Post-processing of generated HTML files: After the documentation is built, the script updates all
|
||||
HTML files to remove the '.md' extension from internal links. This ensures that links in the built
|
||||
HTML documentation correctly point to other HTML pages rather than Markdown files, which is crucial
|
||||
for proper navigation within the web-based documentation.
|
||||
|
||||
Usage:
|
||||
- Run the script from the root directory of your MkDocs project.
|
||||
- Ensure that MkDocs is installed and that all MkDocs configuration files (main and localized versions)
|
||||
are present in the project directory.
|
||||
- The script first builds the documentation using MkDocs, then scans the generated HTML files in the 'site'
|
||||
directory to update the internal links.
|
||||
- It's ideal for projects where the documentation is written in Markdown and needs to be served as a static website.
|
||||
|
||||
Note:
|
||||
- This script is built to be run in an environment where Python and MkDocs are installed and properly configured.
|
||||
"""
|
||||
|
||||
import re
|
||||
import shutil
|
||||
import subprocess
|
||||
from pathlib import Path
|
||||
|
||||
DOCS = Path(__file__).parent.resolve()
|
||||
SITE = DOCS.parent / 'site'
|
||||
|
||||
|
||||
def build_docs():
|
||||
"""Build docs using mkdocs."""
|
||||
if SITE.exists():
|
||||
print(f'Removing existing {SITE}')
|
||||
shutil.rmtree(SITE)
|
||||
|
||||
# Build the main documentation
|
||||
print(f'Building docs from {DOCS}')
|
||||
subprocess.run(f'mkdocs build -f {DOCS}/mkdocs.yml', check=True, shell=True)
|
||||
|
||||
# Build other localized documentations
|
||||
for file in DOCS.glob('mkdocs_*.yml'):
|
||||
print(f'Building MkDocs site with configuration file: {file}')
|
||||
subprocess.run(f'mkdocs build -f {file}', check=True, shell=True)
|
||||
print(f'Site built at {SITE}')
|
||||
|
||||
|
||||
def update_html_links():
|
||||
"""Update href links in HTML files to remove '.md' and '/index.md', excluding links starting with 'https://'."""
|
||||
html_files = Path(SITE).rglob('*.html')
|
||||
total_updated_links = 0
|
||||
|
||||
for html_file in html_files:
|
||||
with open(html_file, 'r+', encoding='utf-8') as file:
|
||||
content = file.read()
|
||||
# Find all links to be updated, excluding those starting with 'https://'
|
||||
links_to_update = re.findall(r'href="(?!https://)([^"]+?)(/index)?\.md"', content)
|
||||
|
||||
# Update the content and count the number of links updated
|
||||
updated_content, number_of_links_updated = re.subn(r'href="(?!https://)([^"]+?)(/index)?\.md"',
|
||||
r'href="\1"', content)
|
||||
total_updated_links += number_of_links_updated
|
||||
|
||||
# Special handling for '/index' links
|
||||
updated_content, number_of_index_links_updated = re.subn(r'href="([^"]+)/index"', r'href="\1/"',
|
||||
updated_content)
|
||||
total_updated_links += number_of_index_links_updated
|
||||
|
||||
# Write the updated content back to the file
|
||||
file.seek(0)
|
||||
file.write(updated_content)
|
||||
file.truncate()
|
||||
|
||||
# Print updated links for this file
|
||||
for link in links_to_update:
|
||||
print(f'Updated link in {html_file}: {link[0]}')
|
||||
|
||||
print(f'Total number of links updated: {total_updated_links}')
|
||||
|
||||
|
||||
def update_page_title(file_path: Path, new_title: str):
|
||||
"""Update the title of an HTML file."""
|
||||
|
||||
# Read the content of the file
|
||||
with open(file_path, encoding='utf-8') as file:
|
||||
content = file.read()
|
||||
|
||||
# Replace the existing title with the new title
|
||||
updated_content = re.sub(r'<title>.*?</title>', f'<title>{new_title}</title>', content)
|
||||
|
||||
# Write the updated content back to the file
|
||||
with open(file_path, 'w', encoding='utf-8') as file:
|
||||
file.write(updated_content)
|
||||
|
||||
|
||||
def main():
|
||||
# Build the docs
|
||||
build_docs()
|
||||
|
||||
# Update .md in href links
|
||||
update_html_links()
|
||||
|
||||
# Show command to serve built website
|
||||
print('Serve site at http://localhost:8000 with "python -m http.server --directory site"')
|
||||
|
||||
# Update titles
|
||||
update_page_title(SITE / '404.html', new_title='Ultralytics Docs - Not Found')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -1,128 +0,0 @@
|
|||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||
"""
|
||||
Helper file to build Ultralytics Docs reference section. Recursively walks through ultralytics dir and builds an MkDocs
|
||||
reference section of *.md files composed of classes and functions, and also creates a nav menu for use in mkdocs.yaml.
|
||||
|
||||
Note: Must be run from repository root directory. Do not run from docs directory.
|
||||
"""
|
||||
|
||||
import re
|
||||
from collections import defaultdict
|
||||
from pathlib import Path
|
||||
|
||||
from ultralytics.utils import ROOT
|
||||
|
||||
NEW_YAML_DIR = ROOT.parent
|
||||
CODE_DIR = ROOT
|
||||
REFERENCE_DIR = ROOT.parent / 'docs/en/reference'
|
||||
|
||||
|
||||
def extract_classes_and_functions(filepath: Path) -> tuple:
|
||||
"""Extracts class and function names from a given Python file."""
|
||||
content = filepath.read_text()
|
||||
class_pattern = r'(?:^|\n)class\s(\w+)(?:\(|:)'
|
||||
func_pattern = r'(?:^|\n)def\s(\w+)\('
|
||||
|
||||
classes = re.findall(class_pattern, content)
|
||||
functions = re.findall(func_pattern, content)
|
||||
|
||||
return classes, functions
|
||||
|
||||
|
||||
def create_markdown(py_filepath: Path, module_path: str, classes: list, functions: list):
|
||||
"""Creates a Markdown file containing the API reference for the given Python module."""
|
||||
md_filepath = py_filepath.with_suffix('.md')
|
||||
|
||||
# Read existing content and keep header content between first two ---
|
||||
header_content = ''
|
||||
if md_filepath.exists():
|
||||
existing_content = md_filepath.read_text()
|
||||
header_parts = existing_content.split('---')
|
||||
for part in header_parts:
|
||||
if 'description:' in part or 'comments:' in part:
|
||||
header_content += f'---{part}---\n\n'
|
||||
|
||||
module_name = module_path.replace('.__init__', '')
|
||||
module_path = module_path.replace('.', '/')
|
||||
url = f'https://github.com/ultralytics/ultralytics/blob/main/{module_path}.py'
|
||||
edit = f'https://github.com/ultralytics/ultralytics/edit/main/{module_path}.py'
|
||||
title_content = (
|
||||
f'# Reference for `{module_path}.py`\n\n'
|
||||
f'!!! Note\n\n'
|
||||
f' This file is available at [{url}]({url}). If you spot a problem please help fix it by [contributing](https://docs.ultralytics.com/help/contributing/) a [Pull Request]({edit}) 🛠️. Thank you 🙏!\n\n'
|
||||
)
|
||||
md_content = ['<br><br>\n'] + [f'## ::: {module_name}.{class_name}\n\n<br><br>\n' for class_name in classes]
|
||||
md_content.extend(f'## ::: {module_name}.{func_name}\n\n<br><br>\n' for func_name in functions)
|
||||
md_content = header_content + title_content + '\n'.join(md_content)
|
||||
if not md_content.endswith('\n'):
|
||||
md_content += '\n'
|
||||
|
||||
md_filepath.parent.mkdir(parents=True, exist_ok=True)
|
||||
md_filepath.write_text(md_content)
|
||||
|
||||
return md_filepath.relative_to(NEW_YAML_DIR)
|
||||
|
||||
|
||||
def nested_dict() -> defaultdict:
|
||||
"""Creates and returns a nested defaultdict."""
|
||||
return defaultdict(nested_dict)
|
||||
|
||||
|
||||
def sort_nested_dict(d: dict) -> dict:
|
||||
"""Sorts a nested dictionary recursively."""
|
||||
return {key: sort_nested_dict(value) if isinstance(value, dict) else value for key, value in sorted(d.items())}
|
||||
|
||||
|
||||
def create_nav_menu_yaml(nav_items: list):
|
||||
"""Creates a YAML file for the navigation menu based on the provided list of items."""
|
||||
nav_tree = nested_dict()
|
||||
|
||||
for item_str in nav_items:
|
||||
item = Path(item_str)
|
||||
parts = item.parts
|
||||
current_level = nav_tree['reference']
|
||||
for part in parts[2:-1]: # skip the first two parts (docs and reference) and the last part (filename)
|
||||
current_level = current_level[part]
|
||||
|
||||
md_file_name = parts[-1].replace('.md', '')
|
||||
current_level[md_file_name] = item
|
||||
|
||||
nav_tree_sorted = sort_nested_dict(nav_tree)
|
||||
|
||||
def _dict_to_yaml(d, level=0):
|
||||
"""Converts a nested dictionary to a YAML-formatted string with indentation."""
|
||||
yaml_str = ''
|
||||
indent = ' ' * level
|
||||
for k, v in d.items():
|
||||
if isinstance(v, dict):
|
||||
yaml_str += f'{indent}- {k}:\n{_dict_to_yaml(v, level + 1)}'
|
||||
else:
|
||||
yaml_str += f"{indent}- {k}: {str(v).replace('docs/en/', '')}\n"
|
||||
return yaml_str
|
||||
|
||||
# Print updated YAML reference section
|
||||
print('Scan complete, new mkdocs.yaml reference section is:\n\n', _dict_to_yaml(nav_tree_sorted))
|
||||
|
||||
# Save new YAML reference section
|
||||
# (NEW_YAML_DIR / 'nav_menu_updated.yml').write_text(_dict_to_yaml(nav_tree_sorted))
|
||||
|
||||
|
||||
def main():
|
||||
"""Main function to extract class and function names, create Markdown files, and generate a YAML navigation menu."""
|
||||
nav_items = []
|
||||
|
||||
for py_filepath in CODE_DIR.rglob('*.py'):
|
||||
classes, functions = extract_classes_and_functions(py_filepath)
|
||||
|
||||
if classes or functions:
|
||||
py_filepath_rel = py_filepath.relative_to(CODE_DIR)
|
||||
md_filepath = REFERENCE_DIR / py_filepath_rel
|
||||
module_path = f"ultralytics.{py_filepath_rel.with_suffix('').as_posix().replace('/', '.')}"
|
||||
md_rel_filepath = create_markdown(md_filepath, module_path, classes, functions)
|
||||
nav_items.append(str(md_rel_filepath))
|
||||
|
||||
create_nav_menu_yaml(nav_items)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -1,82 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Entdecken Sie einen vollständigen Leitfaden zu Ultralytics YOLOv8, einem schnellen und präzisen Modell zur Objekterkennung und Bildsegmentierung. Installations-, Vorhersage-, Trainingstutorials und mehr.
|
||||
keywords: Ultralytics, YOLOv8, Objekterkennung, Bildsegmentierung, maschinelles Lernen, Deep Learning, Computer Vision, YOLOv8 Installation, YOLOv8 Vorhersage, YOLOv8 Training, YOLO-Geschichte, YOLO-Lizenzen
|
||||
---
|
||||
|
||||
<div align="center">
|
||||
<p>
|
||||
<a href="https://yolovision.ultralytics.com" target="_blank">
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/banner-yolov8.png" alt="Ultralytics YOLO Banner"></a>
|
||||
</p>
|
||||
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml"><img src="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml/badge.svg" alt="Ultralytics CI"></a>
|
||||
<a href="https://codecov.io/github/ultralytics/ultralytics"><img src="https://codecov.io/github/ultralytics/ultralytics/branch/main/graph/badge.svg?token=HHW7IIVFVY" alt="Ultralytics Code Coverage"></a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv8 Zitation"></a>
|
||||
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Ziehungen"></a>
|
||||
<br>
|
||||
<a href="https://console.paperspace.com/github/ultralytics/ultralytics"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Auf Gradient ausführen"></a>
|
||||
<a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="In Colab öffnen"></a>
|
||||
<a href="https://www.kaggle.com/ultralytics/yolov8"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="In Kaggle öffnen"></a>
|
||||
</div>
|
||||
|
||||
Wir stellen [Ultralytics](https://ultralytics.com) [YOLOv8](https://github.com/ultralytics/ultralytics) vor, die neueste Version des renommierten Echtzeit-Modells zur Objekterkennung und Bildsegmentierung. YOLOv8 basiert auf den neuesten Erkenntnissen im Bereich Deep Learning und Computer Vision und bietet eine unvergleichliche Leistung hinsichtlich Geschwindigkeit und Genauigkeit. Sein optimiertes Design macht es für verschiedene Anwendungen geeignet und leicht an verschiedene Hardwareplattformen anpassbar, von Edge-Geräten bis hin zu Cloud-APIs.
|
||||
|
||||
Erkunden Sie die YOLOv8-Dokumentation, eine umfassende Ressource, die Ihnen helfen soll, seine Funktionen und Fähigkeiten zu verstehen und zu nutzen. Ob Sie ein erfahrener Machine-Learning-Praktiker sind oder neu in diesem Bereich, dieses Hub zielt darauf ab, das Potenzial von YOLOv8 in Ihren Projekten zu maximieren
|
||||
|
||||
!!! Note "Hinweis"
|
||||
|
||||
🚧 Unsere mehrsprachige Dokumentation wird derzeit entwickelt und wir arbeiten intensiv an ihrer Verbesserung. Wir danken für Ihre Geduld! 🙏
|
||||
|
||||
## Wo Sie beginnen sollten
|
||||
|
||||
- **Installieren** Sie `ultralytics` mit pip und starten Sie in wenigen Minuten [:material-clock-fast: Loslegen](quickstart.md){ .md-button }
|
||||
- **Vorhersagen** Sie neue Bilder und Videos mit YOLOv8 [:octicons-image-16: Auf Bilder vorhersagen](modes/predict.md){ .md-button }
|
||||
- **Trainieren** Sie ein neues YOLOv8-Modell mit Ihrem eigenen benutzerdefinierten Datensatz [:fontawesome-solid-brain: Ein Modell trainieren](modes/train.md){ .md-button }
|
||||
- **Erforschen** Sie YOLOv8-Aufgaben wie Segmentieren, Klassifizieren, Posenschätzung und Verfolgen [:material-magnify-expand: Aufgaben erkunden](tasks/index.md){ .md-button }
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/LNwODJXcvt4?si=7n1UvGRLSd9p5wKs"
|
||||
title="YouTube-Video-Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Ansehen:</strong> Wie Sie ein YOLOv8-Modell auf Ihrem eigenen Datensatz in <a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb" target="_blank">Google Colab</a> trainieren.
|
||||
</p>
|
||||
|
||||
## YOLO: Eine kurze Geschichte
|
||||
|
||||
[YOLO](https://arxiv.org/abs/1506.02640) (You Only Look Once), ein beliebtes Modell zur Objekterkennung und Bildsegmentierung, wurde von Joseph Redmon und Ali Farhadi an der Universität von Washington entwickelt. Seit seiner Einführung im Jahr 2015 erfreut es sich aufgrund seiner hohen Geschwindigkeit und Genauigkeit großer Beliebtheit.
|
||||
|
||||
- [YOLOv2](https://arxiv.org/abs/1612.08242), veröffentlicht im Jahr 2016, verbesserte das Originalmodell durch die Einführung von Batch-Normalisierung, Ankerkästen und Dimensionsclustern.
|
||||
- [YOLOv3](https://pjreddie.com/media/files/papers/YOLOv3.pdf), eingeführt im Jahr 2018, erhöhte die Leistung des Modells weiter mit einem effizienteren Backbone-Netzwerk, mehreren Ankern und räumlichem Pyramid-Pooling.
|
||||
- [YOLOv4](https://arxiv.org/abs/2004.10934) wurde 2020 veröffentlicht und brachte Neuerungen wie Mosaic-Datenerweiterung, einen neuen ankerfreien Erkennungskopf und eine neue Verlustfunktion.
|
||||
- [YOLOv5](https://github.com/ultralytics/yolov5) verbesserte die Leistung des Modells weiter und führte neue Funktionen ein, wie Hyperparameter-Optimierung, integriertes Experiment-Tracking und automatischen Export in beliebte Exportformate.
|
||||
- [YOLOv6](https://github.com/meituan/YOLOv6) wurde 2022 von [Meituan](https://about.meituan.com/) als Open Source zur Verfügung gestellt und wird in vielen autonomen Lieferrobotern des Unternehmens eingesetzt.
|
||||
- [YOLOv7](https://github.com/WongKinYiu/yolov7) führte zusätzliche Aufgaben ein, wie Posenschätzung auf dem COCO-Keypoints-Datensatz.
|
||||
- [YOLOv8](https://github.com/ultralytics/ultralytics) ist die neueste Version von YOLO von Ultralytics. Als Spitzenmodell der neuesten Generation baut YOLOv8 auf dem Erfolg vorheriger Versionen auf und führt neue Funktionen und Verbesserungen für erhöhte Leistung, Flexibilität und Effizienz ein. YOLOv8 unterstützt eine vollständige Palette an Vision-KI-Aufgaben, einschließlich [Erkennung](tasks/detect.md), [Segmentierung](tasks/segment.md), [Posenschätzung](tasks/pose.md), [Verfolgung](modes/track.md) und [Klassifizierung](tasks/classify.md). Diese Vielseitigkeit ermöglicht es Benutzern, die Fähigkeiten von YOLOv8 in verschiedenen Anwendungen und Domänen zu nutzen.
|
||||
|
||||
## YOLO-Lizenzen: Wie wird Ultralytics YOLO lizenziert?
|
||||
|
||||
Ultralytics bietet zwei Lizenzoptionen, um unterschiedliche Einsatzszenarien zu berücksichtigen:
|
||||
|
||||
- **AGPL-3.0-Lizenz**: Diese [OSI-geprüfte](https://opensource.org/licenses/) Open-Source-Lizenz ist ideal für Studenten und Enthusiasten und fördert offene Zusammenarbeit und Wissensaustausch. Weitere Details finden Sie in der [LIZENZ](https://github.com/ultralytics/ultralytics/blob/main/LICENSE)-Datei.
|
||||
- **Enterprise-Lizenz**: Für die kommerzielle Nutzung konzipiert, ermöglicht diese Lizenz die problemlose Integration von Ultralytics-Software und KI-Modellen in kommerzielle Produkte und Dienstleistungen und umgeht die Open-Source-Anforderungen der AGPL-3.0. Wenn Ihr Szenario die Einbettung unserer Lösungen in ein kommerzielles Angebot beinhaltet, kontaktieren Sie uns über [Ultralytics-Lizenzierung](https://ultralytics.com/license).
|
||||
|
||||
Unsere Lizenzstrategie ist darauf ausgerichtet sicherzustellen, dass jegliche Verbesserungen an unseren Open-Source-Projekten der Gemeinschaft zurückgegeben werden. Wir halten die Prinzipien von Open Source in Ehren ❤️ und es ist unser Anliegen, dass unsere Beiträge auf Weisen genutzt und erweitert werden können, die für alle vorteilhaft sind.
|
||||
|
|
@ -1,193 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erkunden Sie FastSAM, eine CNN-basierte Lösung zur Echtzeit-Segmentierung von Objekten in Bildern. Verbesserte Benutzerinteraktion, Recheneffizienz und anpassbar für verschiedene Vision-Aufgaben.
|
||||
keywords: FastSAM, maschinelles Lernen, CNN-basierte Lösung, Objektsegmentierung, Echtzeillösung, Ultralytics, Vision-Aufgaben, Bildverarbeitung, industrielle Anwendungen, Benutzerinteraktion
|
||||
---
|
||||
|
||||
# Fast Segment Anything Model (FastSAM)
|
||||
|
||||
Das Fast Segment Anything Model (FastSAM) ist eine neuartige, Echtzeit-CNN-basierte Lösung für die Segment Anything Aufgabe. Diese Aufgabe zielt darauf ab, jedes Objekt in einem Bild auf Basis verschiedener möglicher Benutzerinteraktionen zu segmentieren. FastSAM reduziert signifikant den Rechenbedarf, während es eine wettbewerbsfähige Leistung beibehält und somit für eine Vielzahl von Vision-Aufgaben praktisch einsetzbar ist.
|
||||
|
||||

|
||||
|
||||
## Überblick
|
||||
|
||||
FastSAM wurde entwickelt, um die Einschränkungen des [Segment Anything Model (SAM)](sam.md) zu beheben, einem schweren Transformer-Modell mit erheblichem Rechenressourcenbedarf. Das FastSAM teilt die Segment Anything Aufgabe in zwei aufeinanderfolgende Stufen auf: die Instanzsegmentierung und die promptgesteuerte Auswahl. In der ersten Stufe wird [YOLOv8-seg](../tasks/segment.md) verwendet, um die Segmentierungsmasken aller Instanzen im Bild zu erzeugen. In der zweiten Stufe gibt es den Bereich von Interesse aus, der dem Prompt entspricht.
|
||||
|
||||
## Hauptmerkmale
|
||||
|
||||
1. **Echtzeitlösung:** Durch die Nutzung der Recheneffizienz von CNNs bietet FastSAM eine Echtzeitlösung für die Segment Anything Aufgabe und eignet sich somit für industrielle Anwendungen, die schnelle Ergebnisse erfordern.
|
||||
|
||||
2. **Effizienz und Leistung:** FastSAM bietet eine signifikante Reduzierung des Rechen- und Ressourcenbedarfs, ohne die Leistungsqualität zu beeinträchtigen. Es erzielt eine vergleichbare Leistung wie SAM, verwendet jedoch drastisch reduzierte Rechenressourcen und ermöglicht so eine Echtzeitanwendung.
|
||||
|
||||
3. **Promptgesteuerte Segmentierung:** FastSAM kann jedes Objekt in einem Bild anhand verschiedener möglicher Benutzerinteraktionsaufforderungen segmentieren. Dies ermöglicht Flexibilität und Anpassungsfähigkeit in verschiedenen Szenarien.
|
||||
|
||||
4. **Basierend auf YOLOv8-seg:** FastSAM basiert auf [YOLOv8-seg](../tasks/segment.md), einem Objektdetektor mit einem Instanzsegmentierungsmodul. Dadurch ist es in der Lage, die Segmentierungsmasken aller Instanzen in einem Bild effektiv zu erzeugen.
|
||||
|
||||
5. **Wettbewerbsfähige Ergebnisse auf Benchmarks:** Bei der Objektvorschlagsaufgabe auf MS COCO erzielt FastSAM hohe Punktzahlen bei deutlich schnellerem Tempo als [SAM](sam.md) auf einer einzelnen NVIDIA RTX 3090. Dies demonstriert seine Effizienz und Leistungsfähigkeit.
|
||||
|
||||
6. **Praktische Anwendungen:** Der vorgeschlagene Ansatz bietet eine neue, praktische Lösung für eine Vielzahl von Vision-Aufgaben mit sehr hoher Geschwindigkeit, die zehn- oder hundertmal schneller ist als vorhandene Methoden.
|
||||
|
||||
7. **Möglichkeit zur Modellkompression:** FastSAM zeigt, dass der Rechenaufwand erheblich reduziert werden kann, indem ein künstlicher Prior in die Struktur eingeführt wird. Dadurch eröffnen sich neue Möglichkeiten für große Modellarchitekturen für allgemeine Vision-Aufgaben.
|
||||
|
||||
## Verfügbare Modelle, unterstützte Aufgaben und Betriebsmodi
|
||||
|
||||
In dieser Tabelle werden die verfügbaren Modelle mit ihren spezifischen vorab trainierten Gewichten, den unterstützten Aufgaben und ihrer Kompatibilität mit verschiedenen Betriebsmodi wie [Inferenz](../modes/predict.md), [Validierung](../modes/val.md), [Training](../modes/train.md) und [Export](../modes/export.md) angezeigt. Dabei stehen ✅ Emojis für unterstützte Modi und ❌ Emojis für nicht unterstützte Modi.
|
||||
|
||||
| Modelltyp | Vorab trainierte Gewichte | Unterstützte Aufgaben | Inferenz | Validierung | Training | Export |
|
||||
|-----------|---------------------------|---------------------------------------------|----------|-------------|----------|--------|
|
||||
| FastSAM-s | `FastSAM-s.pt` | [Instanzsegmentierung](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
| FastSAM-x | `FastSAM-x.pt` | [Instanzsegmentierung](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
|
||||
## Beispiele für die Verwendung
|
||||
|
||||
Die FastSAM-Modelle lassen sich problemlos in Ihre Python-Anwendungen integrieren. Ultralytics bietet eine benutzerfreundliche Python-API und CLI-Befehle zur Vereinfachung der Entwicklung.
|
||||
|
||||
### Verwendung der Methode `predict`
|
||||
|
||||
Um eine Objekterkennung auf einem Bild durchzuführen, verwenden Sie die Methode `predict` wie folgt:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import FastSAM
|
||||
from ultralytics.models.fastsam import FastSAMPrompt
|
||||
|
||||
# Definieren Sie die Quelle für die Inferenz
|
||||
source = 'Pfad/zum/bus.jpg'
|
||||
|
||||
# Erstellen Sie ein FastSAM-Modell
|
||||
model = FastSAM('FastSAM-s.pt') # oder FastSAM-x.pt
|
||||
|
||||
# Führen Sie die Inferenz auf einem Bild durch
|
||||
everything_results = model(source, device='cpu', retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
|
||||
|
||||
# Bereiten Sie ein Prompt-Process-Objekt vor
|
||||
prompt_process = FastSAMPrompt(source, everything_results, device='cpu')
|
||||
|
||||
# Alles-Prompt
|
||||
ann = prompt_process.everything_prompt()
|
||||
|
||||
# Bbox Standardform [0,0,0,0] -> [x1,y1,x2,y2]
|
||||
ann = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
|
||||
|
||||
# Text-Prompt
|
||||
ann = prompt_process.text_prompt(text='ein Foto von einem Hund')
|
||||
|
||||
# Punkt-Prompt
|
||||
# Punkte Standard [[0,0]] [[x1,y1],[x2,y2]]
|
||||
# Punktbezeichnung Standard [0] [1,0] 0:Hintergrund, 1:Vordergrund
|
||||
ann = prompt_process.point_prompt(points=[[200, 200]], pointlabel=[1])
|
||||
prompt_process.plot(annotations=ann, output='./')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
# Laden Sie ein FastSAM-Modell und segmentieren Sie alles damit
|
||||
yolo segment predict model=FastSAM-s.pt source=Pfad/zum/bus.jpg imgsz=640
|
||||
```
|
||||
|
||||
Dieser Code-Ausschnitt zeigt die Einfachheit des Ladens eines vorab trainierten Modells und das Durchführen einer Vorhersage auf einem Bild.
|
||||
|
||||
### Verwendung von `val`
|
||||
|
||||
Die Validierung des Modells auf einem Datensatz kann wie folgt durchgeführt werden:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import FastSAM
|
||||
|
||||
# Erstellen Sie ein FastSAM-Modell
|
||||
model = FastSAM('FastSAM-s.pt') # oder FastSAM-x.pt
|
||||
|
||||
# Validieren Sie das Modell
|
||||
results = model.val(data='coco8-seg.yaml')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
# Laden Sie ein FastSAM-Modell und validieren Sie es auf dem COCO8-Beispieldatensatz mit Bildgröße 640
|
||||
yolo segment val model=FastSAM-s.pt data=coco8.yaml imgsz=640
|
||||
```
|
||||
|
||||
Bitte beachten Sie, dass FastSAM nur die Erkennung und Segmentierung einer einzigen Objektklasse unterstützt. Das bedeutet, dass es alle Objekte als dieselbe Klasse erkennt und segmentiert. Daher müssen Sie beim Vorbereiten des Datensatzes alle Objektkategorie-IDs in 0 umwandeln.
|
||||
|
||||
## Offizielle Verwendung von FastSAM
|
||||
|
||||
FastSAM ist auch direkt aus dem [https://github.com/CASIA-IVA-Lab/FastSAM](https://github.com/CASIA-IVA-Lab/FastSAM) Repository erhältlich. Hier ist ein kurzer Überblick über die typischen Schritte, die Sie unternehmen könnten, um FastSAM zu verwenden:
|
||||
|
||||
### Installation
|
||||
|
||||
1. Klonen Sie das FastSAM-Repository:
|
||||
```shell
|
||||
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
|
||||
```
|
||||
|
||||
2. Erstellen und aktivieren Sie eine Conda-Umgebung mit Python 3.9:
|
||||
```shell
|
||||
conda create -n FastSAM python=3.9
|
||||
conda activate FastSAM
|
||||
```
|
||||
|
||||
3. Navigieren Sie zum geklonten Repository und installieren Sie die erforderlichen Pakete:
|
||||
```shell
|
||||
cd FastSAM
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
4. Installieren Sie das CLIP-Modell:
|
||||
```shell
|
||||
pip install git+https://github.com/openai/CLIP.git
|
||||
```
|
||||
|
||||
### Beispielverwendung
|
||||
|
||||
1. Laden Sie eine [Modell-Sicherung](https://drive.google.com/file/d/1m1sjY4ihXBU1fZXdQ-Xdj-mDltW-2Rqv/view?usp=sharing) herunter.
|
||||
|
||||
2. Verwenden Sie FastSAM für Inferenz. Beispielbefehle:
|
||||
|
||||
- Segmentieren Sie alles in einem Bild:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
|
||||
```
|
||||
|
||||
- Segmentieren Sie bestimmte Objekte anhand eines Textprompts:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "der gelbe Hund"
|
||||
```
|
||||
|
||||
- Segmentieren Sie Objekte innerhalb eines Begrenzungsrahmens (geben Sie die Boxkoordinaten im xywh-Format an):
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[570,200,230,400]"
|
||||
```
|
||||
|
||||
- Segmentieren Sie Objekte in der Nähe bestimmter Punkte:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
|
||||
```
|
||||
|
||||
Sie können FastSAM auch über eine [Colab-Demo](https://colab.research.google.com/drive/1oX14f6IneGGw612WgVlAiy91UHwFAvr9?usp=sharing) oder die [HuggingFace-Web-Demo](https://huggingface.co/spaces/An-619/FastSAM) testen, um eine visuelle Erfahrung zu machen.
|
||||
|
||||
## Zitate und Danksagungen
|
||||
|
||||
Wir möchten den Autoren von FastSAM für ihre bedeutenden Beiträge auf dem Gebiet der Echtzeit-Instanzsegmentierung danken:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{zhao2023fast,
|
||||
title={Fast Segment Anything},
|
||||
author={Xu Zhao and Wenchao Ding and Yongqi An and Yinglong Du and Tao Yu and Min Li and Ming Tang and Jinqiao Wang},
|
||||
year={2023},
|
||||
eprint={2306.12156},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
Die ursprüngliche FastSAM-Arbeit ist auf [arXiv](https://arxiv.org/abs/2306.12156) zu finden. Die Autoren haben ihre Arbeit öffentlich zugänglich gemacht, und der Code ist auf [GitHub](https://github.com/CASIA-IVA-Lab/FastSAM) verfügbar. Wir schätzen ihre Bemühungen, das Fachgebiet voranzutreiben und ihre Arbeit der breiteren Gemeinschaft zugänglich zu machen.
|
||||
|
|
@ -1,98 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Entdecken Sie die vielfältige Palette an Modellen der YOLO-Familie, SAM, MobileSAM, FastSAM, YOLO-NAS und RT-DETR, die von Ultralytics unterstützt werden. Beginnen Sie mit Beispielen für die CLI- und Python-Nutzung.
|
||||
keywords: Ultralytics, Dokumentation, YOLO, SAM, MobileSAM, FastSAM, YOLO-NAS, RT-DETR, Modelle, Architekturen, Python, CLI
|
||||
---
|
||||
|
||||
# Von Ultralytics unterstützte Modelle
|
||||
|
||||
Willkommen bei der Modell-Dokumentation von Ultralytics! Wir bieten Unterstützung für eine breite Palette von Modellen, die jeweils für spezifische Aufgaben wie [Objekterkennung](../tasks/detect.md), [Instanzsegmentierung](../tasks/segment.md), [Bildklassifizierung](../tasks/classify.md), [Posenschätzung](../tasks/pose.md) und [Multi-Objekt-Tracking](../modes/track.md) maßgeschneidert sind. Wenn Sie daran interessiert sind, Ihre Modellarchitektur bei Ultralytics beizutragen, sehen Sie sich unseren [Beitragenden-Leitfaden](../../help/contributing.md) an.
|
||||
|
||||
!!! Note "Hinweis"
|
||||
|
||||
🚧 Unsere Dokumentation in verschiedenen Sprachen ist derzeit im Aufbau und wir arbeiten hart daran, sie zu verbessern. Vielen Dank für Ihre Geduld! 🙏
|
||||
|
||||
## Vorgestellte Modelle
|
||||
|
||||
Hier sind einige der wichtigsten unterstützten Modelle:
|
||||
|
||||
1. **[YOLOv3](yolov3.md)**: Die dritte Iteration der YOLO-Modellfamilie, ursprünglich von Joseph Redmon, bekannt für ihre effiziente Echtzeit-Objekterkennungsfähigkeiten.
|
||||
2. **[YOLOv4](yolov4.md)**: Ein dunkelnetz-natives Update von YOLOv3, veröffentlicht von Alexey Bochkovskiy im Jahr 2020.
|
||||
3. **[YOLOv5](yolov5.md)**: Eine verbesserte Version der YOLO-Architektur von Ultralytics, die bessere Leistungs- und Geschwindigkeitskompromisse im Vergleich zu früheren Versionen bietet.
|
||||
4. **[YOLOv6](yolov6.md)**: Veröffentlicht von [Meituan](https://about.meituan.com/) im Jahr 2022 und in vielen autonomen Lieferrobotern des Unternehmens im Einsatz.
|
||||
5. **[YOLOv7](yolov7.md)**: Aktualisierte YOLO-Modelle, die 2022 von den Autoren von YOLOv4 veröffentlicht wurden.
|
||||
6. **[YOLOv8](yolov8.md) NEU 🚀**: Die neueste Version der YOLO-Familie, mit erweiterten Fähigkeiten wie Instanzsegmentierung, Pose/Schlüsselpunktschätzung und Klassifizierung.
|
||||
7. **[Segment Anything Model (SAM)](sam.md)**: Metas Segment Anything Model (SAM).
|
||||
8. **[Mobile Segment Anything Model (MobileSAM)](mobile-sam.md)**: MobileSAM für mobile Anwendungen, von der Kyung Hee University.
|
||||
9. **[Fast Segment Anything Model (FastSAM)](fast-sam.md)**: FastSAM von der Image & Video Analysis Group, Institute of Automation, Chinesische Akademie der Wissenschaften.
|
||||
10. **[YOLO-NAS](yolo-nas.md)**: YOLO Neural Architecture Search (NAS) Modelle.
|
||||
11. **[Realtime Detection Transformers (RT-DETR)](rtdetr.md)**: Baidus PaddlePaddle Realtime Detection Transformer (RT-DETR) Modelle.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/MWq1UxqTClU?si=nHAW-lYDzrz68jR0"
|
||||
title="YouTube-Video-Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Anschauen:</strong> Führen Sie Ultralytics YOLO-Modelle in nur wenigen Codezeilen aus.
|
||||
</p>
|
||||
|
||||
## Einstieg: Nutzungbeispiele
|
||||
|
||||
Dieses Beispiel bietet einfache YOLO-Trainings- und Inferenzbeispiele. Für vollständige Dokumentationen über diese und andere [Modi](../modes/index.md) siehe die Dokumentationsseiten [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) und [Export](../modes/export.md).
|
||||
|
||||
Beachten Sie, dass das folgende Beispiel für YOLOv8 [Detect](../tasks/detect.md) Modelle zur Objekterkennung ist. Für zusätzliche unterstützte Aufgaben siehe die Dokumentation zu [Segment](../tasks/segment.md), [Classify](../tasks/classify.md) und [Pose](../tasks/pose.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
Vorgefertigte PyTorch `*.pt` Modelle sowie Konfigurationsdateien `*.yaml` können den Klassen `YOLO()`, `SAM()`, `NAS()` und `RTDETR()` übergeben werden, um eine Modellinstanz in Python zu erstellen:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden eines COCO-vortrainierten YOLOv8n Modells
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Modellinformationen anzeigen (optional)
|
||||
model.info()
|
||||
|
||||
# Model auf dem COCO8-Beispieldatensatz für 100 Epochen trainieren
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# Inferenz mit dem YOLOv8n Modell auf das Bild 'bus.jpg' ausführen
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
CLI-Befehle sind verfügbar, um die Modelle direkt auszuführen:
|
||||
|
||||
```bash
|
||||
# Ein COCO-vortrainiertes YOLOv8n Modell laden und auf dem COCO8-Beispieldatensatz für 100 Epochen trainieren
|
||||
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# Ein COCO-vortrainiertes YOLOv8n Modell laden und Inferenz auf das Bild 'bus.jpg' ausführen
|
||||
yolo predict model=yolov8n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Neue Modelle beitragen
|
||||
|
||||
Sind Sie daran interessiert, Ihr Modell bei Ultralytics beizutragen? Großartig! Wir sind immer offen dafür, unser Modellportfolio zu erweitern.
|
||||
|
||||
1. **Repository forken**: Beginnen Sie mit dem Forken des [Ultralytics GitHub-Repositorys](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
2. **Ihren Fork klonen**: Klonen Sie Ihren Fork auf Ihre lokale Maschine und erstellen Sie einen neuen Branch, um daran zu arbeiten.
|
||||
|
||||
3. **Ihr Modell implementieren**: Fügen Sie Ihr Modell entsprechend den in unserem [Beitragenden-Leitfaden](../../help/contributing.md) bereitgestellten Kodierungsstandards und Richtlinien hinzu.
|
||||
|
||||
4. **Gründlich testen**: Stellen Sie sicher, dass Sie Ihr Modell sowohl isoliert als auch als Teil des Pipelines gründlich testen.
|
||||
|
||||
5. **Eine Pull-Anfrage erstellen**: Sobald Sie mit Ihrem Modell zufrieden sind, erstellen Sie eine Pull-Anfrage zum Hauptrepository zur Überprüfung.
|
||||
|
||||
6. **Code-Review & Zusammenführen**: Nach der Überprüfung, wenn Ihr Modell unseren Kriterien entspricht, wird es in das Hauptrepository zusammengeführt.
|
||||
|
||||
Für detaillierte Schritte konsultieren Sie unseren [Beitragenden-Leitfaden](../../help/contributing.md).
|
||||
|
|
@ -1,116 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie mehr über MobileSAM, dessen Implementierung, den Vergleich mit dem Original-SAM und wie Sie es im Ultralytics-Framework herunterladen und testen können. Verbessern Sie Ihre mobilen Anwendungen heute.
|
||||
keywords: MobileSAM, Ultralytics, SAM, mobile Anwendungen, Arxiv, GPU, API, Bildencoder, Maskendekoder, Modell-Download, Testmethode
|
||||
---
|
||||
|
||||

|
||||
|
||||
# Mobile Segment Anything (MobileSAM)
|
||||
|
||||
Das MobileSAM-Paper ist jetzt auf [arXiv](https://arxiv.org/pdf/2306.14289.pdf) verfügbar.
|
||||
|
||||
Eine Demonstration von MobileSAM, das auf einer CPU ausgeführt wird, finden Sie unter diesem [Demo-Link](https://huggingface.co/spaces/dhkim2810/MobileSAM). Die Leistung auf einer Mac i5 CPU beträgt etwa 3 Sekunden. Auf der Hugging Face-Demo führt die Benutzeroberfläche und CPUs mit niedrigerer Leistung zu einer langsameren Reaktion, aber die Funktion bleibt effektiv.
|
||||
|
||||
MobileSAM ist in verschiedenen Projekten implementiert, darunter [Grounding-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything), [AnyLabeling](https://github.com/vietanhdev/anylabeling) und [Segment Anything in 3D](https://github.com/Jumpat/SegmentAnythingin3D).
|
||||
|
||||
MobileSAM wird mit einem einzigen GPU und einem 100K-Datensatz (1% der Originalbilder) in weniger als einem Tag trainiert. Der Code für dieses Training wird in Zukunft verfügbar gemacht.
|
||||
|
||||
## Verfügbarkeit von Modellen, unterstützte Aufgaben und Betriebsarten
|
||||
|
||||
Die folgende Tabelle zeigt die verfügbaren Modelle mit ihren spezifischen vortrainierten Gewichten, die unterstützten Aufgaben und ihre Kompatibilität mit unterschiedlichen Betriebsarten wie [Inferenz](../modes/predict.md), [Validierung](../modes/val.md), [Training](../modes/train.md) und [Export](../modes/export.md). Unterstützte Betriebsarten werden mit ✅-Emojis und nicht unterstützte Betriebsarten mit ❌-Emojis angezeigt.
|
||||
|
||||
| Modelltyp | Vortrainierte Gewichte | Unterstützte Aufgaben | Inferenz | Validierung | Training | Export |
|
||||
|-----------|------------------------|---------------------------------------------|----------|-------------|----------|--------|
|
||||
| MobileSAM | `mobile_sam.pt` | [Instanzsegmentierung](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
|
||||
## Anpassung von SAM zu MobileSAM
|
||||
|
||||
Da MobileSAM die gleiche Pipeline wie das Original-SAM beibehält, haben wir das ursprüngliche Preprocessing, Postprocessing und alle anderen Schnittstellen eingebunden. Personen, die derzeit das ursprüngliche SAM verwenden, können daher mit minimalem Aufwand zu MobileSAM wechseln.
|
||||
|
||||
MobileSAM bietet vergleichbare Leistungen wie das ursprüngliche SAM und behält dieselbe Pipeline, mit Ausnahme eines Wechsels des Bildencoders. Konkret ersetzen wir den ursprünglichen, leistungsstarken ViT-H-Encoder (632M) durch einen kleineren Tiny-ViT-Encoder (5M). Auf einem einzelnen GPU arbeitet MobileSAM in etwa 12 ms pro Bild: 8 ms auf dem Bildencoder und 4 ms auf dem Maskendekoder.
|
||||
|
||||
Die folgende Tabelle bietet einen Vergleich der Bildencoder, die auf ViT basieren:
|
||||
|
||||
| Bildencoder | Original-SAM | MobileSAM |
|
||||
|-----------------|--------------|-----------|
|
||||
| Parameter | 611M | 5M |
|
||||
| Geschwindigkeit | 452ms | 8ms |
|
||||
|
||||
Sowohl das ursprüngliche SAM als auch MobileSAM verwenden denselben promptgeführten Maskendekoder:
|
||||
|
||||
| Maskendekoder | Original-SAM | MobileSAM |
|
||||
|-----------------|--------------|-----------|
|
||||
| Parameter | 3.876M | 3.876M |
|
||||
| Geschwindigkeit | 4ms | 4ms |
|
||||
|
||||
Hier ist ein Vergleich der gesamten Pipeline:
|
||||
|
||||
| Gesamte Pipeline (Enc+Dec) | Original-SAM | MobileSAM |
|
||||
|----------------------------|--------------|-----------|
|
||||
| Parameter | 615M | 9.66M |
|
||||
| Geschwindigkeit | 456ms | 12ms |
|
||||
|
||||
Die Leistung von MobileSAM und des ursprünglichen SAM werden sowohl mit einem Punkt als auch mit einem Kasten als Prompt demonstriert.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Mit seiner überlegenen Leistung ist MobileSAM etwa 5-mal kleiner und 7-mal schneller als das aktuelle FastSAM. Weitere Details finden Sie auf der [MobileSAM-Projektseite](https://github.com/ChaoningZhang/MobileSAM).
|
||||
|
||||
## Testen von MobileSAM in Ultralytics
|
||||
|
||||
Wie beim ursprünglichen SAM bieten wir eine unkomplizierte Testmethode in Ultralytics an, einschließlich Modi für Punkt- und Kasten-Prompts.
|
||||
|
||||
### Modell-Download
|
||||
|
||||
Sie können das Modell [hier](https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt) herunterladen.
|
||||
|
||||
### Punkt-Prompt
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# Laden Sie das Modell
|
||||
model = SAM('mobile_sam.pt')
|
||||
|
||||
# Vorhersage einer Segmentierung basierend auf einem Punkt-Prompt
|
||||
model.predict('ultralytics/assets/zidane.jpg', points=[900, 370], labels=[1])
|
||||
```
|
||||
|
||||
### Kasten-Prompt
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# Laden Sie das Modell
|
||||
model = SAM('mobile_sam.pt')
|
||||
|
||||
# Vorhersage einer Segmentierung basierend auf einem Kasten-Prompt
|
||||
model.predict('ultralytics/assets/zidane.jpg', bboxes=[439, 437, 524, 709])
|
||||
```
|
||||
|
||||
Wir haben `MobileSAM` und `SAM` mit derselben API implementiert. Für weitere Verwendungsinformationen sehen Sie bitte die [SAM-Seite](sam.md).
|
||||
|
||||
## Zitate und Danksagungen
|
||||
|
||||
Wenn Sie MobileSAM in Ihrer Forschungs- oder Entwicklungsarbeit nützlich finden, zitieren Sie bitte unser Paper:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{mobile_sam,
|
||||
title={Faster Segment Anything: Towards Lightweight SAM for Mobile Applications},
|
||||
author={Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung Ho and Lee, Seungkyu and Hong, Choong Seon},
|
||||
journal={arXiv preprint arXiv:2306.14289},
|
||||
year={2023}
|
||||
}
|
||||
|
|
@ -1,93 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Entdecken Sie die Funktionen und Vorteile von RT-DETR, dem effizienten und anpassungsfähigen Echtzeitobjektdetektor von Baidu, der von Vision Transformers unterstützt wird, einschließlich vortrainierter Modelle.
|
||||
keywords: RT-DETR, Baidu, Vision Transformers, Objekterkennung, Echtzeitleistung, CUDA, TensorRT, IoU-bewusste Query-Auswahl, Ultralytics, Python API, PaddlePaddle
|
||||
---
|
||||
|
||||
# Baidus RT-DETR: Ein Echtzeit-Objektdetektor auf Basis von Vision Transformers
|
||||
|
||||
## Überblick
|
||||
|
||||
Der Real-Time Detection Transformer (RT-DETR), entwickelt von Baidu, ist ein moderner End-to-End-Objektdetektor, der Echtzeitleistung mit hoher Genauigkeit bietet. Er nutzt die Leistung von Vision Transformers (ViT), um Multiskalen-Funktionen effizient zu verarbeiten, indem intra-skaliere Interaktion und eine skalenübergreifende Fusion entkoppelt werden. RT-DETR ist hoch anpassungsfähig und unterstützt flexible Anpassung der Inferenzgeschwindigkeit durch Verwendung verschiedener Decoder-Schichten ohne erneutes Training. Das Modell übertrifft viele andere Echtzeit-Objektdetektoren auf beschleunigten Backends wie CUDA mit TensorRT.
|
||||
|
||||

|
||||
**Übersicht von Baidus RT-DETR.** Die Modellarchitekturdiagramm des RT-DETR zeigt die letzten drei Stufen des Backbone {S3, S4, S5} als Eingabe für den Encoder. Der effiziente Hybrid-Encoder verwandelt Multiskalen-Funktionen durch intraskalare Feature-Interaktion (AIFI) und das skalenübergreifende Feature-Fusion-Modul (CCFM) in eine Sequenz von Bildmerkmalen. Die IoU-bewusste Query-Auswahl wird verwendet, um eine feste Anzahl von Bildmerkmalen als anfängliche Objekt-Queries für den Decoder auszuwählen. Der Decoder optimiert iterativ Objekt-Queries, um Boxen und Vertrauenswerte zu generieren ([Quelle](https://arxiv.org/pdf/2304.08069.pdf)).
|
||||
|
||||
### Hauptmerkmale
|
||||
|
||||
- **Effizienter Hybrid-Encoder:** Baidus RT-DETR verwendet einen effizienten Hybrid-Encoder, der Multiskalen-Funktionen verarbeitet, indem intra-skaliere Interaktion und eine skalenübergreifende Fusion entkoppelt werden. Dieses einzigartige Design auf Basis von Vision Transformers reduziert die Rechenkosten und ermöglicht die Echtzeit-Objekterkennung.
|
||||
- **IoU-bewusste Query-Auswahl:** Baidus RT-DETR verbessert die Initialisierung von Objekt-Queries, indem IoU-bewusste Query-Auswahl verwendet wird. Dadurch kann das Modell sich auf die relevantesten Objekte in der Szene konzentrieren und die Erkennungsgenauigkeit verbessern.
|
||||
- **Anpassbare Inferenzgeschwindigkeit:** Baidus RT-DETR ermöglicht flexible Anpassungen der Inferenzgeschwindigkeit durch Verwendung unterschiedlicher Decoder-Schichten ohne erneutes Training. Diese Anpassungsfähigkeit erleichtert den praktischen Einsatz in verschiedenen Echtzeit-Objekterkennungsszenarien.
|
||||
|
||||
## Vortrainierte Modelle
|
||||
|
||||
Die Ultralytics Python API bietet vortrainierte PaddlePaddle RT-DETR-Modelle in verschiedenen Skalierungen:
|
||||
|
||||
- RT-DETR-L: 53,0% AP auf COCO val2017, 114 FPS auf T4 GPU
|
||||
- RT-DETR-X: 54,8% AP auf COCO val2017, 74 FPS auf T4 GPU
|
||||
|
||||
## Beispiele für die Verwendung
|
||||
|
||||
Das folgende Beispiel enthält einfache Trainings- und Inferenzbeispiele für RT-DETRR. Für die vollständige Dokumentation zu diesen und anderen [Modi](../modes/index.md) siehe die Dokumentationsseiten für [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) und [Export](../modes/export.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import RTDETR
|
||||
|
||||
# Laden Sie ein vortrainiertes RT-DETR-l Modell auf COCO
|
||||
model = RTDETR('rtdetr-l.pt')
|
||||
|
||||
# Zeigen Sie Informationen über das Modell an (optional)
|
||||
model.info()
|
||||
|
||||
# Trainieren Sie das Modell auf dem COCO8-Beispiel-Datensatz für 100 Epochen
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# Führen Sie die Inferenz mit dem RT-DETR-l Modell auf dem Bild 'bus.jpg' aus
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Laden Sie ein vortrainiertes RT-DETR-l Modell auf COCO und trainieren Sie es auf dem COCO8-Beispiel-Datensatz für 100 Epochen
|
||||
yolo train model=rtdetr-l.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# Laden Sie ein vortrainiertes RT-DETR-l Modell auf COCO und führen Sie die Inferenz auf dem Bild 'bus.jpg' aus
|
||||
yolo predict model=rtdetr-l.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Unterstützte Aufgaben und Modi
|
||||
|
||||
In dieser Tabelle werden die Modelltypen, die spezifischen vortrainierten Gewichte, die von jedem Modell unterstützten Aufgaben und die verschiedenen Modi ([Train](../modes/train.md), [Val](../modes/val.md), [Predict](../modes/predict.md), [Export](../modes/export.md)), die unterstützt werden, mit ✅-Emoji angezeigt.
|
||||
|
||||
| Modelltyp | Vortrainierte Gewichte | Unterstützte Aufgaben | Inferenz | Validierung | Training | Exportieren |
|
||||
|--------------------|------------------------|---------------------------------------|----------|-------------|----------|-------------|
|
||||
| RT-DETR Groß | `rtdetr-l.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| RT-DETR Extra-Groß | `rtdetr-x.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
## Zitate und Danksagungen
|
||||
|
||||
Wenn Sie Baidus RT-DETR in Ihrer Forschungs- oder Entwicklungsarbeit verwenden, zitieren Sie bitte das [ursprüngliche Papier](https://arxiv.org/abs/2304.08069):
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{lv2023detrs,
|
||||
title={DETRs Beat YOLOs on Real-time Object Detection},
|
||||
author={Wenyu Lv and Shangliang Xu and Yian Zhao and Guanzhong Wang and Jinman Wei and Cheng Cui and Yuning Du and Qingqing Dang and Yi Liu},
|
||||
year={2023},
|
||||
eprint={2304.08069},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
Wir möchten Baidu und dem [PaddlePaddle](https://github.com/PaddlePaddle/PaddleDetection)-Team für die Erstellung und Pflege dieser wertvollen Ressource für die Computer-Vision-Community danken. Ihre Beitrag zum Gebiet der Entwicklung des Echtzeit-Objekterkenners auf Basis von Vision Transformers, RT-DETR, wird sehr geschätzt.
|
||||
|
||||
*Keywords: RT-DETR, Transformer, ViT, Vision Transformers, Baidu RT-DETR, PaddlePaddle, Paddle Paddle RT-DETR, Objekterkennung in Echtzeit, objekterkennung basierend auf Vision Transformers, vortrainierte PaddlePaddle RT-DETR Modelle, Verwendung von Baidus RT-DETR, Ultralytics Python API*
|
||||
|
|
@ -1,226 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erkunden Sie das innovative Segment Anything Model (SAM) von Ultralytics, das Echtzeit-Bildsegmentierung ermöglicht. Erfahren Sie mehr über die promptable Segmentierung, die Zero-Shot-Performance und die Anwendung.
|
||||
keywords: Ultralytics, Bildsegmentierung, Segment Anything Model, SAM, SA-1B-Datensatz, Echtzeit-Performance, Zero-Shot-Transfer, Objekterkennung, Bildanalyse, maschinelles Lernen
|
||||
---
|
||||
|
||||
# Segment Anything Model (SAM)
|
||||
|
||||
Willkommen an der Spitze der Bildsegmentierung mit dem Segment Anything Model (SAM). Dieses revolutionäre Modell hat mit promptabler Bildsegmentierung und Echtzeit-Performance neue Standards in diesem Bereich gesetzt.
|
||||
|
||||
## Einführung in SAM: Das Segment Anything Model
|
||||
|
||||
Das Segment Anything Model (SAM) ist ein innovatives Bildsegmentierungsmodell, das promptable Segmentierung ermöglicht und so eine beispiellose Vielseitigkeit bei der Bildanalyse bietet. SAM bildet das Herzstück der Segment Anything Initiative, einem bahnbrechenden Projekt, das ein neuartiges Modell, eine neue Aufgabe und einen neuen Datensatz für die Bildsegmentierung einführt.
|
||||
|
||||
Dank seiner fortschrittlichen Konstruktion kann SAM sich an neue Bildverteilungen und Aufgaben anpassen, auch ohne Vorwissen. Das wird als Zero-Shot-Transfer bezeichnet. Trainiert wurde SAM auf dem umfangreichen [SA-1B-Datensatz](https://ai.facebook.com/datasets/segment-anything/), der über 1 Milliarde Masken auf 11 Millionen sorgfältig kuratierten Bildern enthält. SAM hat beeindruckende Zero-Shot-Performance gezeigt und in vielen Fällen frühere vollständig überwachte Ergebnisse übertroffen.
|
||||
|
||||

|
||||
Beispielimagen mit überlagernden Masken aus unserem neu eingeführten Datensatz SA-1B. SA-1B enthält 11 Millionen diverse, hochauflösende, lizenzierte und die Privatsphäre schützende Bilder und 1,1 Milliarden qualitativ hochwertige Segmentierungsmasken. Diese wurden vollautomatisch von SAM annotiert und sind nach menschlichen Bewertungen und zahlreichen Experimenten von hoher Qualität und Vielfalt. Die Bilder sind nach der Anzahl der Masken pro Bild gruppiert (im Durchschnitt sind es etwa 100 Masken pro Bild).
|
||||
|
||||
## Hauptmerkmale des Segment Anything Model (SAM)
|
||||
|
||||
- **Promptable Segmentierungsaufgabe:** SAM wurde mit der Ausführung einer promptable Segmentierungsaufgabe entwickelt, wodurch es valide Segmentierungsmasken aus beliebigen Prompts generieren kann, z. B. räumlichen oder textuellen Hinweisen zur Identifizierung eines Objekts.
|
||||
- **Fortgeschrittene Architektur:** Das Segment Anything Model verwendet einen leistungsfähigen Bild-Encoder, einen Prompt-Encoder und einen leichten Masken-Decoder. Diese einzigartige Architektur ermöglicht flexibles Prompting, Echtzeitmaskenberechnung und Berücksichtigung von Mehrdeutigkeiten in Segmentierungsaufgaben.
|
||||
- **Der SA-1B-Datensatz:** Eingeführt durch das Segment Anything Projekt, enthält der SA-1B-Datensatz über 1 Milliarde Masken auf 11 Millionen Bildern. Als bisher größter Segmentierungsdatensatz liefert er SAM eine vielfältige und umfangreiche Datenquelle für das Training.
|
||||
- **Zero-Shot-Performance:** SAM zeigt herausragende Zero-Shot-Performance in verschiedenen Segmentierungsaufgaben und ist damit ein einsatzbereites Werkzeug für vielfältige Anwendungen mit minimalem Bedarf an prompt engineering.
|
||||
|
||||
Für eine detaillierte Betrachtung des Segment Anything Models und des SA-1B-Datensatzes besuchen Sie bitte die [Segment Anything Website](https://segment-anything.com) und lesen Sie das Forschungspapier [Segment Anything](https://arxiv.org/abs/2304.02643).
|
||||
|
||||
## Verfügbare Modelle, unterstützte Aufgaben und Betriebsmodi
|
||||
|
||||
Diese Tabelle zeigt die verfügbaren Modelle mit ihren spezifischen vortrainierten Gewichten, die unterstützten Aufgaben und ihre Kompatibilität mit verschiedenen Betriebsmodi wie [Inference](../modes/predict.md), [Validierung](../modes/val.md), [Training](../modes/train.md) und [Export](../modes/export.md), wobei ✅ Emojis für unterstützte Modi und ❌ Emojis für nicht unterstützte Modi verwendet werden.
|
||||
|
||||
| Modelltyp | Vortrainierte Gewichte | Unterstützte Aufgaben | Inference | Validierung | Training | Export |
|
||||
|-----------|------------------------|---------------------------------------------|-----------|-------------|----------|--------|
|
||||
| SAM base | `sam_b.pt` | [Instanzsegmentierung](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
| SAM large | `sam_l.pt` | [Instanzsegmentierung](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
|
||||
|
||||
## Wie man SAM verwendet: Vielseitigkeit und Power in der Bildsegmentierung
|
||||
|
||||
Das Segment Anything Model kann für eine Vielzahl von Aufgaben verwendet werden, die über die Trainingsdaten hinausgehen. Dazu gehören Kantenerkennung, Generierung von Objektvorschlägen, Instanzsegmentierung und vorläufige Text-to-Mask-Vorhersage. Mit prompt engineering kann SAM sich schnell an neue Aufgaben und Datenverteilungen anpassen und sich so als vielseitiges und leistungsstarkes Werkzeug für alle Anforderungen der Bildsegmentierung etablieren.
|
||||
|
||||
### Beispiel für SAM-Vorhersage
|
||||
|
||||
!!! Example "Segmentierung mit Prompts"
|
||||
|
||||
Bildsegmentierung mit gegebenen Prompts.
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# Modell laden
|
||||
model = SAM('sam_b.pt')
|
||||
|
||||
# Modellinformationen anzeigen (optional)
|
||||
model.info()
|
||||
|
||||
# Inferenz mit Bounding Box Prompt
|
||||
model('ultralytics/assets/zidane.jpg', bboxes=[439, 437, 524, 709])
|
||||
|
||||
# Inferenz mit Point Prompt
|
||||
model('ultralytics/assets/zidane.jpg', points=[900, 370], labels=[1])
|
||||
```
|
||||
|
||||
!!! Example "Alles segmentieren"
|
||||
|
||||
Das ganze Bild segmentieren.
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import SAM
|
||||
|
||||
# Modell laden
|
||||
model = SAM('sam_b.pt')
|
||||
|
||||
# Modellinformationen anzeigen (optional)
|
||||
model.info()
|
||||
|
||||
# Inferenz
|
||||
model('Pfad/zum/Bild.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Inferenz mit einem SAM-Modell
|
||||
yolo predict model=sam_b.pt source=Pfad/zum/Bild.jpg
|
||||
```
|
||||
|
||||
- Die Logik hier besteht darin, das gesamte Bild zu segmentieren, wenn keine Prompts (Bounding Box/Point/Maske) übergeben werden.
|
||||
|
||||
!!! Example "Beispiel SAMPredictor"
|
||||
|
||||
Dadurch können Sie das Bild einmal festlegen und mehrmals Inferenz mit Prompts ausführen, ohne den Bild-Encoder mehrfach auszuführen.
|
||||
|
||||
=== "Prompt-Inferenz"
|
||||
|
||||
```python
|
||||
from ultralytics.models.sam import Predictor as SAMPredictor
|
||||
|
||||
# SAMPredictor erstellen
|
||||
overrides = dict(conf=0.25, task='segment', mode='predict', imgsz=1024, model="mobile_sam.pt")
|
||||
predictor = SAMPredictor(overrides=overrides)
|
||||
|
||||
# Bild festlegen
|
||||
predictor.set_image("ultralytics/assets/zidane.jpg") # Festlegung mit Bild-Datei
|
||||
predictor.set_image(cv2.imread("ultralytics/assets/zidane.jpg")) # Festlegung mit np.ndarray
|
||||
results = predictor(bboxes=[439, 437, 524, 709])
|
||||
results = predictor(points=[900, 370], labels=[1])
|
||||
|
||||
# Bild zurücksetzen
|
||||
predictor.reset_image()
|
||||
```
|
||||
|
||||
Alles segmentieren mit zusätzlichen Argumenten.
|
||||
|
||||
=== "Alles segmentieren"
|
||||
|
||||
```python
|
||||
from ultralytics.models.sam import Predictor as SAMPredictor
|
||||
|
||||
# SAMPredictor erstellen
|
||||
overrides = dict(conf=0.25, task='segment', mode='predict', imgsz=1024, model="mobile_sam.pt")
|
||||
predictor = SAMPredictor(overrides=overrides)
|
||||
|
||||
# Mit zusätzlichen Argumenten segmentieren
|
||||
results = predictor(source="ultralytics/assets/zidane.jpg", crop_n_layers=1, points_stride=64)
|
||||
```
|
||||
|
||||
- Weitere zusätzliche Argumente für `Alles segmentieren` finden Sie in der [`Predictor/generate` Referenz](../../../reference/models/sam/predict.md).
|
||||
|
||||
## Vergleich von SAM und YOLOv8
|
||||
|
||||
Hier vergleichen wir Meta's kleinstes SAM-Modell, SAM-b, mit Ultralytics kleinstem Segmentierungsmodell, [YOLOv8n-seg](../tasks/segment.md):
|
||||
|
||||
| Modell | Größe | Parameter | Geschwindigkeit (CPU) |
|
||||
|------------------------------------------------|-------------------------------|------------------------------|----------------------------------------|
|
||||
| Meta's SAM-b | 358 MB | 94,7 M | 51096 ms/pro Bild |
|
||||
| [MobileSAM](mobile-sam.md) | 40,7 MB | 10,1 M | 46122 ms/pro Bild |
|
||||
| [FastSAM-s](fast-sam.md) mit YOLOv8-Backbone | 23,7 MB | 11,8 M | 115 ms/pro Bild |
|
||||
| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6,7 MB** (53,4-mal kleiner) | **3,4 M** (27,9-mal kleiner) | **59 ms/pro Bild** (866-mal schneller) |
|
||||
|
||||
Dieser Vergleich zeigt die Größen- und Geschwindigkeitsunterschiede zwischen den Modellen. Während SAM einzigartige Fähigkeiten für die automatische Segmentierung bietet, konkurriert es nicht direkt mit YOLOv8-Segmentierungsmodellen, die kleiner, schneller und effizienter sind.
|
||||
|
||||
Die Tests wurden auf einem Apple M2 MacBook aus dem Jahr 2023 mit 16 GB RAM durchgeführt. Um diesen Test zu reproduzieren:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics import FastSAM, SAM, YOLO
|
||||
|
||||
# SAM-b profilieren
|
||||
model = SAM('sam_b.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
|
||||
# MobileSAM profilieren
|
||||
model = SAM('mobile_sam.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
|
||||
# FastSAM-s profilieren
|
||||
model = FastSAM('FastSAM-s.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
|
||||
# YOLOv8n-seg profilieren
|
||||
model = YOLO('yolov8n-seg.pt')
|
||||
model.info()
|
||||
model('ultralytics/assets')
|
||||
```
|
||||
|
||||
## Auto-Annotierung: Der schnelle Weg zu Segmentierungsdatensätzen
|
||||
|
||||
Die Auto-Annotierung ist eine wichtige Funktion von SAM, mit der Benutzer mithilfe eines vortrainierten Detektionsmodells einen [Segmentierungsdatensatz](https://docs.ultralytics.com/datasets/segment) generieren können. Diese Funktion ermöglicht eine schnelle und genaue Annotation einer großen Anzahl von Bildern, ohne dass zeitaufwändiges manuelles Labeling erforderlich ist.
|
||||
|
||||
### Generieren Sie Ihren Segmentierungsdatensatz mit einem Detektionsmodell
|
||||
|
||||
Um Ihren Datensatz mit dem Ultralytics-Framework automatisch zu annotieren, verwenden Sie die `auto_annotate` Funktion wie folgt:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
from ultralytics.data.annotator import auto_annotate
|
||||
|
||||
auto_annotate(data="Pfad/zum/Bilderordner", det_model="yolov8x.pt", sam_model='sam_b.pt')
|
||||
```
|
||||
|
||||
| Argument | Typ | Beschreibung | Standard |
|
||||
|------------|---------------------|---------------------------------------------------------------------------------------------------------------------------|--------------|
|
||||
| data | str | Pfad zu einem Ordner, der die zu annotierenden Bilder enthält. | |
|
||||
| det_model | str, optional | Vortrainiertes YOLO-Detektionsmodell. Standardmäßig 'yolov8x.pt'. | 'yolov8x.pt' |
|
||||
| sam_model | str, optional | Vortrainiertes SAM-Segmentierungsmodell. Standardmäßig 'sam_b.pt'. | 'sam_b.pt' |
|
||||
| device | str, optional | Gerät, auf dem die Modelle ausgeführt werden. Standardmäßig ein leerer String (CPU oder GPU, falls verfügbar). | |
|
||||
| output_dir | str, None, optional | Verzeichnis zum Speichern der annotierten Ergebnisse. Standardmäßig ein 'labels'-Ordner im selben Verzeichnis wie 'data'. | None |
|
||||
|
||||
Die `auto_annotate` Funktion nimmt den Pfad zu Ihren Bildern entgegen, mit optionalen Argumenten für das vortrainierte Detektions- und SAM-Segmentierungsmodell, das Gerät, auf dem die Modelle ausgeführt werden sollen, und das Ausgabeverzeichnis, in dem die annotierten Ergebnisse gespeichert werden sollen.
|
||||
|
||||
Die Auto-Annotierung mit vortrainierten Modellen kann die Zeit und den Aufwand für die Erstellung hochwertiger Segmentierungsdatensätze erheblich reduzieren. Diese Funktion ist besonders vorteilhaft für Forscher und Entwickler, die mit großen Bildersammlungen arbeiten. Sie ermöglicht es ihnen, sich auf die Modellentwicklung und -bewertung zu konzentrieren, anstatt auf die manuelle Annotation.
|
||||
|
||||
## Zitate und Danksagungen
|
||||
|
||||
Wenn Sie SAM in Ihrer Forschungs- oder Entwicklungsarbeit nützlich finden, erwägen Sie bitte, unser Paper zu zitieren:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{kirillov2023segment,
|
||||
title={Segment Anything},
|
||||
author={Alexander Kirillov and Eric Mintun and Nikhila Ravi and Hanzi Mao and Chloe Rolland and Laura Gustafson and Tete Xiao and Spencer Whitehead and Alexander C. Berg and Wan-Yen Lo and Piotr Dollár and Ross Girshick},
|
||||
year={2023},
|
||||
eprint={2304.02643},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
Wir möchten Meta AI für die Erstellung und Pflege dieser wertvollen Ressource für die Computer Vision Community danken.
|
||||
|
||||
*Stichworte: Segment Anything, Segment Anything Model, SAM, Meta SAM, Bildsegmentierung, Promptable Segmentierung, Zero-Shot-Performance, SA-1B-Datensatz, fortschrittliche Architektur, Auto-Annotierung, Ultralytics, vortrainierte Modelle, SAM Base, SAM Large, Instanzsegmentierung, Computer Vision, Künstliche Intelligenz, maschinelles Lernen, Datenannotation, Segmentierungsmasken, Detektionsmodell, YOLO Detektionsmodell, Bibtex, Meta AI.*
|
||||
|
|
@ -1,121 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie mehr über YOLO-NAS, ein herausragendes Modell für die Objekterkennung. Erfahren Sie mehr über seine Funktionen, vortrainierte Modelle, Nutzung mit der Ultralytics Python API und vieles mehr.
|
||||
keywords: YOLO-NAS, Deci AI, Objekterkennung, Deep Learning, Neural Architecture Search, Ultralytics Python API, YOLO-Modell, vortrainierte Modelle, Quantisierung, Optimierung, COCO, Objects365, Roboflow 100
|
||||
---
|
||||
|
||||
# YOLO-NAS
|
||||
|
||||
## Übersicht
|
||||
|
||||
Entwickelt von Deci AI, ist YOLO-NAS ein bahnbrechendes Modell für die Objekterkennung. Es ist das Ergebnis fortschrittlicher Technologien zur Neural Architecture Search und wurde sorgfältig entworfen, um die Einschränkungen früherer YOLO-Modelle zu überwinden. Mit signifikanten Verbesserungen in der Quantisierungsunterstützung und Abwägung von Genauigkeit und Latenz stellt YOLO-NAS einen großen Fortschritt in der Objekterkennung dar.
|
||||
|
||||

|
||||
**Übersicht über YOLO-NAS.** YOLO-NAS verwendet Quantisierungsblöcke und selektive Quantisierung für optimale Leistung. Das Modell weist bei der Konvertierung in seine quantisierte Version mit INT8 einen minimalen Präzisionsverlust auf, was im Vergleich zu anderen Modellen eine signifikante Verbesserung darstellt. Diese Entwicklungen führen zu einer überlegenen Architektur mit beispiellosen Fähigkeiten zur Objekterkennung und herausragender Leistung.
|
||||
|
||||
### Schlüsselfunktionen
|
||||
|
||||
- **Quantisierungsfreundlicher Basiselement:** YOLO-NAS führt ein neues Basiselement ein, das für Quantisierung geeignet ist und eine der wesentlichen Einschränkungen früherer YOLO-Modelle angeht.
|
||||
- **Raffiniertes Training und Quantisierung:** YOLO-NAS nutzt fortschrittliche Trainingsschemata und post-training Quantisierung zur Leistungsverbesserung.
|
||||
- **AutoNAC-Optimierung und Vortraining:** YOLO-NAS verwendet die AutoNAC-Optimierung und wird auf prominenten Datensätzen wie COCO, Objects365 und Roboflow 100 vortrainiert. Dieses Vortraining macht es äußerst geeignet für die Objekterkennung in Produktionsumgebungen.
|
||||
|
||||
## Vortrainierte Modelle
|
||||
|
||||
Erleben Sie die Leistungsfähigkeit der Objekterkennung der nächsten Generation mit den vortrainierten YOLO-NAS-Modellen von Ultralytics. Diese Modelle sind darauf ausgelegt, sowohl bei Geschwindigkeit als auch bei Genauigkeit hervorragende Leistung zu liefern. Wählen Sie aus einer Vielzahl von Optionen, die auf Ihre spezifischen Anforderungen zugeschnitten sind:
|
||||
|
||||
| Modell | mAP | Latenz (ms) |
|
||||
|------------------|-------|-------------|
|
||||
| YOLO-NAS S | 47,5 | 3,21 |
|
||||
| YOLO-NAS M | 51,55 | 5,85 |
|
||||
| YOLO-NAS L | 52,22 | 7,87 |
|
||||
| YOLO-NAS S INT-8 | 47,03 | 2,36 |
|
||||
| YOLO-NAS M INT-8 | 51,0 | 3,78 |
|
||||
| YOLO-NAS L INT-8 | 52,1 | 4,78 |
|
||||
|
||||
Jede Modellvariante ist darauf ausgelegt, eine Balance zwischen Mean Average Precision (mAP) und Latenz zu bieten und Ihre Objekterkennungsaufgaben für Performance und Geschwindigkeit zu optimieren.
|
||||
|
||||
## Beispiele zur Verwendung
|
||||
|
||||
Ultralytics hat es einfach gemacht, YOLO-NAS-Modelle in Ihre Python-Anwendungen über unser `ultralytics` Python-Paket zu integrieren. Das Paket bietet eine benutzerfreundliche Python-API, um den Prozess zu optimieren.
|
||||
|
||||
Die folgenden Beispiele zeigen, wie Sie YOLO-NAS-Modelle mit dem `ultralytics`-Paket für Inferenz und Validierung verwenden:
|
||||
|
||||
### Beispiele für Inferenz und Validierung
|
||||
|
||||
In diesem Beispiel validieren wir YOLO-NAS-s auf dem COCO8-Datensatz.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
Dieses Beispiel bietet einfachen Code für Inferenz und Validierung für YOLO-NAS. Für die Verarbeitung von Inferenzergebnissen siehe den [Predict](../modes/predict.md)-Modus. Für die Verwendung von YOLO-NAS mit zusätzlichen Modi siehe [Val](../modes/val.md) und [Export](../modes/export.md). Das YOLO-NAS-Modell im `ultralytics`-Paket unterstützt kein Training.
|
||||
|
||||
=== "Python"
|
||||
|
||||
Vorab trainierte `*.pt`-Modelldateien von PyTorch können der Klasse `NAS()` übergeben werden, um eine Modellinstanz in Python zu erstellen:
|
||||
|
||||
```python
|
||||
from ultralytics import NAS
|
||||
|
||||
# Laden Sie ein auf COCO vortrainiertes YOLO-NAS-s-Modell
|
||||
model = NAS('yolo_nas_s.pt')
|
||||
|
||||
# Modelinformationen anzeigen (optional)
|
||||
model.info()
|
||||
|
||||
# Validieren Sie das Modell am Beispiel des COCO8-Datensatzes
|
||||
results = model.val(data='coco8.yaml')
|
||||
|
||||
# Führen Sie Inferenz mit dem YOLO-NAS-s-Modell auf dem Bild 'bus.jpg' aus
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
CLI-Befehle sind verfügbar, um die Modelle direkt auszuführen:
|
||||
|
||||
```bash
|
||||
# Laden Sie ein auf COCO vortrainiertes YOLO-NAS-s-Modell und validieren Sie die Leistung am Beispiel des COCO8-Datensatzes
|
||||
yolo val model=yolo_nas_s.pt data=coco8.yaml
|
||||
|
||||
# Laden Sie ein auf COCO vortrainiertes YOLO-NAS-s-Modell und führen Sie Inferenz auf dem Bild 'bus.jpg' aus
|
||||
yolo predict model=yolo_nas_s.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Unterstützte Aufgaben und Modi
|
||||
|
||||
Wir bieten drei Varianten der YOLO-NAS-Modelle an: Small (s), Medium (m) und Large (l). Jede Variante ist dazu gedacht, unterschiedliche Berechnungs- und Leistungsanforderungen zu erfüllen:
|
||||
|
||||
- **YOLO-NAS-s**: Optimiert für Umgebungen mit begrenzten Rechenressourcen, bei denen Effizienz entscheidend ist.
|
||||
- **YOLO-NAS-m**: Bietet einen ausgewogenen Ansatz und ist für die Objekterkennung im Allgemeinen mit höherer Genauigkeit geeignet.
|
||||
- **YOLO-NAS-l**: Maßgeschneidert für Szenarien, bei denen höchste Genauigkeit gefordert ist und Rechenressourcen weniger einschränkend sind.
|
||||
|
||||
Im Folgenden finden Sie eine detaillierte Übersicht über jedes Modell, einschließlich Links zu den vortrainierten Gewichten, den unterstützten Aufgaben und deren Kompatibilität mit verschiedenen Betriebsmodi.
|
||||
|
||||
| Modelltyp | Vortrainierte Gewichte | Unterstützte Aufgaben | Inferenz | Validierung | Training | Export |
|
||||
|------------|-----------------------------------------------------------------------------------------------|---------------------------------------|----------|-------------|----------|--------|
|
||||
| YOLO-NAS-s | [yolo_nas_s.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolo_nas_s.pt) | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
|
||||
| YOLO-NAS-m | [yolo_nas_m.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolo_nas_m.pt) | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
|
||||
| YOLO-NAS-l | [yolo_nas_l.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolo_nas_l.pt) | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
|
||||
|
||||
## Zitierungen und Danksagungen
|
||||
|
||||
Wenn Sie YOLO-NAS in Ihrer Forschungs- oder Entwicklungsarbeit verwenden, zitieren Sie bitte SuperGradients:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{supergradients,
|
||||
doi = {10.5281/ZENODO.7789328},
|
||||
url = {https://zenodo.org/record/7789328},
|
||||
author = {Aharon, Shay and {Louis-Dupont} and {Ofri Masad} and Yurkova, Kate and {Lotem Fridman} and {Lkdci} and Khvedchenya, Eugene and Rubin, Ran and Bagrov, Natan and Tymchenko, Borys and Keren, Tomer and Zhilko, Alexander and {Eran-Deci}},
|
||||
title = {Super-Gradients},
|
||||
publisher = {GitHub},
|
||||
journal = {GitHub repository},
|
||||
year = {2021},
|
||||
}
|
||||
```
|
||||
|
||||
Wir möchten dem [SuperGradients](https://github.com/Deci-AI/super-gradients/)-Team von Deci AI für ihre Bemühungen bei der Erstellung und Pflege dieser wertvollen Ressource für die Computer Vision Community danken. Wir sind der Meinung, dass YOLO-NAS mit seiner innovativen Architektur und seinen herausragenden Fähigkeiten zur Objekterkennung ein wichtiges Werkzeug für Entwickler und Forscher gleichermaßen wird.
|
||||
|
||||
*Keywords: YOLO-NAS, Deci AI, Objekterkennung, Deep Learning, Neural Architecture Search, Ultralytics Python API, YOLO-Modell, SuperGradients, vortrainierte Modelle, quantisierungsfreundliches Basiselement, fortschrittliche Trainingsschemata, post-training Quantisierung, AutoNAC-Optimierung, COCO, Objects365, Roboflow 100*
|
||||
|
|
@ -1,98 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erhalten Sie eine Übersicht über YOLOv3, YOLOv3-Ultralytics und YOLOv3u. Erfahren Sie mehr über ihre wichtigsten Funktionen, Verwendung und unterstützte Aufgaben für die Objekterkennung.
|
||||
keywords: YOLOv3, YOLOv3-Ultralytics, YOLOv3u, Objekterkennung, Inferenz, Training, Ultralytics
|
||||
---
|
||||
|
||||
# YOLOv3, YOLOv3-Ultralytics und YOLOv3u
|
||||
|
||||
## Übersicht
|
||||
|
||||
Dieses Dokument bietet eine Übersicht über drei eng verwandte Modelle zur Objekterkennung, nämlich [YOLOv3](https://pjreddie.com/darknet/yolo/), [YOLOv3-Ultralytics](https://github.com/ultralytics/yolov3) und [YOLOv3u](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
1. **YOLOv3:** Dies ist die dritte Version des You Only Look Once (YOLO) Objekterkennungsalgorithmus. Ursprünglich entwickelt von Joseph Redmon, verbesserte YOLOv3 seine Vorgängermodelle durch die Einführung von Funktionen wie mehrskaligen Vorhersagen und drei verschiedenen Größen von Erkennungskernen.
|
||||
|
||||
2. **YOLOv3-Ultralytics:** Dies ist die Implementierung des YOLOv3-Modells von Ultralytics. Es reproduziert die ursprüngliche YOLOv3-Architektur und bietet zusätzliche Funktionalitäten, wie die Unterstützung für weitere vortrainierte Modelle und einfachere Anpassungsoptionen.
|
||||
|
||||
3. **YOLOv3u:** Dies ist eine aktualisierte Version von YOLOv3-Ultralytics, die den anchor-freien, objektfreien Split Head aus den YOLOv8-Modellen einbezieht. YOLOv3u verwendet die gleiche Backbone- und Neck-Architektur wie YOLOv3, aber mit dem aktualisierten Erkennungskopf von YOLOv8.
|
||||
|
||||

|
||||
|
||||
## Wichtigste Funktionen
|
||||
|
||||
- **YOLOv3:** Einführung der Verwendung von drei unterschiedlichen Skalen für die Erkennung unter Verwendung von drei verschiedenen Größen von Erkennungskernen: 13x13, 26x26 und 52x52. Dadurch wurde die Erkennungsgenauigkeit für Objekte unterschiedlicher Größe erheblich verbessert. Darüber hinaus fügte YOLOv3 Funktionen wie Mehrfachkennzeichnungen für jeden Begrenzungsrahmen und ein besseres Feature-Extraktionsnetzwerk hinzu.
|
||||
|
||||
- **YOLOv3-Ultralytics:** Ultralytics' Implementierung von YOLOv3 bietet die gleiche Leistung wie das ursprüngliche Modell, bietet jedoch zusätzliche Unterstützung für weitere vortrainierte Modelle, zusätzliche Trainingsmethoden und einfachere Anpassungsoptionen. Dadurch wird es vielseitiger und benutzerfreundlicher für praktische Anwendungen.
|
||||
|
||||
- **YOLOv3u:** Dieses aktualisierte Modell enthält den anchor-freien, objektfreien Split Head aus YOLOv8. Durch die Beseitigung der Notwendigkeit vordefinierter Ankerfelder und Objektheitsscores kann dieses Entwurfsmerkmal für den Erkennungskopf die Fähigkeit des Modells verbessern, Objekte unterschiedlicher Größe und Form zu erkennen. Dadurch wird YOLOv3u robuster und genauer für Aufgaben der Objekterkennung.
|
||||
|
||||
## Unterstützte Aufgaben und Modi
|
||||
|
||||
Die YOLOv3-Serie, einschließlich YOLOv3, YOLOv3-Ultralytics und YOLOv3u, ist speziell für Aufgaben der Objekterkennung konzipiert. Diese Modelle sind bekannt für ihre Effektivität in verschiedenen realen Szenarien und kombinieren Genauigkeit und Geschwindigkeit. Jede Variante bietet einzigartige Funktionen und Optimierungen, die sie für eine Vielzahl von Anwendungen geeignet machen.
|
||||
|
||||
Alle drei Modelle unterstützen einen umfangreichen Satz von Modi, um Vielseitigkeit in verschiedenen Phasen der Modellbereitstellung und -entwicklung zu gewährleisten. Zu diesen Modi gehören [Inferenz](../modes/predict.md), [Validierung](../modes/val.md), [Training](../modes/train.md) und [Export](../modes/export.md), was den Benutzern ein vollständiges Toolkit für eine effektive Objekterkennung bietet.
|
||||
|
||||
| Modelltyp | Unterstützte Aufgaben | Inferenz | Validierung | Training | Export |
|
||||
|--------------------|---------------------------------------|----------|-------------|----------|--------|
|
||||
| YOLOv3 | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv3-Ultralytics | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv3u | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
Diese Tabelle bietet einen schnellen Überblick über die Fähigkeiten jeder YOLOv3-Variante und hebt ihre Vielseitigkeit und Eignung für verschiedene Aufgaben und Betriebsmodi in Workflows zur Objekterkennung hervor.
|
||||
|
||||
## Beispiele zur Verwendung
|
||||
|
||||
Dieses Beispiel enthält einfache Trainings- und Inferenzbeispiele für YOLOv3. Für die vollständige Dokumentation zu diesen und anderen [Modi](../modes/index.md) siehe die Seiten zur [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) und [Export](../modes/export.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
Vorgefertigte PyTorch-Modelle im `*.pt`-Format sowie Konfigurationsdateien im `*.yaml`-Format können an die `YOLO()`-Klasse übergeben werden, um eine Modellinstanz in Python zu erstellen:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Lade ein vortrainiertes YOLOv3n-Modell für COCO
|
||||
model = YOLO('yolov3n.pt')
|
||||
|
||||
# Zeige Informationen zum Modell an (optional)
|
||||
model.info()
|
||||
|
||||
# Trainiere das Modell mit dem COCO8-Beispieldatensatz für 100 Epochen
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# Führe Inferenz mit dem YOLOv3n-Modell auf dem Bild "bus.jpg" durch
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
CLI-Befehle stehen zur Verfügung, um die Modelle direkt auszuführen:
|
||||
|
||||
```bash
|
||||
# Lade ein vortrainiertes YOLOv3n-Modell und trainiere es mit dem COCO8-Beispieldatensatz für 100 Epochen
|
||||
yolo train model=yolov3n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# Lade ein vortrainiertes YOLOv3n-Modell und führe Inferenz auf dem Bild "bus.jpg" aus
|
||||
yolo predict model=yolov3n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Zitate und Anerkennungen
|
||||
|
||||
Wenn Sie YOLOv3 in Ihrer Forschung verwenden, zitieren Sie bitte die ursprünglichen YOLO-Papiere und das Ultralytics YOLOv3-Repository:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{redmon2018yolov3,
|
||||
title={YOLOv3: An Incremental Improvement},
|
||||
author={Redmon, Joseph and Farhadi, Ali},
|
||||
journal={arXiv preprint arXiv:1804.02767},
|
||||
year={2018}
|
||||
}
|
||||
```
|
||||
|
||||
Vielen Dank an Joseph Redmon und Ali Farhadi für die Entwicklung des originalen YOLOv3.
|
||||
|
|
@ -1,71 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erforschen Sie unseren detaillierten Leitfaden zu YOLOv4, einem hochmodernen Echtzeit-Objektdetektor. Erfahren Sie mehr über seine architektonischen Highlights, innovativen Funktionen und Anwendungsbeispiele.
|
||||
keywords: ultralytics, YOLOv4, Objekterkennung, neuronales Netzwerk, Echtzeit-Erkennung, Objektdetektor, maschinelles Lernen
|
||||
---
|
||||
|
||||
# YOLOv4: Schnelle und präzise Objekterkennung
|
||||
|
||||
Willkommen auf der Ultralytics-Dokumentationsseite für YOLOv4, einem hochmodernen, Echtzeit-Objektdetektor, der 2020 von Alexey Bochkovskiy unter [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet) veröffentlicht wurde. YOLOv4 wurde entwickelt, um das optimale Gleichgewicht zwischen Geschwindigkeit und Genauigkeit zu bieten und ist somit eine ausgezeichnete Wahl für viele Anwendungen.
|
||||
|
||||

|
||||
**YOLOv4 Architekturdiagramm**. Zeigt das komplexe Netzwerkdesign von YOLOv4, einschließlich der Backbone-, Neck- und Head-Komponenten sowie ihrer verbundenen Schichten für eine optimale Echtzeit-Objekterkennung.
|
||||
|
||||
## Einleitung
|
||||
|
||||
YOLOv4 steht für You Only Look Once Version 4. Es handelt sich um ein Echtzeit-Objekterkennungsmodell, das entwickelt wurde, um die Grenzen früherer YOLO-Versionen wie [YOLOv3](yolov3.md) und anderer Objekterkennungsmodelle zu überwinden. Im Gegensatz zu anderen konvolutionellen neuronalen Netzwerken (CNN), die auf Objekterkennung basieren, ist YOLOv4 nicht nur für Empfehlungssysteme geeignet, sondern auch für eigenständiges Prozessmanagement und Reduzierung der Benutzereingabe. Durch den Einsatz von herkömmlichen Grafikprozessoreinheiten (GPUs) ermöglicht es YOLOv4 eine Massennutzung zu einem erschwinglichen Preis und ist so konzipiert, dass es in Echtzeit auf einer herkömmlichen GPU funktioniert, wobei nur eine solche GPU für das Training erforderlich ist.
|
||||
|
||||
## Architektur
|
||||
|
||||
YOLOv4 nutzt mehrere innovative Funktionen, die zusammenarbeiten, um seine Leistung zu optimieren. Dazu gehören Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT), Mish-Aktivierung, Mosaic-Datenaugmentation, DropBlock-Regularisierung und CIoU-Verlust. Diese Funktionen werden kombiniert, um erstklassige Ergebnisse zu erzielen.
|
||||
|
||||
Ein typischer Objektdetektor besteht aus mehreren Teilen, darunter der Eingabe, dem Backbone, dem Neck und dem Head. Das Backbone von YOLOv4 ist auf ImageNet vorgeschult und wird zur Vorhersage von Klassen und Begrenzungsrahmen von Objekten verwendet. Das Backbone kann aus verschiedenen Modellen wie VGG, ResNet, ResNeXt oder DenseNet stammen. Der Neck-Teil des Detektors wird verwendet, um Merkmalskarten von verschiedenen Stufen zu sammeln und umfasst normalerweise mehrere Bottom-up-Pfade und mehrere Top-down-Pfade. Der Head-Teil wird schließlich zur Durchführung der endgültigen Objekterkennung und Klassifizierung verwendet.
|
||||
|
||||
## Bag of Freebies
|
||||
|
||||
YOLOv4 verwendet auch Methoden, die als "Bag of Freebies" bekannt sind. Dabei handelt es sich um Techniken, die die Genauigkeit des Modells während des Trainings verbessern, ohne die Kosten der Inferenz zu erhöhen. Datenaugmentation ist eine häufige Bag of Freebies-Technik, die in der Objekterkennung verwendet wird, um die Variabilität der Eingabebilder zu erhöhen und die Robustheit des Modells zu verbessern. Beispiele für Datenaugmentation sind photometrische Verzerrungen (Anpassung von Helligkeit, Kontrast, Farbton, Sättigung und Rauschen eines Bildes) und geometrische Verzerrungen (Hinzufügen von zufälliger Skalierung, Ausschnitt, Spiegelung und Rotation). Diese Techniken helfen dem Modell, sich besser an verschiedene Arten von Bildern anzupassen.
|
||||
|
||||
## Funktionen und Leistung
|
||||
|
||||
YOLOv4 ist für optimale Geschwindigkeit und Genauigkeit in der Objekterkennung konzipiert. Die Architektur von YOLOv4 umfasst CSPDarknet53 als Backbone, PANet als Neck und YOLOv3 als Detektionskopf. Diese Konstruktion ermöglicht es YOLOv4, beeindruckend schnelle Objekterkennungen durchzuführen und ist somit für Echtzeitanwendungen geeignet. YOLOv4 zeichnet sich auch durch Genauigkeit aus und erzielt erstklassige Ergebnisse in Objekterkennungs-Benchmarks.
|
||||
|
||||
## Beispiele für die Verwendung
|
||||
|
||||
Zum Zeitpunkt der Erstellung dieser Dokumentation unterstützt Ultralytics derzeit keine YOLOv4-Modelle. Daher müssen sich Benutzer, die YOLOv4 verwenden möchten, direkt an das YOLOv4 GitHub-Repository für Installations- und Verwendungshinweise wenden.
|
||||
|
||||
Hier ist ein kurzer Überblick über die typischen Schritte, die Sie unternehmen könnten, um YOLOv4 zu verwenden:
|
||||
|
||||
1. Besuchen Sie das YOLOv4 GitHub-Repository: [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet).
|
||||
|
||||
2. Befolgen Sie die in der README-Datei bereitgestellten Anweisungen zur Installation. Dies beinhaltet in der Regel das Klonen des Repositories, die Installation der erforderlichen Abhängigkeiten und das Einrichten der erforderlichen Umgebungsvariablen.
|
||||
|
||||
3. Sobald die Installation abgeschlossen ist, können Sie das Modell gemäß den in dem Repository bereitgestellten Verwendungshinweisen trainieren und verwenden. Dies beinhaltet in der Regel die Vorbereitung des Datensatzes, die Konfiguration der Modellparameter, das Training des Modells und die anschließende Verwendung des trainierten Modells zur Durchführung der Objekterkennung.
|
||||
|
||||
Bitte beachten Sie, dass die spezifischen Schritte je nach Ihrer spezifischen Anwendung und dem aktuellen Stand des YOLOv4-Repositories variieren können. Es wird daher dringend empfohlen, sich direkt an die Anweisungen im YOLOv4-GitHub-Repository zu halten.
|
||||
|
||||
Wir bedauern etwaige Unannehmlichkeiten und werden uns bemühen, dieses Dokument mit Verwendungsbeispielen für Ultralytics zu aktualisieren, sobald die Unterstützung für YOLOv4 implementiert ist.
|
||||
|
||||
## Fazit
|
||||
|
||||
YOLOv4 ist ein leistungsstarkes und effizientes Modell zur Objekterkennung, das eine Balance zwischen Geschwindigkeit und Genauigkeit bietet. Durch den Einsatz einzigartiger Funktionen und Bag of Freebies-Techniken während des Trainings erzielt es hervorragende Ergebnisse in Echtzeit-Objekterkennungsaufgaben. YOLOv4 kann von jedem mit einer herkömmlichen GPU trainiert und verwendet werden, was es für eine Vielzahl von Anwendungen zugänglich und praktisch macht.
|
||||
|
||||
## Zitate und Anerkennungen
|
||||
|
||||
Wir möchten den Autoren von YOLOv4 für ihren bedeutenden Beitrag auf dem Gebiet der Echtzeit-Objekterkennung danken:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{bochkovskiy2020yolov4,
|
||||
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
|
||||
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
|
||||
year={2020},
|
||||
eprint={2004.10934},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
Die originale YOLOv4-Publikation finden Sie auf [arXiv](https://arxiv.org/pdf/2004.10934.pdf). Die Autoren haben ihre Arbeit öffentlich zugänglich gemacht und der Code kann auf [GitHub](https://github.com/AlexeyAB/darknet) abgerufen werden. Wir schätzen ihre Bemühungen, das Fachgebiet voranzubringen und ihre Arbeit der breiteren Community zugänglich zu machen.
|
||||
|
|
@ -1,113 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Entdecken Sie YOLOv5u, eine verbesserte Version des YOLOv5-Modells mit einem optimierten Verhältnis von Genauigkeit und Geschwindigkeit sowie zahlreiche vorab trainierte Modelle für verschiedene Objekterkennungsaufgaben.
|
||||
keywords: YOLOv5u, Objekterkennung, vorab trainierte Modelle, Ultralytics, Inferenz, Validierung, YOLOv5, YOLOv8, Ankerfrei, Objektlos, Echtzeitanwendungen, Maschinelles Lernen
|
||||
---
|
||||
|
||||
# YOLOv5
|
||||
|
||||
## Übersicht
|
||||
|
||||
YOLOv5u steht für eine Weiterentwicklung der Methoden zur Objekterkennung. Basierend auf der grundlegenden Architektur des von Ultralytics entwickelten YOLOv5-Modells integriert YOLOv5u den ankerfreien, objektlosen Split-Kopf, ein Feature, das zuvor in den YOLOv8-Modellen eingeführt wurde. Diese Anpassung verfeinert die Architektur des Modells und führt zu einem optimierten Verhältnis von Genauigkeit und Geschwindigkeit bei der Objekterkennung. Basierend auf den empirischen Ergebnissen und den abgeleiteten Features bietet YOLOv5u eine effiziente Alternative für diejenigen, die robuste Lösungen sowohl in der Forschung als auch in praktischen Anwendungen suchen.
|
||||
|
||||

|
||||
|
||||
## Hauptmerkmale
|
||||
|
||||
- **Ankerfreier Split-Ultralytics-Kopf:** Herkömmliche Objekterkennungsmodelle verwenden vordefinierte Ankerboxen, um die Position von Objekten vorherzusagen. YOLOv5u modernisiert diesen Ansatz. Durch die Verwendung eines ankerfreien Split-Ultralytics-Kopfes wird ein flexiblerer und anpassungsfähigerer Detektionsmechanismus gewährleistet, der die Leistung in verschiedenen Szenarien verbessert.
|
||||
|
||||
- **Optimiertes Verhältnis von Genauigkeit und Geschwindigkeit:** Geschwindigkeit und Genauigkeit ziehen oft in entgegengesetzte Richtungen. Aber YOLOv5u stellt diese Abwägung in Frage. Es bietet eine ausgewogene Balance, die Echtzeitdetektionen ohne Einbußen bei der Genauigkeit ermöglicht. Diese Funktion ist besonders wertvoll für Anwendungen, die schnelle Reaktionen erfordern, wie autonome Fahrzeuge, Robotik und Echtzeitanalyse von Videos.
|
||||
|
||||
- **Vielfalt an vorab trainierten Modellen:** YOLOv5u bietet eine Vielzahl von vorab trainierten Modellen, da verschiedene Aufgaben unterschiedliche Werkzeuge erfordern. Ob Sie sich auf Inferenz, Validierung oder Training konzentrieren, es wartet ein maßgeschneidertes Modell auf Sie. Diese Vielfalt gewährleistet, dass Sie nicht nur eine Einheitslösung verwenden, sondern ein speziell für Ihre einzigartige Herausforderung feinabgestimmtes Modell.
|
||||
|
||||
## Unterstützte Aufgaben und Modi
|
||||
|
||||
Die YOLOv5u-Modelle mit verschiedenen vorab trainierten Gewichten eignen sich hervorragend für Aufgaben zur [Objekterkennung](../tasks/detect.md). Sie unterstützen eine umfassende Palette von Modi, die sie für verschiedene Anwendungen von der Entwicklung bis zur Bereitstellung geeignet machen.
|
||||
|
||||
| Modelltyp | Vorab trainierte Gewichte | Aufgabe | Inferenz | Validierung | Training | Export |
|
||||
|-----------|-----------------------------------------------------------------------------------------------------------------------------|---------------------------------------|----------|-------------|----------|--------|
|
||||
| YOLOv5u | `yolov5nu`, `yolov5su`, `yolov5mu`, `yolov5lu`, `yolov5xu`, `yolov5n6u`, `yolov5s6u`, `yolov5m6u`, `yolov5l6u`, `yolov5x6u` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
Diese Tabelle bietet eine detaillierte Übersicht über die verschiedenen Varianten des YOLOv5u-Modells und hebt ihre Anwendbarkeit in der Objekterkennung sowie die Unterstützung unterschiedlicher Betriebsmodi wie [Inferenz](../modes/predict.md), [Validierung](../modes/val.md), [Training](../modes/train.md) und [Export](../modes/export.md) hervor. Diese umfassende Unterstützung ermöglicht es Benutzern, die Fähigkeiten der YOLOv5u-Modelle in einer Vielzahl von Objekterkennungsszenarien voll auszuschöpfen.
|
||||
|
||||
## Leistungskennzahlen
|
||||
|
||||
!!! Leistung
|
||||
|
||||
=== "Erkennung"
|
||||
|
||||
Siehe [Erkennungsdokumentation](https://docs.ultralytics.com/tasks/detect/) für Beispiele zur Verwendung dieser Modelle, die auf [COCO](https://docs.ultralytics.com/datasets/detect/coco/) trainiert wurden und 80 vorab trainierte Klassen enthalten.
|
||||
|
||||
| Modell | YAML | Größe<br><sup>(Pixel) | mAP<sup>val<br>50-95 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
|---------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------|-----------------------|----------------------|------------------------------------------|-----------------------------------------------|--------------------|-------------------|
|
||||
| [yolov5nu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5nu.pt) | [yolov5n.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 34,3 | 73,6 | 1,06 | 2,6 | 7,7 |
|
||||
| [yolov5su.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5su.pt) | [yolov5s.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 43,0 | 120,7 | 1,27 | 9,1 | 24,0 |
|
||||
| [yolov5mu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5mu.pt) | [yolov5m.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 49,0 | 233,9 | 1,86 | 25,1 | 64,2 |
|
||||
| [yolov5lu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5lu.pt) | [yolov5l.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 52,2 | 408,4 | 2,50 | 53,2 | 135,0 |
|
||||
| [yolov5xu.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5xu.pt) | [yolov5x.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 53,2 | 763,2 | 3,81 | 97,2 | 246,4 |
|
||||
| | | | | | | | |
|
||||
| [yolov5n6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5n6u.pt) | [yolov5n6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1.280 | 42,1 | 211,0 | 1,83 | 4,3 | 7,8 |
|
||||
| [yolov5s6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5s6u.pt) | [yolov5s6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1.280 | 48,6 | 422,6 | 2,34 | 15,3 | 24,6 |
|
||||
| [yolov5m6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5m6u.pt) | [yolov5m6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1.280 | 53,6 | 810,9 | 4,36 | 41,2 | 65,7 |
|
||||
| [yolov5l6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5l6u.pt) | [yolov5l6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1.280 | 55,7 | 1.470,9 | 5,47 | 86,1 | 137,4 |
|
||||
| [yolov5x6u.pt](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5x6u.pt) | [yolov5x6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1.280 | 56,8 | 2.436,5 | 8,98 | 155,4 | 250,7 |
|
||||
|
||||
## Beispiele zur Verwendung
|
||||
|
||||
Dieses Beispiel enthält einfache Beispiele zur Schulung und Inferenz mit YOLOv5. Die vollständige Dokumentation zu diesen und anderen [Modi](../modes/index.md) finden Sie in den Seiten [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) und [Export](../modes/export.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
PyTorch-vortrainierte `*.pt`-Modelle sowie Konfigurationsdateien `*.yaml` können an die `YOLO()`-Klasse übergeben werden, um eine Modellinstanz in Python zu erstellen:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie ein vortrainiertes YOLOv5n-Modell für COCO-Daten
|
||||
modell = YOLO('yolov5n.pt')
|
||||
|
||||
# Informationen zum Modell anzeigen (optional)
|
||||
model.info()
|
||||
|
||||
# Trainieren Sie das Modell anhand des COCO8-Beispieldatensatzes für 100 Epochen
|
||||
ergebnisse = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# Führen Sie die Inferenz mit dem YOLOv5n-Modell auf dem Bild 'bus.jpg' durch
|
||||
ergebnisse = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
CLI-Befehle sind verfügbar, um die Modelle direkt auszuführen:
|
||||
|
||||
```bash
|
||||
# Laden Sie ein vortrainiertes YOLOv5n-Modell und trainieren Sie es anhand des COCO8-Beispieldatensatzes für 100 Epochen
|
||||
yolo train model=yolov5n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# Laden Sie ein vortrainiertes YOLOv5n-Modell und führen Sie die Inferenz auf dem Bild 'bus.jpg' durch
|
||||
yolo predict model=yolov5n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Zitate und Danksagungen
|
||||
|
||||
Wenn Sie YOLOv5 oder YOLOv5u in Ihrer Forschung verwenden, zitieren Sie bitte das Ultralytics YOLOv5-Repository wie folgt:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
```bibtex
|
||||
@software{yolov5,
|
||||
title = {Ultralytics YOLOv5},
|
||||
author = {Glenn Jocher},
|
||||
year = {2020},
|
||||
version = {7.0},
|
||||
license = {AGPL-3.0},
|
||||
url = {https://github.com/ultralytics/yolov5},
|
||||
doi = {10.5281/zenodo.3908559},
|
||||
orcid = {0000-0001-5950-6979}
|
||||
}
|
||||
```
|
||||
|
||||
Bitte beachten Sie, dass die YOLOv5-Modelle unter den Lizenzen [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) und [Enterprise](https://ultralytics.com/license) bereitgestellt werden.
|
||||
|
|
@ -1,107 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erforschen Sie Meituan YOLOv6, ein modernes Objekterkennungsmodell, das eine ausgewogene Kombination aus Geschwindigkeit und Genauigkeit bietet. Tauchen Sie ein in Funktionen, vorab trainierte Modelle und die Verwendung von Python.
|
||||
keywords: Meituan YOLOv6, Objekterkennung, Ultralytics, YOLOv6 Dokumentation, Bi-direktionale Konkatenation, Anchor-Aided Training, vorab trainierte Modelle, Echtzeitanwendungen
|
||||
---
|
||||
|
||||
# Meituan YOLOv6
|
||||
|
||||
## Überblick
|
||||
|
||||
[Meituan](https://about.meituan.com/) YOLOv6 ist ein moderner Objekterkenner, der eine bemerkenswerte Balance zwischen Geschwindigkeit und Genauigkeit bietet und somit eine beliebte Wahl für Echtzeitanwendungen darstellt. Dieses Modell bietet mehrere bemerkenswerte Verbesserungen in seiner Architektur und seinem Trainingsschema, einschließlich der Implementierung eines Bi-direktionalen Konkatenationsmoduls (BiC), einer anchor-aided training (AAT)-Strategie und einem verbesserten Backpropagation- und Neck-Design für Spitzenleistungen auf dem COCO-Datensatz.
|
||||
|
||||

|
||||

|
||||
**Übersicht über YOLOv6.** Diagramm der Modellarchitektur, das die neu gestalteten Netzwerkkomponenten und Trainingstrategien zeigt, die zu signifikanten Leistungsverbesserungen geführt haben. (a) Der Nacken von YOLOv6 (N und S sind dargestellt). Beachten Sie, dass bei M/L RepBlocks durch CSPStackRep ersetzt wird. (b) Die Struktur eines BiC-Moduls. (c) Ein SimCSPSPPF-Block. ([Quelle](https://arxiv.org/pdf/2301.05586.pdf)).
|
||||
|
||||
### Hauptmerkmale
|
||||
|
||||
- **Bi-direktionales Konkatenations (BiC) Modul:** YOLOv6 führt ein BiC-Modul im Nacken des Erkenners ein, das die Lokalisierungssignale verbessert und eine Leistungssteigerung bei vernachlässigbarem Geschwindigkeitsabfall liefert.
|
||||
- **Anchor-aided Training (AAT) Strategie:** Dieses Modell schlägt AAT vor, um die Vorteile sowohl von ankerbasierten als auch von ankerfreien Paradigmen zu nutzen, ohne die Inferenzeffizienz zu beeinträchtigen.
|
||||
- **Verbessertes Backpropagation- und Neck-Design:** Durch Vertiefung von YOLOv6 um eine weitere Stufe im Backpropagation und Nacken erreicht dieses Modell Spitzenleistungen auf dem COCO-Datensatz bei hochauflösenden Eingaben.
|
||||
- **Self-Distillation Strategie:** Eine neue Self-Distillation-Strategie wird implementiert, um die Leistung von kleineren Modellen von YOLOv6 zu steigern, indem der Hilfsregressionszweig während des Trainings verstärkt und bei der Inferenz entfernt wird, um einen deutlichen Geschwindigkeitsabfall zu vermeiden.
|
||||
|
||||
## Leistungsmetriken
|
||||
|
||||
YOLOv6 bietet verschiedene vorab trainierte Modelle mit unterschiedlichen Maßstäben:
|
||||
|
||||
- YOLOv6-N: 37,5% AP auf COCO val2017 bei 1187 FPS mit NVIDIA Tesla T4 GPU.
|
||||
- YOLOv6-S: 45,0% AP bei 484 FPS.
|
||||
- YOLOv6-M: 50,0% AP bei 226 FPS.
|
||||
- YOLOv6-L: 52,8% AP bei 116 FPS.
|
||||
- YOLOv6-L6: Spitzenleistung in Echtzeit.
|
||||
|
||||
YOLOv6 bietet auch quantisierte Modelle für verschiedene Genauigkeiten sowie Modelle, die für mobile Plattformen optimiert sind.
|
||||
|
||||
## Beispiele zur Verwendung
|
||||
|
||||
In diesem Beispiel werden einfache Schulungs- und Inferenzbeispiele für YOLOv6 bereitgestellt. Weitere Dokumentation zu diesen und anderen [Modi](../modes/index.md) finden Sie auf den Seiten [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) und [Export](../modes/export.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
In Python kann PyTorch-vorab trainierte `*.pt`-Modelle sowie Konfigurations-`*.yaml`-Dateien an die `YOLO()`-Klasse übergeben werden, um eine Modellinstanz zu erstellen:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Erstellen Sie ein YOLOv6n-Modell von Grund auf
|
||||
model = YOLO('yolov6n.yaml')
|
||||
|
||||
# Zeigen Sie Informationen zum Modell an (optional)
|
||||
model.info()
|
||||
|
||||
# Trainieren Sie das Modell am Beispiel des COCO8-Datensatzes für 100 Epochen
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# Führen Sie Inferenz mit dem YOLOv6n-Modell auf dem Bild 'bus.jpg' durch
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
CLI-Befehle stehen zur Verfügung, um die Modelle direkt auszuführen:
|
||||
|
||||
```bash
|
||||
# Erstellen Sie ein YOLOv6n-Modell von Grund auf und trainieren Sie es am Beispiel des COCO8-Datensatzes für 100 Epochen
|
||||
yolo train model=yolov6n.yaml data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# Erstellen Sie ein YOLOv6n-Modell von Grund auf und führen Sie Inferenz auf dem Bild 'bus.jpg' durch
|
||||
yolo predict model=yolov6n.yaml source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Unterstützte Aufgaben und Modi
|
||||
|
||||
Die YOLOv6-Serie bietet eine Reihe von Modellen, die jeweils für die Hochleistungs-[Objekterkennung](../tasks/detect.md) optimiert sind. Diese Modelle erfüllen unterschiedliche Rechenanforderungen und Genauigkeitsanforderungen und sind daher vielseitig für eine Vielzahl von Anwendungen einsetzbar.
|
||||
|
||||
| Modelltyp | Vorab trainierte Gewichte | Unterstützte Aufgaben | Inferenz | Validierung | Training | Exportieren |
|
||||
|-----------|---------------------------|---------------------------------------|----------|-------------|----------|-------------|
|
||||
| YOLOv6-N | `yolov6-n.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-S | `yolov6-s.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-M | `yolov6-m.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-L | `yolov6-l.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv6-L6 | `yolov6-l6.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
Diese Tabelle bietet einen detaillierten Überblick über die YOLOv6-Modellvarianten und hebt ihre Fähigkeiten bei der Objekterkennung sowie ihre Kompatibilität mit verschiedenen Betriebsmodi wie [Inferenz](../modes/predict.md), [Validierung](../modes/val.md), [Training](../modes/train.md) und [Exportieren](../modes/export.md) hervor. Diese umfassende Unterstützung ermöglicht es den Benutzern, die Fähigkeiten von YOLOv6-Modellen in einer Vielzahl von Objekterkennungsszenarien vollständig zu nutzen.
|
||||
|
||||
## Zitate und Anerkennungen
|
||||
|
||||
Wir möchten den Autoren für ihre bedeutenden Beiträge auf dem Gebiet der Echtzeit-Objekterkennung danken:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{li2023yolov6,
|
||||
title={YOLOv6 v3.0: A Full-Scale Reloading},
|
||||
author={Chuyi Li and Lulu Li and Yifei Geng and Hongliang Jiang and Meng Cheng and Bo Zhang and Zaidan Ke and Xiaoming Xu and Xiangxiang Chu},
|
||||
year={2023},
|
||||
eprint={2301.05586},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
Das ursprüngliche YOLOv6-Papier finden Sie auf [arXiv](https://arxiv.org/abs/2301.05586). Die Autoren haben ihre Arbeit öffentlich zugänglich gemacht, und der Code kann auf [GitHub](https://github.com/meituan/YOLOv6) abgerufen werden. Wir schätzen ihre Bemühungen zur Weiterentwicklung des Fachgebiets und zur Zugänglichmachung ihrer Arbeit für die breitere Gemeinschaft.
|
||||
|
|
@ -1,66 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erforsche den YOLOv7, einen echtzeitfähigen Objektdetektor. Verstehe seine überlegene Geschwindigkeit, beeindruckende Genauigkeit und seinen einzigartigen Fokus auf die optimierte Ausbildung mit "trainable bag-of-freebies".
|
||||
keywords: YOLOv7, echtzeitfähiger Objektdetektor, State-of-the-Art, Ultralytics, MS COCO Datensatz, Modellumparameterisierung, dynamische Labelzuweisung, erweiterte Skalierung, umfassende Skalierung
|
||||
---
|
||||
|
||||
# YOLOv7: Trainable Bag-of-Freebies
|
||||
|
||||
YOLOv7 ist ein echtzeitfähiger Objektdetektor der Spitzenklasse, der alle bekannten Objektdetektoren in Bezug auf Geschwindigkeit und Genauigkeit im Bereich von 5 FPS bis 160 FPS übertrifft. Mit einer Genauigkeit von 56,8% AP ist er der präziseste Echtzeit-Objektdetektor unter allen bekannten Modellen mit einer FPS von 30 oder höher auf der GPU V100. Darüber hinaus übertrifft YOLOv7 andere Objektdetektoren wie YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5 und viele andere in Bezug auf Geschwindigkeit und Genauigkeit. Das Modell wird ausschließlich auf dem MS COCO-Datensatz trainiert, ohne andere Datensätze oder vortrainierte Gewichte zu verwenden. Sourcecode für YOLOv7 ist auf GitHub verfügbar.
|
||||
|
||||

|
||||
**Vergleich von Spitzen-Objektdetektoren.
|
||||
** Aus den Ergebnissen in Tabelle 2 wissen wir, dass die vorgeschlagene Methode das beste Verhältnis von Geschwindigkeit und Genauigkeit umfassend aufweist. Vergleichen wir YOLOv7-tiny-SiLU mit YOLOv5-N (r6.1), so ist unsere Methode 127 FPS schneller und um 10,7% genauer beim AP. Darüber hinaus erreicht YOLOv7 bei einer Bildrate von 161 FPS einen AP von 51,4%, während PPYOLOE-L mit demselben AP nur eine Bildrate von 78 FPS aufweist. In Bezug auf die Parameterverwendung ist YOLOv7 um 41% geringer als PPYOLOE-L. Vergleicht man YOLOv7-X mit 114 FPS Inferenzgeschwindigkeit mit YOLOv5-L (r6.1) mit 99 FPS Inferenzgeschwindigkeit, kann YOLOv7-X den AP um 3,9% verbessern. Wenn YOLOv7-X mit YOLOv5-X (r6.1) in ähnlichem Maßstab verglichen wird, ist die Inferenzgeschwindigkeit von YOLOv7-X 31 FPS schneller. Darüber hinaus reduziert YOLOv7-X in Bezug auf die Anzahl der Parameter und Berechnungen 22% der Parameter und 8% der Berechnungen im Vergleich zu YOLOv5-X (r6.1), verbessert jedoch den AP um 2,2% ([Source](https://arxiv.org/pdf/2207.02696.pdf)).
|
||||
|
||||
## Übersicht
|
||||
|
||||
Echtzeit-Objekterkennung ist eine wichtige Komponente vieler Computersysteme für Bildverarbeitung, einschließlich Multi-Object-Tracking, autonomes Fahren, Robotik und medizinische Bildanalyse. In den letzten Jahren konzentrierte sich die Entwicklung der Echtzeit-Objekterkennung auf die Gestaltung effizienter Architekturen und die Verbesserung der Inferenzgeschwindigkeit verschiedener CPUs, GPUs und Neural Processing Units (NPUs). YOLOv7 unterstützt sowohl mobile GPUs als auch GPU-Geräte, von der Edge bis zur Cloud.
|
||||
|
||||
Im Gegensatz zu herkömmlichen, echtzeitfähigen Objektdetektoren, die sich auf die Architekturoptimierung konzentrieren, führt YOLOv7 eine Fokussierung auf die Optimierung des Schulungsprozesses ein. Dazu gehören Module und Optimierungsmethoden, die darauf abzielen, die Genauigkeit der Objekterkennung zu verbessern, ohne die Inferenzkosten zu erhöhen - ein Konzept, das als "trainable bag-of-freebies" bekannt ist.
|
||||
|
||||
## Hauptmerkmale
|
||||
|
||||
YOLOv7 führt mehrere Schlüsselfunktionen ein:
|
||||
|
||||
1. **Modellumparameterisierung**: YOLOv7 schlägt ein geplantes umparameterisiertes Modell vor, das eine in verschiedenen Netzwerken anwendbare Strategie darstellt und auf dem Konzept des Gradientenpropagationspfades basiert.
|
||||
|
||||
2. **Dynamische Labelzuweisung**: Das Training des Modells mit mehreren Ausgabeschichten stellt ein neues Problem dar: "Wie weist man dynamische Ziele für die Ausgaben der verschiedenen Zweige zu?" Zur Lösung dieses Problems führt YOLOv7 eine neue Methode zur Labelzuweisung ein, die als coarse-to-fine lead guided label assignment bekannt ist.
|
||||
|
||||
3. **Erweiterte und umfassende Skalierung**: YOLOv7 schlägt Methoden zur "erweiterten" und "umfassenden Skalierung" des echtzeitfähigen Objektdetektors vor, die Parameter und Berechnungen effektiv nutzen können.
|
||||
|
||||
4. **Effizienz**: Die von YOLOv7 vorgeschlagene Methode kann etwa 40 % der Parameter und 50 % der Berechnungen des state-of-the-art echtzeitfähigen Objektdetektors wirksam reduzieren und weist eine schnellere Inferenzgeschwindigkeit und eine höhere Detektionsgenauigkeit auf.
|
||||
|
||||
## Beispiele zur Nutzung
|
||||
|
||||
Zum Zeitpunkt der Erstellung dieses Textes unterstützt Ultralytics derzeit keine YOLOv7-Modelle. Daher müssen sich alle Benutzer, die YOLOv7 verwenden möchten, direkt an das YOLOv7 GitHub-Repository für Installations- und Nutzungshinweise wenden.
|
||||
|
||||
Hier ist ein kurzer Überblick über die typischen Schritte, die Sie unternehmen könnten, um YOLOv7 zu verwenden:
|
||||
|
||||
1. Besuchen Sie das YOLOv7 GitHub-Repository: [https://github.com/WongKinYiu/yolov7](https://github.com/WongKinYiu/yolov7).
|
||||
|
||||
2. Befolgen Sie die in der README-Datei bereitgestellten Anweisungen zur Installation. Dies beinhaltet in der Regel das Klonen des Repositories, die Installation der erforderlichen Abhängigkeiten und das Einrichten eventuell notwendiger Umgebungsvariablen.
|
||||
|
||||
3. Sobald die Installation abgeschlossen ist, können Sie das Modell entsprechend den im Repository bereitgestellten Anleitungen trainieren und verwenden. Dies umfasst in der Regel die Vorbereitung des Datensatzes, das Konfigurieren der Modellparameter, das Training des Modells und anschließend die Verwendung des trainierten Modells zur Durchführung der Objekterkennung.
|
||||
|
||||
Bitte beachten Sie, dass die spezifischen Schritte je nach Ihrem spezifischen Anwendungsfall und dem aktuellen Stand des YOLOv7-Repositories variieren können. Es wird daher dringend empfohlen, sich direkt an die im YOLOv7 GitHub-Repository bereitgestellten Anweisungen zu halten.
|
||||
|
||||
Wir bedauern etwaige Unannehmlichkeiten und werden uns bemühen, dieses Dokument mit Anwendungsbeispielen für Ultralytics zu aktualisieren, sobald die Unterstützung für YOLOv7 implementiert ist.
|
||||
|
||||
## Zitationen und Danksagungen
|
||||
|
||||
Wir möchten den Autoren von YOLOv7 für ihre bedeutenden Beiträge im Bereich der echtzeitfähigen Objekterkennung danken:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{wang2022yolov7,
|
||||
title={{YOLOv7}: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors},
|
||||
author={Wang, Chien-Yao and Bochkovskiy, Alexey and Liao, Hong-Yuan Mark},
|
||||
journal={arXiv preprint arXiv:2207.02696},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
|
||||
Die ursprüngliche YOLOv7-Studie kann auf [arXiv](https://arxiv.org/pdf/2207.02696.pdf) gefunden werden. Die Autoren haben ihre Arbeit öffentlich zugänglich gemacht, und der Code kann auf [GitHub](https://github.com/WongKinYiu/yolov7) abgerufen werden. Wir schätzen ihre Bemühungen, das Feld voranzubringen und ihre Arbeit der breiteren Gemeinschaft zugänglich zu machen.
|
||||
|
|
@ -1,162 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie mehr über die aufregenden Funktionen von YOLOv8, der neuesten Version unseres Echtzeit-Objekterkenners! Erfahren Sie, wie fortschrittliche Architekturen, vortrainierte Modelle und die optimale Balance zwischen Genauigkeit und Geschwindigkeit YOLOv8 zur perfekten Wahl für Ihre Objekterkennungsaufgaben machen.
|
||||
keywords: YOLOv8, Ultralytics, Echtzeit-Objekterkennung, vortrainierte Modelle, Dokumentation, Objekterkennung, YOLO-Serie, fortschrittliche Architekturen, Genauigkeit, Geschwindigkeit
|
||||
---
|
||||
|
||||
# YOLOv8
|
||||
|
||||
## Übersicht
|
||||
|
||||
YOLOv8 ist die neueste Version der YOLO-Serie von Echtzeit-Objekterkennern und bietet modernste Leistung in Bezug auf Genauigkeit und Geschwindigkeit. Basierend auf den Fortschritten früherer YOLO-Versionen bringt YOLOv8 neue Funktionen und Optimierungen mit sich, die ihn zu einer idealen Wahl für verschiedene Objekterkennungsaufgaben in einer Vielzahl von Anwendungen machen.
|
||||
|
||||

|
||||
|
||||
## Schlüsselfunktionen
|
||||
|
||||
- **Fortschrittliche Backbone- und Neck-Architekturen:** YOLOv8 verwendet modernste Backbone- und Neck-Architekturen, die zu einer verbesserten Merkmalsextraktion und Objekterkennungsleistung führen.
|
||||
- **Ankerfreier Split Ultralytics Head:** YOLOv8 verwendet einen ankerfreien Split Ultralytics Head, der zu einer besseren Genauigkeit und einem effizienteren Erkennungsprozess im Vergleich zu ankerbasierten Ansätzen führt.
|
||||
- **Optimale Genauigkeits-Geschwindigkeits-Balance:** Mit dem Fokus auf die Aufrechterhaltung einer optimalen Balance zwischen Genauigkeit und Geschwindigkeit eignet sich YOLOv8 für Echtzeit-Objekterkennungsaufgaben in verschiedenen Anwendungsbereichen.
|
||||
- **Vielfalt an vortrainierten Modellen:** YOLOv8 bietet eine Vielzahl von vortrainierten Modellen, um verschiedenen Aufgaben und Leistungsanforderungen gerecht zu werden. Dies erleichtert die Suche nach dem richtigen Modell für Ihren spezifischen Anwendungsfall.
|
||||
|
||||
## Unterstützte Aufgaben und Modi
|
||||
|
||||
Die YOLOv8-Serie bietet eine Vielzahl von Modellen, von denen jedes auf bestimmte Aufgaben in der Computer Vision spezialisiert ist. Diese Modelle sind so konzipiert, dass sie verschiedenen Anforderungen gerecht werden, von der Objekterkennung bis hin zu komplexeren Aufgaben wie Instanzsegmentierung, Pose/Keypoint-Erkennung und Klassifikation.
|
||||
|
||||
Jede Variante der YOLOv8-Serie ist auf ihre jeweilige Aufgabe optimiert und gewährleistet damit hohe Leistung und Genauigkeit. Darüber hinaus sind diese Modelle kompatibel mit verschiedenen Betriebsmodi, einschließlich [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md) und [Export](../modes/export.md). Dadurch wird ihre Verwendung in verschiedenen Phasen der Bereitstellung und Entwicklung erleichtert.
|
||||
|
||||
| Modell | Dateinamen | Aufgabe | Inference | Validation | Training | Export |
|
||||
|-------------|----------------------------------------------------------------------------------------------------------------|---------------------------------------------|-----------|------------|----------|--------|
|
||||
| YOLOv8 | `yolov8n.pt` `yolov8s.pt` `yolov8m.pt` `yolov8l.pt` `yolov8x.pt` | [Objekterkennung](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv8-seg | `yolov8n-seg.pt` `yolov8s-seg.pt` `yolov8m-seg.pt` `yolov8l-seg.pt` `yolov8x-seg.pt` | [Instanzsegmentierung](../tasks/segment.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv8-pose | `yolov8n-pose.pt` `yolov8s-pose.pt` `yolov8m-pose.pt` `yolov8l-pose.pt` `yolov8x-pose.pt` `yolov8x-pose-p6.pt` | [Pose/Keypoints](../tasks/pose.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
| YOLOv8-cls | `yolov8n-cls.pt` `yolov8s-cls.pt` `yolov8m-cls.pt` `yolov8l-cls.pt` `yolov8x-cls.pt` | [Klassifikation](../tasks/classify.md) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
Diese Tabelle gibt einen Überblick über die verschiedenen Varianten des YOLOv8-Modells und deren Anwendungsbereiche sowie deren Kompatibilität mit verschiedenen Betriebsmodi wie Inference, Validation, Training und Export. Sie zeigt die Vielseitigkeit und Robustheit der YOLOv8-Serie, was sie für verschiedene Anwendungen in der Computer Vision geeignet macht.
|
||||
|
||||
## Leistungskennzahlen
|
||||
|
||||
!!! Performance
|
||||
|
||||
=== "Objekterkennung (COCO)"
|
||||
|
||||
Siehe [Objekterkennungsdokumentation](https://docs.ultralytics.com/tasks/detect/) für Beispiele zur Verwendung dieser Modelle, die auf [COCO](https://docs.ultralytics.com/datasets/detect/coco/) trainiert wurden und 80 vortrainierte Klassen enthalten.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>val<br>50-95 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ---------------------------------------- | --------------------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37,3 | 80,4 | 0,99 | 3,2 | 8,7 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44,9 | 128,4 | 1,20 | 11,2 | 28,6 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50,2 | 234,7 | 1,83 | 25,9 | 78,9 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52,9 | 375,2 | 2,39 | 43,7 | 165,2 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53,9 | 479,1 | 3,53 | 68,2 | 257,8 |
|
||||
|
||||
=== "Objekterkennung (Open Images V7)"
|
||||
|
||||
Siehe [Objekterkennungsdokumentation](https://docs.ultralytics.com/tasks/detect/) für Beispiele zur Verwendung dieser Modelle, die auf [Open Image V7](https://docs.ultralytics.com/datasets/detect/open-images-v7/) trainiert wurden und 600 vortrainierte Klassen enthalten.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>val<br>50-95 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| ----------------------------------------------------------------------------------------- | --------------------- | -------------------- | ---------------------------------------- | --------------------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-oiv7.pt) | 640 | 18,4 | 142,4 | 1,21 | 3,5 | 10,5 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-oiv7.pt) | 640 | 27,7 | 183,1 | 1,40 | 11,4 | 29,7 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-oiv7.pt) | 640 | 33,6 | 408,5 | 2,26 | 26,2 | 80,6 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-oiv7.pt) | 640 | 34,9 | 596,9 | 2,43 | 44,1 | 167,4 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-oiv7.pt) | 640 | 36,3 | 860,6 | 3,56 | 68,7 | 260,6 |
|
||||
|
||||
=== "Segmentierung (COCO)"
|
||||
|
||||
Siehe [Segmentierungsdokumentation](https://docs.ultralytics.com/tasks/segment/) für Beispiele zur Verwendung dieser Modelle, die auf [COCO](https://docs.ultralytics.com/datasets/segment/coco/) trainiert wurden und 80 vortrainierte Klassen enthalten.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| -------------------------------------------------------------------------------------------- | --------------------- | --------------------- | --------------------- | ---------------------------------------- | --------------------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36,7 | 30,5 | 96,1 | 1,21 | 3,4 | 12,6 |
|
||||
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44,6 | 36,8 | 155,7 | 1,47 | 11,8 | 42,6 |
|
||||
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49,9 | 40,8 | 317,0 | 2,18 | 27,3 | 110,2 |
|
||||
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52,3 | 42,6 | 572,4 | 2,79 | 46,0 | 220,5 |
|
||||
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53,4 | 43,4 | 712,1 | 4,02 | 71,8 | 344,1 |
|
||||
|
||||
=== "Klassifikation (ImageNet)"
|
||||
|
||||
Siehe [Klassifikationsdokumentation](https://docs.ultralytics.com/tasks/classify/) für Beispiele zur Verwendung dieser Modelle, die auf [ImageNet](https://docs.ultralytics.com/datasets/classify/imagenet/) trainiert wurden und 1000 vortrainierte Klassen enthalten.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | acc<br><sup>top1 | acc<br><sup>top5 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) bei 640 |
|
||||
| -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ---------------------------------------- | --------------------------------------------- | ------------------ | ------------------------ |
|
||||
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66,6 | 87,0 | 12,9 | 0,31 | 2,7 | 4,3 |
|
||||
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72,3 | 91,1 | 23,4 | 0,35 | 6,4 | 13,5 |
|
||||
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76,4 | 93,2 | 85,4 | 0,62 | 17,0 | 42,7 |
|
||||
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78,0 | 94,1 | 163,0 | 0,87 | 37,5 | 99,7 |
|
||||
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78,4 | 94,3 | 232,0 | 1,01 | 57,4 | 154,8 |
|
||||
|
||||
=== "Pose (COCO)"
|
||||
|
||||
Siehe [Pose Estimation Docs](https://docs.ultralytics.com/tasks/segment/) für Beispiele zur Verwendung dieser Modelle, die auf [COCO](https://docs.ultralytics.com/datasets/pose/coco/) trainiert wurden und 1 vortrainierte Klasse, 'person', enthalten.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>pose<br>50-95 | mAP<sup>pose<br>50 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
| ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ---------------------------------------- | --------------------------------------------- | ------------------ | ----------------- |
|
||||
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50,4 | 80,1 | 131,8 | 1,18 | 3,3 | 9,2 |
|
||||
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60,0 | 86,2 | 233,2 | 1,42 | 11,6 | 30,2 |
|
||||
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65,0 | 88,8 | 456,3 | 2,00 | 26,4 | 81,0 |
|
||||
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67,6 | 90,0 | 784,5 | 2,59 | 44,4 | 168,6 |
|
||||
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69,2 | 90,2 | 1607,1 | 3,73 | 69,4 | 263,2 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71,6 | 91,2 | 4088,7 | 10,04 | 99,1 | 1066,4 |
|
||||
|
||||
## Beispiele zur Verwendung
|
||||
|
||||
Dieses Beispiel liefert einfache Trainings- und Inferenzbeispiele für YOLOv8. Für die vollständige Dokumentation zu diesen und anderen [Modi](../modes/index.md) siehe die Seiten [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) und [Export](../modes/export.md).
|
||||
|
||||
Beachten Sie, dass das folgende Beispiel für YOLOv8 [Detect](../tasks/detect.md) Modelle für die Objekterkennung verwendet. Für zusätzliche unterstützte Aufgaben siehe die Dokumentation zur [Segmentation](../tasks/segment.md), [Classification](../tasks/classify.md) und [Pose](../tasks/pose.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
Vortrainierte PyTorch-`*.pt`-Modelle sowie Konfigurations-`*.yaml`-Dateien können der Klasse `YOLO()` in Python übergeben werden, um eine Modellinstanz zu erstellen:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie ein vortrainiertes YOLOv8n-Modell für COCO
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Zeigen Sie Informationen zum Modell an (optional)
|
||||
model.info()
|
||||
|
||||
# Trainieren Sie das Modell mit dem COCO8-Beispieldatensatz für 100 Epochen
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
|
||||
# Führen Sie eine Inferenz mit dem YOLOv8n-Modell auf dem Bild 'bus.jpg' aus
|
||||
results = model('path/to/bus.jpg')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
CLI-Befehle stehen zur direkten Ausführung der Modelle zur Verfügung:
|
||||
|
||||
```bash
|
||||
# Laden Sie ein vortrainiertes YOLOv8n-Modell für COCO und trainieren Sie es mit dem COCO8-Beispieldatensatz für 100 Epochen
|
||||
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
|
||||
|
||||
# Laden Sie ein vortrainiertes YOLOv8n-Modell für COCO und führen Sie eine Inferenz auf dem Bild 'bus.jpg' aus
|
||||
yolo predict model=yolov8n.pt source=path/to/bus.jpg
|
||||
```
|
||||
|
||||
## Zitate und Danksagungen
|
||||
|
||||
Wenn Sie das YOLOv8-Modell oder eine andere Software aus diesem Repository in Ihrer Arbeit verwenden, zitieren Sie es bitte in folgendem Format:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@software{yolov8_ultralytics,
|
||||
author = {Glenn Jocher and Ayush Chaurasia and Jing Qiu},
|
||||
title = {Ultralytics YOLOv8},
|
||||
version = {8.0.0},
|
||||
year = {2023},
|
||||
url = {https://github.com/ultralytics/ultralytics},
|
||||
orcid = {0000-0001-5950-6979, 0000-0002-7603-6750, 0000-0003-3783-7069},
|
||||
license = {AGPL-3.0}
|
||||
}
|
||||
```
|
||||
|
||||
Bitte beachten Sie, dass dieDOI aussteht und der Zitation hinzugefügt wird, sobald sie verfügbar ist. YOLOv8-Modelle werden unter den Lizenzen [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) und [Enterprise](https://ultralytics.com/license) bereitgestellt.
|
||||
|
|
@ -1,94 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Lernen Sie, wie Sie die Geschwindigkeit und Genauigkeit von YOLOv8 über verschiedene Exportformate hinweg profilieren können; erhalten Sie Einblicke in mAP50-95, Genauigkeit_top5 Kennzahlen und mehr.
|
||||
keywords: Ultralytics, YOLOv8, Benchmarking, Geschwindigkeitsprofilierung, Genauigkeitsprofilierung, mAP50-95, accuracy_top5, ONNX, OpenVINO, TensorRT, YOLO-Exportformate
|
||||
---
|
||||
|
||||
# Modell-Benchmarking mit Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO-Ökosystem und Integrationen">
|
||||
|
||||
## Einführung
|
||||
|
||||
Nachdem Ihr Modell trainiert und validiert wurde, ist der nächste logische Schritt, seine Leistung in verschiedenen realen Szenarien zu bewerten. Der Benchmark-Modus in Ultralytics YOLOv8 dient diesem Zweck, indem er einen robusten Rahmen für die Beurteilung von Geschwindigkeit und Genauigkeit Ihres Modells über eine Reihe von Exportformaten hinweg bietet.
|
||||
|
||||
## Warum ist Benchmarking entscheidend?
|
||||
|
||||
- **Informierte Entscheidungen:** Erhalten Sie Einblicke in die Kompromisse zwischen Geschwindigkeit und Genauigkeit.
|
||||
- **Ressourcenzuweisung:** Verstehen Sie, wie sich verschiedene Exportformate auf unterschiedlicher Hardware verhalten.
|
||||
- **Optimierung:** Erfahren Sie, welches Exportformat die beste Leistung für Ihren spezifischen Anwendungsfall bietet.
|
||||
- **Kosteneffizienz:** Nutzen Sie Hardware-Ressourcen basierend auf den Benchmark-Ergebnissen effizienter.
|
||||
|
||||
### Schlüsselmetriken im Benchmark-Modus
|
||||
|
||||
- **mAP50-95:** Für Objekterkennung, Segmentierung und Posenschätzung.
|
||||
- **accuracy_top5:** Für die Bildklassifizierung.
|
||||
- **Inferenzzeit:** Zeit, die für jedes Bild in Millisekunden benötigt wird.
|
||||
|
||||
### Unterstützte Exportformate
|
||||
|
||||
- **ONNX:** Für optimale CPU-Leistung
|
||||
- **TensorRT:** Für maximale GPU-Effizienz
|
||||
- **OpenVINO:** Für die Optimierung von Intel-Hardware
|
||||
- **CoreML, TensorFlow SavedModel, und mehr:** Für vielfältige Deployment-Anforderungen.
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
* Exportieren Sie in ONNX oder OpenVINO für bis zu 3x CPU-Beschleunigung.
|
||||
* Exportieren Sie in TensorRT für bis zu 5x GPU-Beschleunigung.
|
||||
|
||||
## Anwendungsbeispiele
|
||||
|
||||
Führen Sie YOLOv8n-Benchmarks auf allen unterstützten Exportformaten einschließlich ONNX, TensorRT usw. durch. Siehe den Abschnitt Argumente unten für eine vollständige Liste der Exportargumente.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics.utils.benchmarks import benchmark
|
||||
|
||||
# Benchmark auf GPU
|
||||
benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
|
||||
```
|
||||
|
||||
## Argumente
|
||||
|
||||
Argumente wie `model`, `data`, `imgsz`, `half`, `device` und `verbose` bieten Benutzern die Flexibilität, die Benchmarks auf ihre spezifischen Bedürfnisse abzustimmen und die Leistung verschiedener Exportformate mühelos zu vergleichen.
|
||||
|
||||
| Schlüssel | Wert | Beschreibung |
|
||||
|-----------|---------|--------------------------------------------------------------------------------------|
|
||||
| `model` | `None` | Pfad zur Modelldatei, z. B. yolov8n.pt, yolov8n.yaml |
|
||||
| `data` | `None` | Pfad zur YAML, die das Benchmarking-Dataset referenziert (unter `val`-Kennzeichnung) |
|
||||
| `imgsz` | `640` | Bildgröße als Skalar oder Liste (h, w), z. B. (640, 480) |
|
||||
| `half` | `False` | FP16-Quantisierung |
|
||||
| `int8` | `False` | INT8-Quantisierung |
|
||||
| `device` | `None` | Gerät zum Ausführen, z. B. CUDA device=0 oder device=0,1,2,3 oder device=cpu |
|
||||
| `verbose` | `False` | bei Fehlern nicht fortsetzen (bool), oder Wertebereichsschwelle (float) |
|
||||
|
||||
## Exportformate
|
||||
|
||||
Benchmarks werden automatisch auf allen möglichen Exportformaten unten ausgeführt.
|
||||
|
||||
| Format | `format`-Argument | Modell | Metadaten | Argumente |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|-----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
Vollständige Details zum `export` finden Sie auf der [Export](https://docs.ultralytics.com/modes/export/)-Seite.
|
||||
|
|
@ -1,108 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Schritt-für-Schritt-Anleitung zum Exportieren Ihrer YOLOv8-Modelle in verschiedene Formate wie ONNX, TensorRT, CoreML und mehr für den Einsatz.
|
||||
keywords: YOLO, YOLOv8, Ultralytics, Modell-Export, ONNX, TensorRT, CoreML, TensorFlow SavedModel, OpenVINO, PyTorch, Modell exportieren
|
||||
---
|
||||
|
||||
# Modell-Export mit Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO Ökosystem und Integrationen">
|
||||
|
||||
## Einführung
|
||||
|
||||
Das ultimative Ziel des Trainierens eines Modells besteht darin, es für reale Anwendungen einzusetzen. Der Exportmodus in Ultralytics YOLOv8 bietet eine vielseitige Palette von Optionen für den Export Ihres trainierten Modells in verschiedene Formate, sodass es auf verschiedenen Plattformen und Geräten eingesetzt werden kann. Dieser umfassende Leitfaden soll Sie durch die Nuancen des Modell-Exports führen und zeigen, wie Sie maximale Kompatibilität und Leistung erzielen können.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/WbomGeoOT_k?si=aGmuyooWftA0ue9X"
|
||||
title="YouTube-Video-Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Ansehen:</strong> Wie man ein benutzerdefiniertes trainiertes Ultralytics YOLOv8-Modell exportiert und Live-Inferenz auf der Webcam ausführt.
|
||||
</p>
|
||||
|
||||
## Warum den Exportmodus von YOLOv8 wählen?
|
||||
|
||||
- **Vielseitigkeit:** Export in verschiedene Formate einschließlich ONNX, TensorRT, CoreML und mehr.
|
||||
- **Leistung:** Bis zu 5-fache GPU-Beschleunigung mit TensorRT und 3-fache CPU-Beschleunigung mit ONNX oder OpenVINO.
|
||||
- **Kompatibilität:** Machen Sie Ihr Modell universell einsetzbar in zahlreichen Hardware- und Softwareumgebungen.
|
||||
- **Benutzerfreundlichkeit:** Einfache CLI- und Python-API für schnellen und unkomplizierten Modell-Export.
|
||||
|
||||
### Schlüsselfunktionen des Exportmodus
|
||||
|
||||
Hier sind einige der herausragenden Funktionen:
|
||||
|
||||
- **Ein-Klick-Export:** Einfache Befehle für den Export in verschiedene Formate.
|
||||
- **Batch-Export:** Export von Modellen, die Batch-Inferenz unterstützen.
|
||||
- **Optimiertes Inferenzverhalten:** Exportierte Modelle sind für schnellere Inferenzzeiten optimiert.
|
||||
- **Tutorial-Videos:** Ausführliche Anleitungen und Tutorials für ein reibungsloses Exporterlebnis.
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
* Exportieren Sie nach ONNX oder OpenVINO für bis zu 3-fache CPU-Beschleunigung.
|
||||
* Exportieren Sie nach TensorRT für bis zu 5-fache GPU-Beschleunigung.
|
||||
|
||||
## Nutzungsbeispiele
|
||||
|
||||
Exportieren Sie ein YOLOv8n-Modell in ein anderes Format wie ONNX oder TensorRT. Weitere Informationen zu den Exportargumenten finden Sie im Abschnitt „Argumente“ unten.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden eines Modells
|
||||
model = YOLO('yolov8n.pt') # offizielles Modell laden
|
||||
model = YOLO('path/to/best.pt') # benutzerdefiniertes trainiertes Modell laden
|
||||
|
||||
# Exportieren des Modells
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # offizielles Modell exportieren
|
||||
yolo export model=path/to/best.pt format=onnx # benutzerdefiniertes trainiertes Modell exportieren
|
||||
```
|
||||
|
||||
## Argumente
|
||||
|
||||
Exporteinstellungen für YOLO-Modelle beziehen sich auf verschiedene Konfigurationen und Optionen, die verwendet werden, um das Modell zu speichern oder für den Einsatz in anderen Umgebungen oder Plattformen zu exportieren. Diese Einstellungen können die Leistung, Größe und Kompatibilität des Modells mit verschiedenen Systemen beeinflussen. Zu den gängigen Exporteinstellungen von YOLO gehören das Format der exportierten Modelldatei (z. B. ONNX, TensorFlow SavedModel), das Gerät, auf dem das Modell ausgeführt wird (z. B. CPU, GPU) und das Vorhandensein zusätzlicher Funktionen wie Masken oder mehrere Labels pro Box. Andere Faktoren, die den Exportprozess beeinflussen können, sind die spezifische Aufgabe, für die das Modell verwendet wird, und die Anforderungen oder Einschränkungen der Zielumgebung oder -plattform. Es ist wichtig, diese Einstellungen sorgfältig zu berücksichtigen und zu konfigurieren, um sicherzustellen, dass das exportierte Modell für den beabsichtigten Einsatzzweck optimiert ist und in der Zielumgebung effektiv eingesetzt werden kann.
|
||||
|
||||
| Schlüssel | Wert | Beschreibung |
|
||||
|-------------|-----------------|----------------------------------------------------------|
|
||||
| `format` | `'torchscript'` | Format für den Export |
|
||||
| `imgsz` | `640` | Bildgröße als Skalar oder (h, w)-Liste, z.B. (640, 480) |
|
||||
| `keras` | `False` | Verwendung von Keras für TensorFlow SavedModel-Export |
|
||||
| `optimize` | `False` | TorchScript: Optimierung für mobile Geräte |
|
||||
| `half` | `False` | FP16-Quantisierung |
|
||||
| `int8` | `False` | INT8-Quantisierung |
|
||||
| `dynamic` | `False` | ONNX/TensorRT: dynamische Achsen |
|
||||
| `simplify` | `False` | ONNX/TensorRT: Vereinfachung des Modells |
|
||||
| `opset` | `None` | ONNX: Opset-Version (optional, Standardwert ist neueste) |
|
||||
| `workspace` | `4` | TensorRT: Arbeitsbereichgröße (GB) |
|
||||
| `nms` | `False` | CoreML: Hinzufügen von NMS |
|
||||
|
||||
## Exportformate
|
||||
|
||||
Verfügbare YOLOv8-Exportformate finden Sie in der Tabelle unten. Sie können in jedes Format exportieren, indem Sie das `format`-Argument verwenden, z. B. `format='onnx'` oder `format='engine'`.
|
||||
|
||||
| Format | `format`-Argument | Modell | Metadaten | Argumente |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|-----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
|
@ -1,74 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Vom Training bis zum Tracking - Nutzen Sie YOLOv8 von Ultralytics optimal. Erhalten Sie Einblicke und Beispiele für jeden unterstützten Modus, einschließlich Validierung, Export und Benchmarking.
|
||||
keywords: Ultralytics, YOLOv8, Maschinelles Lernen, Objekterkennung, Training, Validierung, Vorhersage, Export, Tracking, Benchmarking
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv8 Modi
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO-Ökosystem und Integrationen">
|
||||
|
||||
## Einführung
|
||||
|
||||
Ultralytics YOLOv8 ist nicht nur ein weiteres Objekterkennungsmodell; es ist ein vielseitiges Framework, das den gesamten Lebenszyklus von Machine-Learning-Modellen abdeckt - von der Dateneingabe und dem Modelltraining über die Validierung und Bereitstellung bis hin zum Tracking in der realen Welt. Jeder Modus dient einem bestimmten Zweck und ist darauf ausgelegt, Ihnen die Flexibilität und Effizienz zu bieten, die für verschiedene Aufgaben und Anwendungsfälle erforderlich ist.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/j8uQc0qB91s?si=dhnGKgqvs7nPgeaM"
|
||||
title="YouTube-Videoplayer" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Anschauen:</strong> Ultralytics Modi Tutorial: Trainieren, Validieren, Vorhersagen, Exportieren & Benchmarking.
|
||||
</p>
|
||||
|
||||
### Modi im Überblick
|
||||
|
||||
Das Verständnis der verschiedenen **Modi**, die Ultralytics YOLOv8 unterstützt, ist entscheidend, um das Beste aus Ihren Modellen herauszuholen:
|
||||
|
||||
- **Train**-Modus: Verfeinern Sie Ihr Modell mit angepassten oder vorgeladenen Datensätzen.
|
||||
- **Val**-Modus: Eine Nachtrainingsprüfung zur Validierung der Modellleistung.
|
||||
- **Predict**-Modus: Entfesseln Sie die Vorhersagekraft Ihres Modells mit realen Daten.
|
||||
- **Export**-Modus: Machen Sie Ihr Modell in verschiedenen Formaten einsatzbereit.
|
||||
- **Track**-Modus: Erweitern Sie Ihr Objekterkennungsmodell um Echtzeit-Tracking-Anwendungen.
|
||||
- **Benchmark**-Modus: Analysieren Sie die Geschwindigkeit und Genauigkeit Ihres Modells in verschiedenen Einsatzumgebungen.
|
||||
|
||||
Dieser umfassende Leitfaden soll Ihnen einen Überblick und praktische Einblicke in jeden Modus geben, um Ihnen zu helfen, das volle Potenzial von YOLOv8 zu nutzen.
|
||||
|
||||
## [Trainieren](train.md)
|
||||
|
||||
Der Trainingsmodus wird verwendet, um ein YOLOv8-Modell mit einem angepassten Datensatz zu trainieren. In diesem Modus wird das Modell mit dem angegebenen Datensatz und den Hyperparametern trainiert. Der Trainingsprozess beinhaltet die Optimierung der Modellparameter, damit es die Klassen und Standorte von Objekten in einem Bild genau vorhersagen kann.
|
||||
|
||||
[Trainingsbeispiele](train.md){ .md-button }
|
||||
|
||||
## [Validieren](val.md)
|
||||
|
||||
Der Validierungsmodus wird genutzt, um ein YOLOv8-Modell nach dem Training zu bewerten. In diesem Modus wird das Modell auf einem Validierungsset getestet, um seine Genauigkeit und Generalisierungsleistung zu messen. Dieser Modus kann verwendet werden, um die Hyperparameter des Modells für eine bessere Leistung zu optimieren.
|
||||
|
||||
[Validierungsbeispiele](val.md){ .md-button }
|
||||
|
||||
## [Vorhersagen](predict.md)
|
||||
|
||||
Der Vorhersagemodus wird verwendet, um mit einem trainierten YOLOv8-Modell Vorhersagen für neue Bilder oder Videos zu treffen. In diesem Modus wird das Modell aus einer Checkpoint-Datei geladen, und der Benutzer kann Bilder oder Videos zur Inferenz bereitstellen. Das Modell sagt die Klassen und Standorte von Objekten in den Eingabebildern oder -videos voraus.
|
||||
|
||||
[Vorhersagebeispiele](predict.md){ .md-button }
|
||||
|
||||
## [Exportieren](export.md)
|
||||
|
||||
Der Exportmodus wird verwendet, um ein YOLOv8-Modell in ein Format zu exportieren, das für die Bereitstellung verwendet werden kann. In diesem Modus wird das Modell in ein Format konvertiert, das von anderen Softwareanwendungen oder Hardwaregeräten verwendet werden kann. Dieser Modus ist nützlich, wenn das Modell in Produktionsumgebungen eingesetzt wird.
|
||||
|
||||
[Exportbeispiele](export.md){ .md-button }
|
||||
|
||||
## [Verfolgen](track.md)
|
||||
|
||||
Der Trackingmodus wird zur Echtzeitverfolgung von Objekten mit einem YOLOv8-Modell verwendet. In diesem Modus wird das Modell aus einer Checkpoint-Datei geladen, und der Benutzer kann einen Live-Videostream für das Echtzeitobjekttracking bereitstellen. Dieser Modus ist nützlich für Anwendungen wie Überwachungssysteme oder selbstfahrende Autos.
|
||||
|
||||
[Trackingbeispiele](track.md){ .md-button }
|
||||
|
||||
## [Benchmarking](benchmark.md)
|
||||
|
||||
Der Benchmark-Modus wird verwendet, um die Geschwindigkeit und Genauigkeit verschiedener Exportformate für YOLOv8 zu profilieren. Die Benchmarks liefern Informationen über die Größe des exportierten Formats, seine `mAP50-95`-Metriken (für Objekterkennung, Segmentierung und Pose)
|
||||
oder `accuracy_top5`-Metriken (für Klassifizierung) und die Inferenzzeit in Millisekunden pro Bild für verschiedene Exportformate wie ONNX, OpenVINO, TensorRT und andere. Diese Informationen können den Benutzern dabei helfen, das optimale Exportformat für ihren spezifischen Anwendungsfall basierend auf ihren Anforderungen an Geschwindigkeit und Genauigkeit auszuwählen.
|
||||
|
||||
[Benchmarkbeispiele](benchmark.md){ .md-button }
|
||||
|
|
@ -1,226 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erkunden Sie, wie der YOLOv8-Prognosemodus für verschiedene Aufgaben verwendet werden kann. Erfahren Sie mehr über verschiedene Inferenzquellen wie Bilder, Videos und Datenformate.
|
||||
keywords: Ultralytics, YOLOv8, Vorhersagemodus, Inferenzquellen, Vorhersageaufgaben, Streaming-Modus, Bildverarbeitung, Videoverarbeitung, maschinelles Lernen, KI
|
||||
---
|
||||
|
||||
# Modellvorhersage mit Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO Ökosystem und Integrationen">
|
||||
|
||||
## Einführung
|
||||
|
||||
Im Bereich des maschinellen Lernens und der Computer Vision wird der Prozess des Verstehens visueller Daten als 'Inferenz' oder 'Vorhersage' bezeichnet. Ultralytics YOLOv8 bietet eine leistungsstarke Funktion, die als **Prognosemodus** bekannt ist und für eine hochleistungsfähige, echtzeitfähige Inferenz auf einer breiten Palette von Datenquellen zugeschnitten ist.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/QtsI0TnwDZs?si=ljesw75cMO2Eas14"
|
||||
title="YouTube Video Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Anschauen:</strong> Wie man die Ausgaben vom Ultralytics YOLOv8 Modell für individuelle Projekte extrahiert.
|
||||
</p>
|
||||
|
||||
## Anwendungen in der realen Welt
|
||||
|
||||
| Herstellung | Sport | Sicherheit |
|
||||
|:---------------------------------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  | 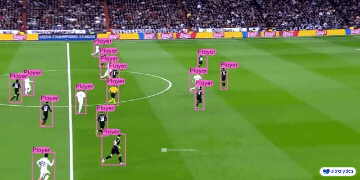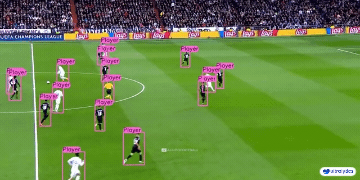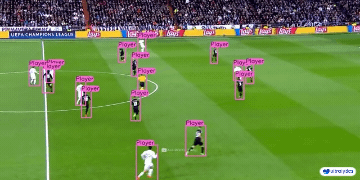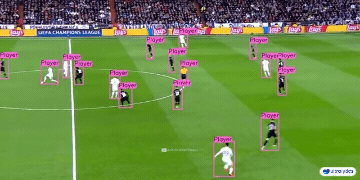 |  |
|
||||
| Erkennung von Fahrzeugersatzteilen | Erkennung von Fußballspielern | Erkennung von stürzenden Personen |
|
||||
|
||||
## Warum Ultralytics YOLO für Inferenz nutzen?
|
||||
|
||||
Hier sind Gründe, warum Sie den Prognosemodus von YOLOv8 für Ihre verschiedenen Inferenzanforderungen in Betracht ziehen sollten:
|
||||
|
||||
- **Vielseitigkeit:** Fähig, Inferenzen auf Bilder, Videos und sogar Live-Streams zu machen.
|
||||
- **Leistung:** Entwickelt für Echtzeit-Hochgeschwindigkeitsverarbeitung ohne Genauigkeitsverlust.
|
||||
- **Einfache Bedienung:** Intuitive Python- und CLI-Schnittstellen für schnelle Einsatzbereitschaft und Tests.
|
||||
- **Hohe Anpassbarkeit:** Verschiedene Einstellungen und Parameter, um das Verhalten der Modellinferenz entsprechend Ihren spezifischen Anforderungen zu optimieren.
|
||||
|
||||
### Schlüsselfunktionen des Prognosemodus
|
||||
|
||||
Der Prognosemodus von YOLOv8 ist robust und vielseitig konzipiert und verfügt über:
|
||||
|
||||
- **Kompatibilität mit mehreren Datenquellen:** Ganz gleich, ob Ihre Daten in Form von Einzelbildern, einer Bildersammlung, Videodateien oder Echtzeit-Videostreams vorliegen, der Prognosemodus deckt alles ab.
|
||||
- **Streaming-Modus:** Nutzen Sie die Streaming-Funktion, um einen speichereffizienten Generator von `Results`-Objekten zu erzeugen. Aktivieren Sie dies, indem Sie `stream=True` in der Aufrufmethode des Predictors einstellen.
|
||||
- **Batchverarbeitung:** Die Möglichkeit, mehrere Bilder oder Videoframes in einem einzigen Batch zu verarbeiten, wodurch die Inferenzzeit weiter verkürzt wird.
|
||||
- **Integrationsfreundlich:** Dank der flexiblen API leicht in bestehende Datenpipelines und andere Softwarekomponenten zu integrieren.
|
||||
|
||||
Ultralytics YOLO-Modelle geben entweder eine Python-Liste von `Results`-Objekten zurück, oder einen speichereffizienten Python-Generator von `Results`-Objekten, wenn `stream=True` beim Inferenzvorgang an das Modell übergeben wird:
|
||||
|
||||
!!! Example "Predict"
|
||||
|
||||
=== "Gibt eine Liste mit `stream=False` zurück"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein Modell laden
|
||||
model = YOLO('yolov8n.pt') # vortrainiertes YOLOv8n Modell
|
||||
|
||||
# Batch-Inferenz auf einer Liste von Bildern ausführen
|
||||
results = model(['im1.jpg', 'im2.jpg']) # gibt eine Liste von Results-Objekten zurück
|
||||
|
||||
# Ergebnisliste verarbeiten
|
||||
for result in results:
|
||||
boxes = result.boxes # Boxes-Objekt für Bbox-Ausgaben
|
||||
masks = result.masks # Masks-Objekt für Segmentierungsmasken-Ausgaben
|
||||
keypoints = result.keypoints # Keypoints-Objekt für Pose-Ausgaben
|
||||
probs = result.probs # Probs-Objekt für Klassifizierungs-Ausgaben
|
||||
```
|
||||
|
||||
=== "Gibt einen Generator mit `stream=True` zurück"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein Modell laden
|
||||
model = YOLO('yolov8n.pt') # vortrainiertes YOLOv8n Modell
|
||||
|
||||
# Batch-Inferenz auf einer Liste von Bildern ausführen
|
||||
results = model(['im1.jpg', 'im2.jpg'], stream=True) # gibt einen Generator von Results-Objekten zurück
|
||||
|
||||
# Generator von Ergebnissen verarbeiten
|
||||
for result in results:
|
||||
boxes = result.boxes # Boxes-Objekt für Bbox-Ausgaben
|
||||
masks = result.masks # Masks-Objekt für Segmentierungsmasken-Ausgaben
|
||||
keypoints = result.keypoints # Keypoints-Objekt für Pose-Ausgaben
|
||||
probs = result.probs # Probs-Objekt für Klassifizierungs-Ausgaben
|
||||
```
|
||||
|
||||
## Inferenzquellen
|
||||
|
||||
YOLOv8 kann verschiedene Arten von Eingabequellen für die Inferenz verarbeiten, wie in der folgenden Tabelle gezeigt. Die Quellen umfassen statische Bilder, Videostreams und verschiedene Datenformate. Die Tabelle gibt ebenfalls an, ob jede Quelle im Streaming-Modus mit dem Argument `stream=True` ✅ verwendet werden kann. Der Streaming-Modus ist vorteilhaft für die Verarbeitung von Videos oder Live-Streams, da er einen Generator von Ergebnissen statt das Laden aller Frames in den Speicher erzeugt.
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
Verwenden Sie `stream=True` für die Verarbeitung langer Videos oder großer Datensätze, um den Speicher effizient zu verwalten. Bei `stream=False` werden die Ergebnisse für alle Frames oder Datenpunkte im Speicher gehalten, was bei großen Eingaben schnell zu Speicherüberläufen führen kann. Im Gegensatz dazu verwendet `stream=True` einen Generator, der nur die Ergebnisse des aktuellen Frames oder Datenpunkts im Speicher behält, was den Speicherverbrauch erheblich reduziert und Speicherüberlaufprobleme verhindert.
|
||||
|
||||
| Quelle | Argument | Typ | Hinweise |
|
||||
|--------------------|--------------------------------------------|-------------------|------------------------------------------------------------------------------------------------|
|
||||
| Bild | `'image.jpg'` | `str` oder `Path` | Einzelbilddatei. |
|
||||
| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | URL zu einem Bild. |
|
||||
| Bildschirmaufnahme | `'screen'` | `str` | Eine Bildschirmaufnahme erstellen. |
|
||||
| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC-Format mit RGB-Kanälen. |
|
||||
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | HWC-Format mit BGR-Kanälen `uint8 (0-255)`. |
|
||||
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC-Format mit BGR-Kanälen `uint8 (0-255)`. |
|
||||
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW-Format mit RGB-Kanälen `float32 (0.0-1.0)`. |
|
||||
| CSV | `'sources.csv'` | `str` oder `Path` | CSV-Datei mit Pfaden zu Bildern, Videos oder Verzeichnissen. |
|
||||
| video ✅ | `'video.mp4'` | `str` oder `Path` | Videodatei in Formaten wie MP4, AVI, usw. |
|
||||
| Verzeichnis ✅ | `'path/'` | `str` oder `Path` | Pfad zu einem Verzeichnis mit Bildern oder Videos. |
|
||||
| glob ✅ | `'path/*.jpg'` | `str` | Glob-Muster, um mehrere Dateien zu finden. Verwenden Sie das `*` Zeichen als Platzhalter. |
|
||||
| YouTube ✅ | `'https://youtu.be/LNwODJXcvt4'` | `str` | URL zu einem YouTube-Video. |
|
||||
| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | URL für Streaming-Protokolle wie RTSP, RTMP, TCP oder eine IP-Adresse. |
|
||||
| Multi-Stream ✅ | `'list.streams'` | `str` oder `Path` | `*.streams` Textdatei mit einer Stream-URL pro Zeile, z.B. 8 Streams laufen bei Batch-Größe 8. |
|
||||
|
||||
Untenstehend finden Sie Codebeispiele für die Verwendung jedes Quelltyps:
|
||||
|
||||
!!! Example "Vorhersagequellen"
|
||||
|
||||
=== "Bild"
|
||||
Führen Sie die Inferenz auf einer Bilddatei aus.
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Pfad zur Bilddatei definieren
|
||||
quell = 'Pfad/zum/Bild.jpg'
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
```
|
||||
|
||||
=== "Bildschirmaufnahme"
|
||||
Führen Sie die Inferenz auf dem aktuellen Bildschirminhalt als Screenshot aus.
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Aktuellen Screenshot als Quelle definieren
|
||||
quell = 'Bildschirm'
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
```
|
||||
|
||||
=== "URL"
|
||||
Führen Sie die Inferenz auf einem Bild oder Video aus, das über eine URL remote gehostet wird.
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Remote-Bild- oder Video-URL definieren
|
||||
quell = 'https://ultralytics.com/images/bus.jpg'
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
```
|
||||
|
||||
=== "PIL"
|
||||
Führen Sie die Inferenz auf einem Bild aus, das mit der Python Imaging Library (PIL) geöffnet wurde.
|
||||
```python
|
||||
from PIL import Image
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Ein Bild mit PIL öffnen
|
||||
quell = Image.open('Pfad/zum/Bild.jpg')
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
```
|
||||
|
||||
=== "OpenCV"
|
||||
Führen Sie die Inferenz auf einem Bild aus, das mit OpenCV gelesen wurde.
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Ein Bild mit OpenCV lesen
|
||||
quell = cv2.imread('Pfad/zum/Bild.jpg')
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
```
|
||||
|
||||
=== "numpy"
|
||||
Führen Sie die Inferenz auf einem Bild aus, das als numpy-Array dargestellt wird.
|
||||
```python
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Ein zufälliges numpy-Array der HWC-Form (640, 640, 3) mit Werten im Bereich [0, 255] und Typ uint8 erstellen
|
||||
quell = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
```
|
||||
|
||||
=== "torch"
|
||||
Führen Sie die Inferenz auf einem Bild aus, das als PyTorch-Tensor dargestellt wird.
|
||||
```python
|
||||
import torch
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein vortrainiertes YOLOv8n Modell laden
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Ein zufälliger torch-Tensor der BCHW-Form (1, 3, 640, 640) mit Werten im Bereich [0, 1] und Typ float32 erstellen
|
||||
quell = torch.rand(1, 3, 640, 640, dtype=torch.float32)
|
||||
|
||||
# Inferenz auf der Quelle ausführen
|
||||
ergebnisse = model(quell) # Liste von Results-Objekten
|
||||
|
|
@ -1,200 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie, wie Sie Ultralytics YOLO für Objektverfolgung in Videostreams verwenden. Anleitungen zum Einsatz verschiedener Tracker und zur Anpassung von Tracker-Konfigurationen.
|
||||
keywords: Ultralytics, YOLO, Objektverfolgung, Videostreams, BoT-SORT, ByteTrack, Python-Anleitung, CLI-Anleitung
|
||||
---
|
||||
|
||||
# Multi-Objektverfolgung mit Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418637-1d6250fd-1515-4c10-a844-a32818ae6d46.png" alt="Beispiele für Multi-Objektverfolgung">
|
||||
|
||||
Objektverfolgung im Bereich der Videoanalytik ist eine essentielle Aufgabe, die nicht nur den Standort und die Klasse von Objekten innerhalb des Frames identifiziert, sondern auch eine eindeutige ID für jedes erkannte Objekt, während das Video fortschreitet, erhält. Die Anwendungsmöglichkeiten sind grenzenlos – von Überwachung und Sicherheit bis hin zur Echtzeitsportanalytik.
|
||||
|
||||
## Warum Ultralytics YOLO für Objektverfolgung wählen?
|
||||
|
||||
Die Ausgabe von Ultralytics Trackern ist konsistent mit der standardmäßigen Objekterkennung, bietet aber zusätzlich Objekt-IDs. Dies erleichtert das Verfolgen von Objekten in Videostreams und das Durchführen nachfolgender Analysen. Hier sind einige Gründe, warum Sie Ultralytics YOLO für Ihre Objektverfolgungsaufgaben in Betracht ziehen sollten:
|
||||
|
||||
- **Effizienz:** Verarbeitung von Videostreams in Echtzeit ohne Einbußen bei der Genauigkeit.
|
||||
- **Flexibilität:** Unterstützt mehrere Tracking-Algorithmen und -Konfigurationen.
|
||||
- **Benutzerfreundlichkeit:** Einfache Python-API und CLI-Optionen für schnelle Integration und Bereitstellung.
|
||||
- **Anpassbarkeit:** Einfache Verwendung mit individuell trainierten YOLO-Modellen, ermöglicht Integration in branchenspezifische Anwendungen.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/hHyHmOtmEgs?si=VNZtXmm45Nb9s-N-"
|
||||
title="YouTube-Videoplayer" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Ansehen:</strong> Objekterkennung und -verfolgung mit Ultralytics YOLOv8.
|
||||
</p>
|
||||
|
||||
## Anwendungen in der realen Welt
|
||||
|
||||
| Transportwesen | Einzelhandel | Aquakultur |
|
||||
|:------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |  |
|
||||
| Fahrzeugverfolgung | Personenverfolgung | Fischverfolgung |
|
||||
|
||||
## Eigenschaften auf einen Blick
|
||||
|
||||
Ultralytics YOLO erweitert seine Objekterkennungsfunktionen, um eine robuste und vielseitige Objektverfolgung bereitzustellen:
|
||||
|
||||
- **Echtzeitverfolgung:** Nahtloses Verfolgen von Objekten in Videos mit hoher Bildfrequenz.
|
||||
- **Unterstützung mehrerer Tracker:** Auswahl aus einer Vielzahl etablierter Tracking-Algorithmen.
|
||||
- **Anpassbare Tracker-Konfigurationen:** Anpassen des Tracking-Algorithmus an spezifische Anforderungen durch Einstellung verschiedener Parameter.
|
||||
|
||||
## Verfügbare Tracker
|
||||
|
||||
Ultralytics YOLO unterstützt die folgenden Tracking-Algorithmen. Sie können aktiviert werden, indem Sie die entsprechende YAML-Konfigurationsdatei wie `tracker=tracker_type.yaml` übergeben:
|
||||
|
||||
* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - Verwenden Sie `botsort.yaml`, um diesen Tracker zu aktivieren.
|
||||
* [ByteTrack](https://github.com/ifzhang/ByteTrack) - Verwenden Sie `bytetrack.yaml`, um diesen Tracker zu aktivieren.
|
||||
|
||||
Der Standardtracker ist BoT-SORT.
|
||||
|
||||
## Verfolgung
|
||||
|
||||
Um den Tracker auf Videostreams auszuführen, verwenden Sie ein trainiertes Erkennungs-, Segmentierungs- oder Posierungsmodell wie YOLOv8n, YOLOv8n-seg und YOLOv8n-pose.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie ein offizielles oder individuelles Modell
|
||||
model = YOLO('yolov8n.pt') # Laden Sie ein offizielles Erkennungsmodell
|
||||
model = YOLO('yolov8n-seg.pt') # Laden Sie ein offizielles Segmentierungsmodell
|
||||
model = YOLO('yolov8n-pose.pt') # Laden Sie ein offizielles Posierungsmodell
|
||||
model = YOLO('path/to/best.pt') # Laden Sie ein individuell trainiertes Modell
|
||||
|
||||
# Führen Sie die Verfolgung mit dem Modell durch
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True) # Verfolgung mit Standardtracker
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # Verfolgung mit ByteTrack-Tracker
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Führen Sie die Verfolgung mit verschiedenen Modellen über die Befehlszeilenschnittstelle durch
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" # Offizielles Erkennungsmodell
|
||||
yolo track model=yolov8n-seg.pt source="https://youtu.be/LNwODJXcvt4" # Offizielles Segmentierungsmodell
|
||||
yolo track model=yolov8n-pose.pt source="https://youtu.be/LNwODJXcvt4" # Offizielles Posierungsmodell
|
||||
yolo track model=path/to/best.pt source="https://youtu.be/LNwODJXcvt4" # Individuell trainiertes Modell
|
||||
|
||||
# Verfolgung mit ByteTrack-Tracker
|
||||
yolo track model=path/to/best.pt tracker="bytetrack.yaml"
|
||||
```
|
||||
|
||||
Wie in der obigen Nutzung zu sehen ist, ist die Verfolgung für alle Detect-, Segment- und Pose-Modelle verfügbar, die auf Videos oder Streaming-Quellen ausgeführt werden.
|
||||
|
||||
## Konfiguration
|
||||
|
||||
### Tracking-Argumente
|
||||
|
||||
Die Tracking-Konfiguration teilt Eigenschaften mit dem Predict-Modus, wie `conf`, `iou` und `show`. Für weitere Konfigurationen siehe die Seite des [Predict](https://docs.ultralytics.com/modes/predict/)-Modells.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Konfigurieren Sie die Tracking-Parameter und führen Sie den Tracker aus
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Konfigurieren Sie die Tracking-Parameter und führen Sie den Tracker über die Befehlszeilenschnittstelle aus
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
|
||||
```
|
||||
|
||||
### Tracker-Auswahl
|
||||
|
||||
Ultralytics ermöglicht es Ihnen auch, eine modifizierte Tracker-Konfigurationsdatei zu verwenden. Hierfür kopieren Sie einfach eine Tracker-Konfigurationsdatei (zum Beispiel `custom_tracker.yaml`) von [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) und ändern jede Konfiguration (außer dem `tracker_type`), wie es Ihren Bedürfnissen entspricht.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie das Modell und führen Sie den Tracker mit einer individuellen Konfigurationsdatei aus
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker='custom_tracker.yaml')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Laden Sie das Modell und führen Sie den Tracker mit einer individuellen Konfigurationsdatei über die Befehlszeilenschnittstelle aus
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
|
||||
```
|
||||
|
||||
Für eine umfassende Liste der Tracking-Argumente siehe die Seite [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers).
|
||||
|
||||
## Python-Beispiele
|
||||
|
||||
### Persistierende Tracks-Schleife
|
||||
|
||||
Hier ist ein Python-Skript, das OpenCV (`cv2`) und YOLOv8 verwendet, um Objektverfolgung in Videoframes durchzuführen. Dieses Skript setzt voraus, dass Sie die notwendigen Pakete (`opencv-python` und `ultralytics`) bereits installiert haben. Das Argument `persist=True` teilt dem Tracker mit, dass das aktuelle Bild oder Frame das nächste in einer Sequenz ist und Tracks aus dem vorherigen Bild im aktuellen Bild erwartet werden.
|
||||
|
||||
!!! Example "Streaming-For-Schleife mit Tracking"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie das YOLOv8-Modell
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Öffnen Sie die Videodatei
|
||||
video_path = "path/to/video.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# Schleife durch die Videoframes
|
||||
while cap.isOpened():
|
||||
# Einen Frame aus dem Video lesen
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# Führen Sie YOLOv8-Tracking im Frame aus, wobei Tracks zwischen Frames beibehalten werden
|
||||
results = model.track(frame, persist=True)
|
||||
|
||||
# Visualisieren Sie die Ergebnisse im Frame
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# Zeigen Sie den kommentierten Frame an
|
||||
cv2.imshow("YOLOv8-Tracking", annotated_frame)
|
||||
|
||||
# Beenden Sie die Schleife, wenn 'q' gedrückt wird
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# Beenden Sie die Schleife, wenn das Ende des Videos erreicht ist
|
||||
break
|
||||
|
||||
# Geben Sie das Videoaufnahmeobjekt frei und schließen Sie das Anzeigefenster
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
Bitte beachten Sie die Änderung von `model(frame)` zu `model.track(frame)`, welche die Objektverfolgung anstelle der einfachen Erkennung aktiviert. Dieses modifizierte Skript führt den Tracker auf jedem Frame des Videos aus, visualisiert die Ergebnisse und zeigt sie in einem Fenster an. Die Schleife kann durch Drücken von 'q' beendet werden.
|
||||
|
||||
## Neue Tracker beisteuern
|
||||
|
||||
Sind Sie versiert in der Multi-Objektverfolgung und haben erfolgreich einen Tracking-Algorithmus mit Ultralytics YOLO implementiert oder angepasst? Wir laden Sie ein, zu unserem Trackers-Bereich in [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) beizutragen! Ihre realen Anwendungen und Lösungen könnten für Benutzer, die an Tracking-Aufgaben arbeiten, von unschätzbarem Wert sein.
|
||||
|
||||
Indem Sie zu diesem Bereich beitragen, helfen Sie, das Spektrum verfügbarer Tracking-Lösungen innerhalb des Ultralytics YOLO-Frameworks zu erweitern und fügen eine weitere Funktionsschicht für die Gemeinschaft hinzu.
|
||||
|
||||
Um Ihren Beitrag einzuleiten, sehen Sie bitte in unserem [Contributing Guide](https://docs.ultralytics.com/help/contributing) für umfassende Anweisungen zur Einreichung eines Pull Requests (PR) 🛠️. Wir sind gespannt darauf, was Sie beitragen!
|
||||
|
||||
Gemeinsam verbessern wir die Tracking-Fähigkeiten des Ultralytics YOLO-Ökosystems 🙏!
|
||||
|
|
@ -1,206 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Schritt-für-Schritt-Leitfaden zum Trainieren von YOLOv8-Modellen mit Ultralytics YOLO, einschließlich Beispielen für Single-GPU- und Multi-GPU-Training
|
||||
keywords: Ultralytics, YOLOv8, YOLO, Objekterkennung, Trainingsmodus, benutzerdefinierter Datensatz, GPU-Training, Multi-GPU, Hyperparameter, CLI-Beispiele, Python-Beispiele
|
||||
---
|
||||
|
||||
# Modelltraining mit Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO Ökosystem und Integrationen">
|
||||
|
||||
## Einleitung
|
||||
|
||||
Das Training eines Deep-Learning-Modells beinhaltet das Einspeisen von Daten und die Anpassung seiner Parameter, so dass es genaue Vorhersagen treffen kann. Der Trainingsmodus in Ultralytics YOLOv8 ist für das effektive und effiziente Training von Objekterkennungsmodellen konzipiert und nutzt dabei die Fähigkeiten moderner Hardware voll aus. Dieser Leitfaden zielt darauf ab, alle Details zu vermitteln, die Sie benötigen, um mit dem Training Ihrer eigenen Modelle unter Verwendung des robusten Funktionssatzes von YOLOv8 zu beginnen.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/LNwODJXcvt4?si=7n1UvGRLSd9p5wKs"
|
||||
title="YouTube-Videoplayer" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Video anschauen:</strong> Wie man ein YOLOv8-Modell auf Ihrem benutzerdefinierten Datensatz in Google Colab trainiert.
|
||||
</p>
|
||||
|
||||
## Warum Ultralytics YOLO für das Training wählen?
|
||||
|
||||
Hier einige überzeugende Gründe, sich für den Trainingsmodus von YOLOv8 zu entscheiden:
|
||||
|
||||
- **Effizienz:** Machen Sie das Beste aus Ihrer Hardware, egal ob Sie auf einem Single-GPU-Setup sind oder über mehrere GPUs skalieren.
|
||||
- **Vielseitigkeit:** Training auf benutzerdefinierten Datensätzen zusätzlich zu den bereits verfügbaren Datensätzen wie COCO, VOC und ImageNet.
|
||||
- **Benutzerfreundlich:** Einfache, aber leistungsstarke CLI- und Python-Schnittstellen für ein unkompliziertes Trainingserlebnis.
|
||||
- **Flexibilität der Hyperparameter:** Eine breite Palette von anpassbaren Hyperparametern, um die Modellleistung zu optimieren.
|
||||
|
||||
### Schlüsselfunktionen des Trainingsmodus
|
||||
|
||||
Die folgenden sind einige bemerkenswerte Funktionen von YOLOv8s Trainingsmodus:
|
||||
|
||||
- **Automatischer Datensatz-Download:** Standarddatensätze wie COCO, VOC und ImageNet werden bei der ersten Verwendung automatisch heruntergeladen.
|
||||
- **Multi-GPU-Unterstützung:** Skalieren Sie Ihr Training nahtlos über mehrere GPUs, um den Prozess zu beschleunigen.
|
||||
- **Konfiguration der Hyperparameter:** Die Möglichkeit zur Modifikation der Hyperparameter über YAML-Konfigurationsdateien oder CLI-Argumente.
|
||||
- **Visualisierung und Überwachung:** Echtzeit-Tracking von Trainingsmetriken und Visualisierung des Lernprozesses für bessere Einsichten.
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
* YOLOv8-Datensätze wie COCO, VOC, ImageNet und viele andere werden automatisch bei der ersten Verwendung heruntergeladen, d.h. `yolo train data=coco.yaml`
|
||||
|
||||
## Nutzungsbeispiele
|
||||
|
||||
Trainieren Sie YOLOv8n auf dem COCO128-Datensatz für 100 Epochen bei einer Bildgröße von 640. Das Trainingsgerät kann mit dem Argument `device` spezifiziert werden. Wenn kein Argument übergeben wird, wird GPU `device=0` verwendet, wenn verfügbar, sonst wird `device=cpu` verwendet. Siehe den Abschnitt Argumente unten für eine vollständige Liste der Trainingsargumente.
|
||||
|
||||
!!! Example "Beispiel für Single-GPU- und CPU-Training"
|
||||
|
||||
Das Gerät wird automatisch ermittelt. Wenn eine GPU verfügbar ist, dann wird diese verwendet, sonst beginnt das Training auf der CPU.
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie ein Modell
|
||||
model = YOLO('yolov8n.yaml') # bauen Sie ein neues Modell aus YAML
|
||||
model = YOLO('yolov8n.pt') # laden Sie ein vortrainiertes Modell (empfohlen für das Training)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # bauen Sie aus YAML und übertragen Sie Gewichte
|
||||
|
||||
# Trainieren Sie das Modell
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Bauen Sie ein neues Modell aus YAML und beginnen Sie das Training von Grund auf
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# Beginnen Sie das Training von einem vortrainierten *.pt Modell
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# Bauen Sie ein neues Modell aus YAML, übertragen Sie vortrainierte Gewichte darauf und beginnen Sie das Training
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### Multi-GPU-Training
|
||||
|
||||
Multi-GPU-Training ermöglicht eine effizientere Nutzung von verfügbaren Hardware-Ressourcen, indem die Trainingslast über mehrere GPUs verteilt wird. Diese Funktion ist über sowohl die Python-API als auch die Befehlszeilenschnittstelle verfügbar. Um das Multi-GPU-Training zu aktivieren, geben Sie die GPU-Geräte-IDs an, die Sie verwenden möchten.
|
||||
|
||||
!!! Example "Beispiel für Multi-GPU-Training"
|
||||
|
||||
Um mit 2 GPUs zu trainieren, verwenden Sie die folgenden Befehle für CUDA-Geräte 0 und 1. Erweitern Sie dies bei Bedarf auf zusätzliche GPUs.
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie ein Modell
|
||||
model = YOLO('yolov8n.pt') # laden Sie ein vortrainiertes Modell (empfohlen für das Training)
|
||||
|
||||
# Trainieren Sie das Modell mit 2 GPUs
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Beginnen Sie das Training von einem vortrainierten *.pt Modell unter Verwendung der GPUs 0 und 1
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
|
||||
```
|
||||
|
||||
### Apple M1- und M2-MPS-Training
|
||||
|
||||
Mit der Unterstützung für Apple M1- und M2-Chips, die in den Ultralytics YOLO-Modellen integriert ist, ist es jetzt möglich, Ihre Modelle auf Geräten zu trainieren, die das leistungsstarke Metal Performance Shaders (MPS)-Framework nutzen. MPS bietet eine leistungsstarke Methode zur Ausführung von Berechnungs- und Bildverarbeitungsaufgaben auf Apples benutzerdefinierten Siliziumchips.
|
||||
|
||||
Um das Training auf Apple M1- und M2-Chips zu ermöglichen, sollten Sie 'mps' als Ihr Gerät angeben, wenn Sie den Trainingsprozess starten. Unten ist ein Beispiel, wie Sie dies in Python und über die Befehlszeile tun könnten:
|
||||
|
||||
!!! Example "MPS-Training Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Laden Sie ein Modell
|
||||
model = YOLO('yolov8n.pt') # laden Sie ein vortrainiertes Modell (empfohlen für das Training)
|
||||
|
||||
# Trainieren Sie das Modell mit 2 GPUs
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Beginnen Sie das Training von einem vortrainierten *.pt Modell unter Verwendung der GPUs 0 und 1
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
|
||||
```
|
||||
|
||||
Indem sie die Rechenleistung der M1/M2-Chips nutzen, ermöglicht dies eine effizientere Verarbeitung der Trainingsaufgaben. Für detailliertere Anleitungen und fortgeschrittene Konfigurationsoptionen beziehen Sie sich bitte auf die [PyTorch MPS-Dokumentation](https://pytorch.org/docs/stable/notes/mps.html).
|
||||
|
||||
## Protokollierung
|
||||
|
||||
Beim Training eines YOLOv8-Modells kann es wertvoll sein, die Leistung des Modells im Laufe der Zeit zu verfolgen. Hier kommt die Protokollierung ins Spiel. Ultralytics' YOLO unterstützt drei Typen von Loggern - Comet, ClearML und TensorBoard.
|
||||
|
||||
Um einen Logger zu verwenden, wählen Sie ihn aus dem Dropdown-Menü im obigen Codeausschnitt aus und führen ihn aus. Der ausgewählte Logger wird installiert und initialisiert.
|
||||
|
||||
### Comet
|
||||
|
||||
[Comet](https://www.comet.ml/site/) ist eine Plattform, die Datenwissenschaftlern und Entwicklern erlaubt, Experimente und Modelle zu verfolgen, zu vergleichen, zu erklären und zu optimieren. Es bietet Funktionen wie Echtzeitmetriken, Code-Diffs und das Verfolgen von Hyperparametern.
|
||||
|
||||
Um Comet zu verwenden:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
# pip installieren comet_ml
|
||||
import comet_ml
|
||||
|
||||
comet_ml.init()
|
||||
```
|
||||
|
||||
Vergessen Sie nicht, sich auf der Comet-Website anzumelden und Ihren API-Schlüssel zu erhalten. Sie müssen diesen zu Ihren Umgebungsvariablen oder Ihrem Skript hinzufügen, um Ihre Experimente zu protokollieren.
|
||||
|
||||
### ClearML
|
||||
|
||||
[ClearML](https://www.clear.ml/) ist eine Open-Source-Plattform, die das Verfolgen von Experimenten automatisiert und hilft, Ressourcen effizient zu teilen. Sie ist darauf ausgelegt, Teams bei der Verwaltung, Ausführung und Reproduktion ihrer ML-Arbeiten effizienter zu unterstützen.
|
||||
|
||||
Um ClearML zu verwenden:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
# pip installieren clearml
|
||||
import clearml
|
||||
|
||||
clearml.browser_login()
|
||||
```
|
||||
|
||||
Nach dem Ausführen dieses Skripts müssen Sie sich auf dem Browser bei Ihrem ClearML-Konto anmelden und Ihre Sitzung authentifizieren.
|
||||
|
||||
### TensorBoard
|
||||
|
||||
[TensorBoard](https://www.tensorflow.org/tensorboard) ist ein Visualisierungstoolset für TensorFlow. Es ermöglicht Ihnen, Ihren TensorFlow-Graphen zu visualisieren, quantitative Metriken über die Ausführung Ihres Graphen zu plotten und zusätzliche Daten wie Bilder zu zeigen, die durch ihn hindurchgehen.
|
||||
|
||||
Um TensorBoard in [Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb) zu verwenden:
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
load_ext tensorboard
|
||||
tensorboard --logdir ultralytics/runs # ersetzen Sie mit Ihrem 'runs' Verzeichnis
|
||||
```
|
||||
|
||||
Um TensorBoard lokal auszuführen, führen Sie den folgenden Befehl aus und betrachten Sie die Ergebnisse unter http://localhost:6006/.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
tensorboard --logdir ultralytics/runs # ersetzen Sie mit Ihrem 'runs' Verzeichnis
|
||||
```
|
||||
|
||||
Dies lädt TensorBoard und weist es an, das Verzeichnis zu verwenden, in dem Ihre Trainingsprotokolle gespeichert sind.
|
||||
|
||||
Nachdem Sie Ihren Logger eingerichtet haben, können Sie mit Ihrem Modelltraining fortfahren. Alle Trainingsmetriken werden automatisch in Ihrer gewählten Plattform protokolliert, und Sie können auf diese Protokolle zugreifen, um die Leistung Ihres Modells im Laufe der Zeit zu überwachen, verschiedene Modelle zu vergleichen und Bereiche für Verbesserungen zu identifizieren.
|
||||
|
|
@ -1,86 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Anleitung zur Validierung von YOLOv8-Modellen. Erfahren Sie, wie Sie die Leistung Ihrer YOLO-Modelle mit Validierungseinstellungen und Metriken in Python und CLI-Beispielen bewerten können.
|
||||
keywords: Ultralytics, YOLO-Dokumente, YOLOv8, Validierung, Modellbewertung, Hyperparameter, Genauigkeit, Metriken, Python, CLI
|
||||
---
|
||||
|
||||
# Modellvalidierung mit Ultralytics YOLO
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO-Ökosystem und Integrationen">
|
||||
|
||||
## Einführung
|
||||
|
||||
Die Validierung ist ein kritischer Schritt im Machine-Learning-Prozess, der es Ihnen ermöglicht, die Qualität Ihrer trainierten Modelle zu bewerten. Der Val-Modus in Ultralytics YOLOv8 bietet eine robuste Suite von Tools und Metriken zur Bewertung der Leistung Ihrer Objekterkennungsmodelle. Dieser Leitfaden dient als umfassende Ressource, um zu verstehen, wie Sie den Val-Modus effektiv nutzen können, um sicherzustellen, dass Ihre Modelle sowohl genau als auch zuverlässig sind.
|
||||
|
||||
## Warum mit Ultralytics YOLO validieren?
|
||||
|
||||
Hier sind die Vorteile der Verwendung des Val-Modus von YOLOv8:
|
||||
|
||||
- **Präzision:** Erhalten Sie genaue Metriken wie mAP50, mAP75 und mAP50-95, um Ihr Modell umfassend zu bewerten.
|
||||
- **Bequemlichkeit:** Nutzen Sie integrierte Funktionen, die Trainingseinstellungen speichern und so den Validierungsprozess vereinfachen.
|
||||
- **Flexibilität:** Validieren Sie Ihr Modell mit den gleichen oder verschiedenen Datensätzen und Bildgrößen.
|
||||
- **Hyperparameter-Tuning:** Verwenden Sie Validierungsmetriken, um Ihr Modell für eine bessere Leistung zu optimieren.
|
||||
|
||||
### Schlüsselfunktionen des Val-Modus
|
||||
|
||||
Dies sind die bemerkenswerten Funktionen, die der Val-Modus von YOLOv8 bietet:
|
||||
|
||||
- **Automatisierte Einstellungen:** Modelle erinnern sich an ihre Trainingskonfigurationen für eine unkomplizierte Validierung.
|
||||
- **Unterstützung mehrerer Metriken:** Bewerten Sie Ihr Modell anhand einer Reihe von Genauigkeitsmetriken.
|
||||
- **CLI- und Python-API:** Wählen Sie zwischen Befehlszeilenschnittstelle oder Python-API basierend auf Ihrer Präferenz für die Validierung.
|
||||
- **Datenkompatibilität:** Funktioniert nahtlos mit Datensätzen, die während der Trainingsphase sowie mit benutzerdefinierten Datensätzen verwendet wurden.
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
* YOLOv8-Modelle speichern automatisch ihre Trainingseinstellungen, sodass Sie ein Modell mit der gleichen Bildgröße und dem ursprünglichen Datensatz leicht validieren können, indem Sie einfach `yolo val model=yolov8n.pt` oder `model('yolov8n.pt').val()` ausführen
|
||||
|
||||
## Beispielverwendung
|
||||
|
||||
Validieren Sie die Genauigkeit des trainierten YOLOv8n-Modells auf dem COCO128-Datensatz. Es muss kein Argument übergeben werden, da das `model` seine Trainings-`data` und Argumente als Modellattribute speichert. Siehe Abschnitt „Argumente“ unten für eine vollständige Liste der Exportargumente.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n.pt') # ein offizielles Modell laden
|
||||
model = YOLO('path/to/best.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Modell validieren
|
||||
metrics = model.val() # keine Argumente benötigt, Datensatz und Einstellungen gespeichert
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # eine Liste enthält map50-95 jeder Kategorie
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # offizielles Modell validieren
|
||||
yolo detect val model=path/to/best.pt # benutzerdefiniertes Modell validieren
|
||||
```
|
||||
|
||||
## Argumente
|
||||
|
||||
Validierungseinstellungen für YOLO-Modelle beziehen sich auf verschiedene Hyperparameter und Konfigurationen, die verwendet werden, um die Leistung des Modells an einem Validierungsdatensatz zu bewerten. Diese Einstellungen können die Leistung, Geschwindigkeit und Genauigkeit des Modells beeinflussen. Einige gängige YOLO-Validierungseinstellungen umfassen die Batch-Größe, die Häufigkeit der Validierung während des Trainings und die Metriken zur Bewertung der Modellleistung. Andere Faktoren, die den Validierungsprozess beeinflussen können, sind die Größe und Zusammensetzung des Validierungsdatensatzes und die spezifische Aufgabe, für die das Modell verwendet wird. Es ist wichtig, diese Einstellungen sorgfältig abzustimmen und zu experimentieren, um sicherzustellen, dass das Modell auf dem Validierungsdatensatz gut funktioniert sowie Überanpassung zu erkennen und zu verhindern.
|
||||
|
||||
| Key | Value | Beschreibung |
|
||||
|---------------|---------|---------------------------------------------------------------------------------|
|
||||
| `data` | `None` | Pfad zur Datendatei, z.B. coco128.yaml |
|
||||
| `imgsz` | `640` | Größe der Eingabebilder als ganzzahlige Zahl |
|
||||
| `batch` | `16` | Anzahl der Bilder pro Batch (-1 für AutoBatch) |
|
||||
| `save_json` | `False` | Ergebnisse in JSON-Datei speichern |
|
||||
| `save_hybrid` | `False` | hybride Version der Labels speichern (Labels + zusätzliche Vorhersagen) |
|
||||
| `conf` | `0.001` | Objekterkennungsschwelle für Zuversichtlichkeit |
|
||||
| `iou` | `0.6` | Schwellenwert für IoU (Intersection over Union) für NMS |
|
||||
| `max_det` | `300` | maximale Anzahl an Vorhersagen pro Bild |
|
||||
| `half` | `True` | Halbpräzision verwenden (FP16) |
|
||||
| `device` | `None` | Gerät zur Ausführung, z.B. CUDA device=0/1/2/3 oder device=cpu |
|
||||
| `dnn` | `False` | OpenCV DNN für ONNX-Inf erenz nutzen |
|
||||
| `plots` | `False` | Diagramme während des Trainings anzeigen |
|
||||
| `rect` | `False` | rechteckige Validierung mit jeder Batch-Charge für minimale Polsterung |
|
||||
| `split` | `val` | Zu verwendende Daten-Teilmenge für Validierung, z.B. 'val', 'test' oder 'train' |
|
||||
|
|
||||
|
|
@ -1,198 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Entdecken Sie verschiedene Methoden zur Installation von Ultralytics mit Pip, Conda, Git und Docker. Erfahren Sie, wie Sie Ultralytics über die Befehlszeilenschnittstelle oder innerhalb Ihrer Python-Projekte verwenden können.
|
||||
keywords: Ultralytics-Installation, pip installieren Ultralytics, Docker installieren Ultralytics, Ultralytics-Befehlszeilenschnittstelle, Ultralytics Python-Schnittstelle
|
||||
---
|
||||
|
||||
## Ultralytics installieren
|
||||
|
||||
Ultralytics bietet verschiedene Installationsmethoden, darunter Pip, Conda und Docker. Installiere YOLOv8 über das `ultralytics` Pip-Paket für die neueste stabile Veröffentlichung oder indem du das [Ultralytics GitHub-Repository](https://github.com/ultralytics/ultralytics) klonst für die aktuellste Version. Docker kann verwendet werden, um das Paket in einem isolierten Container auszuführen, ohne eine lokale Installation vornehmen zu müssen.
|
||||
|
||||
!!! Example "Installieren"
|
||||
|
||||
=== "Pip-Installation (empfohlen)"
|
||||
Installieren Sie das `ultralytics` Paket mit Pip oder aktualisieren Sie eine bestehende Installation, indem Sie `pip install -U ultralytics` ausführen. Besuchen Sie den Python Package Index (PyPI) für weitere Details zum `ultralytics` Paket: [https://pypi.org/project/ultralytics/](https://pypi.org/project/ultralytics/).
|
||||
|
||||
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
||||
|
||||
```bash
|
||||
# Installiere das ultralytics Paket von PyPI
|
||||
pip install ultralytics
|
||||
```
|
||||
|
||||
Sie können auch das `ultralytics` Paket direkt vom GitHub [Repository](https://github.com/ultralytics/ultralytics) installieren. Dies könnte nützlich sein, wenn Sie die neueste Entwicklerversion möchten. Stellen Sie sicher, dass das Git-Kommandozeilen-Tool auf Ihrem System installiert ist. Der Befehl `@main` installiert den `main` Branch und kann zu einem anderen Branch geändert werden, z. B. `@my-branch`, oder ganz entfernt werden, um auf den `main` Branch standardmäßig zurückzugreifen.
|
||||
|
||||
```bash
|
||||
# Installiere das ultralytics Paket von GitHub
|
||||
pip install git+https://github.com/ultralytics/ultralytics.git@main
|
||||
```
|
||||
|
||||
|
||||
=== "Conda-Installation"
|
||||
Conda ist ein alternativer Paketmanager zu Pip, der ebenfalls für die Installation verwendet werden kann. Besuche Anaconda für weitere Details unter [https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics). Ultralytics Feedstock Repository für die Aktualisierung des Conda-Pakets befindet sich unter [https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/).
|
||||
|
||||
|
||||
[](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics)
|
||||
|
||||
```bash
|
||||
# Installiere das ultralytics Paket mit Conda
|
||||
conda install -c conda-forge ultralytics
|
||||
```
|
||||
|
||||
!!! Note "Hinweis"
|
||||
|
||||
Wenn Sie in einer CUDA-Umgebung installieren, ist es am besten, `ultralytics`, `pytorch` und `pytorch-cuda` im selben Befehl zu installieren, um dem Conda-Paketmanager zu ermöglichen, Konflikte zu lösen, oder `pytorch-cuda` als letztes zu installieren, damit es das CPU-spezifische `pytorch` Paket bei Bedarf überschreiben kann.
|
||||
```bash
|
||||
# Installiere alle Pakete zusammen mit Conda
|
||||
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
|
||||
```
|
||||
|
||||
### Conda Docker-Image
|
||||
|
||||
Ultralytics Conda Docker-Images sind ebenfalls von [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics) verfügbar. Diese Bilder basieren auf [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) und bieten eine einfache Möglichkeit, `ultralytics` in einer Conda-Umgebung zu nutzen.
|
||||
|
||||
```bash
|
||||
# Setze Image-Name als Variable
|
||||
t=ultralytics/ultralytics:latest-conda
|
||||
|
||||
# Ziehe das neuste ultralytics Image von Docker Hub
|
||||
sudo docker pull $t
|
||||
|
||||
# Führe das ultralytics Image in einem Container mit GPU-Unterstützung aus
|
||||
sudo docker run -it --ipc=host --gpus all $t # alle GPUs
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # spezifische GPUs angeben
|
||||
```
|
||||
|
||||
=== "Git klonen"
|
||||
Klonen Sie das `ultralytics` Repository, wenn Sie einen Beitrag zur Entwicklung leisten möchten oder mit dem neuesten Quellcode experimentieren wollen. Nach dem Klonen navigieren Sie in das Verzeichnis und installieren das Paket im editierbaren Modus `-e` mit Pip.
|
||||
```bash
|
||||
# Klonen Sie das ultralytics Repository
|
||||
git clone https://github.com/ultralytics/ultralytics
|
||||
|
||||
# Navigiere zum geklonten Verzeichnis
|
||||
cd ultralytics
|
||||
|
||||
# Installiere das Paket im editierbaren Modus für die Entwicklung
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
Siehe die `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) Datei für eine Liste der Abhängigkeiten. Beachten Sie, dass alle oben genannten Beispiele alle erforderlichen Abhängigkeiten installieren.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/_a7cVL9hqnk"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Ultralytics YOLO Quick Start Guide
|
||||
</p>
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
PyTorch-Anforderungen variieren je nach Betriebssystem und CUDA-Anforderungen, daher wird empfohlen, PyTorch zuerst gemäß den Anweisungen unter [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally) zu installieren.
|
||||
|
||||
<a href="https://pytorch.org/get-started/locally/">
|
||||
<img width="800" alt="PyTorch Installationsanweisungen" src="https://user-images.githubusercontent.com/26833433/228650108-ab0ec98a-b328-4f40-a40d-95355e8a84e3.png">
|
||||
</a>
|
||||
|
||||
## Ultralytics mit CLI verwenden
|
||||
|
||||
Die Befehlszeilenschnittstelle (CLI) von Ultralytics ermöglicht einfache Einzeilige Befehle ohne die Notwendigkeit einer Python-Umgebung. CLI erfordert keine Anpassung oder Python-Code. Sie können alle Aufgaben einfach vom Terminal aus mit dem `yolo` Befehl ausführen. Schauen Sie sich den [CLI-Leitfaden](/../usage/cli.md) an, um mehr über die Verwendung von YOLOv8 über die Befehlszeile zu erfahren.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Syntax"
|
||||
|
||||
Ultralytics `yolo` Befehle verwenden die folgende Syntax:
|
||||
```bash
|
||||
yolo TASK MODE ARGS
|
||||
|
||||
Wo TASK (optional) einer von [detect, segment, classify] ist
|
||||
MODE (erforderlich) einer von [train, val, predict, export, track] ist
|
||||
ARGS (optional) eine beliebige Anzahl von benutzerdefinierten 'arg=value' Paaren wie 'imgsz=320', die Vorgaben überschreiben.
|
||||
```
|
||||
Sehen Sie alle ARGS im vollständigen [Konfigurationsleitfaden](/../usage/cfg.md) oder mit `yolo cfg`
|
||||
|
||||
=== "Trainieren"
|
||||
|
||||
Trainieren Sie ein Erkennungsmodell für 10 Epochen mit einer Anfangslernerate von 0.01
|
||||
```bash
|
||||
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||
```
|
||||
|
||||
=== "Vorhersagen"
|
||||
|
||||
Vorhersagen eines YouTube-Videos mit einem vortrainierten Segmentierungsmodell bei einer Bildgröße von 320:
|
||||
```bash
|
||||
yolo predict model=yolov8n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
|
||||
```
|
||||
|
||||
=== "Val"
|
||||
|
||||
Val ein vortrainiertes Erkennungsmodell bei Batch-Größe 1 und Bildgröße 640:
|
||||
```bash
|
||||
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||
```
|
||||
|
||||
=== "Exportieren"
|
||||
|
||||
Exportieren Sie ein YOLOv8n-Klassifikationsmodell im ONNX-Format bei einer Bildgröße von 224 mal 128 (kein TASK erforderlich)
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
|
||||
```
|
||||
|
||||
=== "Speziell"
|
||||
|
||||
Führen Sie spezielle Befehle aus, um Version, Einstellungen zu sehen, Checks auszuführen und mehr:
|
||||
```bash
|
||||
yolo help
|
||||
yolo checks
|
||||
yolo version
|
||||
yolo settings
|
||||
yolo copy-cfg
|
||||
yolo cfg
|
||||
```
|
||||
|
||||
!!! Warning "Warnung"
|
||||
|
||||
Argumente müssen als `arg=val` Paare übergeben werden, getrennt durch ein Gleichheitszeichen `=` und durch Leerzeichen ` ` zwischen den Paaren. Verwenden Sie keine `--` Argumentpräfixe oder Kommata `,` zwischen den Argumenten.
|
||||
|
||||
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
|
||||
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
|
||||
- `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
|
||||
|
||||
[CLI-Leitfaden](/../usage/cli.md){ .md-button }
|
||||
|
||||
## Ultralytics mit Python verwenden
|
||||
|
||||
Die Python-Schnittstelle von YOLOv8 ermöglicht eine nahtlose Integration in Ihre Python-Projekte und erleichtert das Laden, Ausführen und Verarbeiten der Modellausgabe. Konzipiert für Einfachheit und Benutzerfreundlichkeit, ermöglicht die Python-Schnittstelle Benutzern, Objekterkennung, Segmentierung und Klassifizierung schnell in ihren Projekten zu implementieren. Dies macht die Python-Schnittstelle von YOLOv8 zu einem unschätzbaren Werkzeug für jeden, der diese Funktionalitäten in seine Python-Projekte integrieren möchte.
|
||||
|
||||
Benutzer können beispielsweise ein Modell laden, es trainieren, seine Leistung an einem Validierungsset auswerten und sogar in das ONNX-Format exportieren, und das alles mit nur wenigen Codezeilen. Schauen Sie sich den [Python-Leitfaden](/../usage/python.md) an, um mehr über die Verwendung von YOLOv8 in Ihren_python_pro_jek_ten zu erfahren.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Erstellen Sie ein neues YOLO Modell von Grund auf
|
||||
model = YOLO('yolov8n.yaml')
|
||||
|
||||
# Laden Sie ein vortrainiertes YOLO Modell (empfohlen für das Training)
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Trainieren Sie das Modell mit dem Datensatz 'coco128.yaml' für 3 Epochen
|
||||
results = model.train(data='coco128.yaml', epochs=3)
|
||||
|
||||
# Bewerten Sie die Leistung des Modells am Validierungssatz
|
||||
results = model.val()
|
||||
|
||||
# Führen Sie eine Objekterkennung an einem Bild mit dem Modell durch
|
||||
results = model('https://ultralytics.com/images/bus.jpg')
|
||||
|
||||
# Exportieren Sie das Modell ins ONNX-Format
|
||||
success = model.export(format='onnx')
|
||||
```
|
||||
|
||||
[Python-Leitfaden](/../usage/python.md){.md-button .md-button--primary}
|
||||
|
|
@ -1,172 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie mehr über YOLOv8 Classify-Modelle zur Bildklassifizierung. Erhalten Sie detaillierte Informationen über die Liste vortrainierter Modelle und wie man Modelle trainiert, validiert, vorhersagt und exportiert.
|
||||
keywords: Ultralytics, YOLOv8, Bildklassifizierung, Vortrainierte Modelle, YOLOv8n-cls, Training, Validierung, Vorhersage, Modellexport
|
||||
---
|
||||
|
||||
# Bildklassifizierung
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418606-adf35c62-2e11-405d-84c6-b84e7d013804.png" alt="Beispiele für Bildklassifizierung">
|
||||
|
||||
Bildklassifizierung ist die einfachste der drei Aufgaben und besteht darin, ein ganzes Bild in eine von einem Satz vordefinierter Klassen zu klassifizieren.
|
||||
|
||||
Die Ausgabe eines Bildklassifizierers ist ein einzelnes Klassenlabel und eine Vertrauenspunktzahl. Bildklassifizierung ist nützlich, wenn Sie nur wissen müssen, zu welcher Klasse ein Bild gehört, und nicht wissen müssen, wo sich Objekte dieser Klasse befinden oder wie ihre genaue Form ist.
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
YOLOv8 Classify-Modelle verwenden den Suffix `-cls`, z.B. `yolov8n-cls.pt` und sind auf [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml) vortrainiert.
|
||||
|
||||
## [Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
Hier werden vortrainierte YOLOv8 Classify-Modelle gezeigt. Detect-, Segment- und Pose-Modelle sind auf dem [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)-Datensatz vortrainiert, während Classify-Modelle auf dem [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)-Datensatz vortrainiert sind.
|
||||
|
||||
[Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) werden automatisch vom neuesten Ultralytics-[Release](https://github.com/ultralytics/assets/releases) beim ersten Gebrauch heruntergeladen.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | Genauigkeit<br><sup>top1 | Genauigkeit<br><sup>top5 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) bei 640 |
|
||||
|----------------------------------------------------------------------------------------------|-----------------------|--------------------------|--------------------------|------------------------------------------|-----------------------------------------------|-----------------------|---------------------------|
|
||||
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
|
||||
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
|
||||
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
|
||||
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
|
||||
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
|
||||
|
||||
- **Genauigkeit**-Werte sind Modellgenauigkeiten auf dem [ImageNet](https://www.image-net.org/)-Datensatz Validierungsset.
|
||||
<br>Zur Reproduktion `yolo val classify data=pfad/zu/ImageNet device=0 verwenden`
|
||||
- **Geschwindigkeit** Durchschnitt über ImageNet-Validierungsbilder mit einer [Amazon EC2 P4d](https://aws.amazon.com/de/ec2/instance-types/p4/)-Instanz.
|
||||
<br>Zur Reproduktion `yolo val classify data=pfad/zu/ImageNet batch=1 device=0|cpu verwenden`
|
||||
|
||||
## Trainieren
|
||||
|
||||
Trainieren Sie das YOLOv8n-cls-Modell auf dem MNIST160-Datensatz für 100 Epochen bei Bildgröße 64. Eine vollständige Liste der verfügbaren Argumente finden Sie auf der Seite [Konfiguration](/../usage/cfg.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein Modell laden
|
||||
model = YOLO('yolov8n-cls.yaml') # ein neues Modell aus YAML erstellen
|
||||
model = YOLO('yolov8n-cls.pt') # ein vortrainiertes Modell laden (empfohlen für das Training)
|
||||
model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # aus YAML erstellen und Gewichte übertragen
|
||||
|
||||
# Das Modell trainieren
|
||||
results = model.train(data='mnist160', epochs=100, imgsz=64)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Ein neues Modell aus YAML erstellen und das Training von Grund auf starten
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.yaml epochs=100 imgsz=64
|
||||
|
||||
# Das Training von einem vortrainierten *.pt Modell starten
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64
|
||||
|
||||
# Ein neues Modell aus YAML erstellen, vortrainierte Gewichte übertragen und das Training starten
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.yaml pretrained=yolov8n-cls.pt epochs=100 imgsz=64
|
||||
```
|
||||
|
||||
### Datenformat
|
||||
|
||||
Das Datenformat für YOLO-Klassifizierungsdatensätze finden Sie im Detail im [Datenleitfaden](../../../datasets/classify/index.md).
|
||||
|
||||
## Validieren
|
||||
|
||||
Validieren Sie die Genauigkeit des trainierten YOLOv8n-cls-Modells auf dem MNIST160-Datensatz. Kein Argument muss übergeben werden, da das `modell` seine Trainings`daten` und Argumente als Modellattribute behält.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein Modell laden
|
||||
model = YOLO('yolov8n-cls.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Das Modell validieren
|
||||
metrics = model.val() # keine Argumente benötigt, Datensatz und Einstellungen gespeichert
|
||||
metrics.top1 # top1 Genauigkeit
|
||||
metrics.top5 # top5 Genauigkeit
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo classify val model=yolov8n-cls.pt # ein offizielles Modell validieren
|
||||
yolo classify val model=pfad/zu/best.pt # ein benutzerdefiniertes Modell validieren
|
||||
```
|
||||
|
||||
## Vorhersagen
|
||||
|
||||
Verwenden Sie ein trainiertes YOLOv8n-cls-Modell, um Vorhersagen auf Bildern durchzuführen.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein Modell laden
|
||||
model = YOLO('yolov8n-cls.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Mit dem Modell vorhersagen
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # Vorhersage auf einem Bild
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' # mit offiziellem Modell vorhersagen
|
||||
yolo classify predict model=pfad/zu/best.pt source='https://ultralytics.com/images/bus.jpg' # mit benutzerdefiniertem Modell vorhersagen
|
||||
```
|
||||
|
||||
Vollständige Details zum `predict`-Modus finden Sie auf der Seite [Vorhersage](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## Exportieren
|
||||
|
||||
Exportieren Sie ein YOLOv8n-cls-Modell in ein anderes Format wie ONNX, CoreML usw.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Ein Modell laden
|
||||
model = YOLO('yolov8n-cls.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # ein benutzerdefiniertes trainiertes Modell laden
|
||||
|
||||
# Das Modell exportieren
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx # offizielles Modell exportieren
|
||||
yolo export model=pfad/zu/best.pt format=onnx # benutzerdefiniertes trainiertes Modell exportieren
|
||||
```
|
||||
|
||||
Verfügbare YOLOv8-cls Exportformate stehen in der folgenden Tabelle. Sie können direkt auf exportierten Modellen vorhersagen oder validieren, d.h. `yolo predict model=yolov8n-cls.onnx`. Nutzungsexempel werden für Ihr Modell nach Abschluss des Exports angezeigt.
|
||||
|
||||
| Format | `format`-Argument | Modell | Metadaten | Argumente |
|
||||
|--------------------------------------------------------------------|-------------------|-------------------------------|-----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-cls.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-cls.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-cls.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-cls_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-cls.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-cls.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-cls_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-cls.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-cls.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-cls_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-cls_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-cls_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-cls_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
Vollständige Details zum `export` finden Sie auf der Seite [Export](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1,184 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Offizielle Dokumentation für YOLOv8 von Ultralytics. Erfahren Sie, wie Sie Modelle trainieren, validieren, vorhersagen und in verschiedenen Formaten exportieren. Einschließlich detaillierter Leistungsstatistiken.
|
||||
keywords: YOLOv8, Ultralytics, Objekterkennung, vortrainierte Modelle, Training, Validierung, Vorhersage, Modell-Export, COCO, ImageNet, PyTorch, ONNX, CoreML
|
||||
---
|
||||
|
||||
# Objekterkennung
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418624-5785cb93-74c9-4541-9179-d5c6782d491a.png" alt="Beispiele für Objekterkennung">
|
||||
|
||||
Objekterkennung ist eine Aufgabe, die das Identifizieren der Position und Klasse von Objekten in einem Bild oder Videostream umfasst.
|
||||
|
||||
Die Ausgabe eines Objekterkenners ist eine Menge von Begrenzungsrahmen, die die Objekte im Bild umschließen, zusammen mit Klassenbezeichnungen und Vertrauenswerten für jedes Feld. Objekterkennung ist eine gute Wahl, wenn Sie Objekte von Interesse in einer Szene identifizieren müssen, aber nicht genau wissen müssen, wo das Objekt ist oder wie seine genaue Form ist.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/5ku7npMrW40?si=6HQO1dDXunV8gekh"
|
||||
title="YouTube-Video-Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Sehen Sie:</strong> Objekterkennung mit vortrainiertem Ultralytics YOLOv8 Modell.
|
||||
</p>
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
YOLOv8 Detect Modelle sind die Standard YOLOv8 Modelle, zum Beispiel `yolov8n.pt`, und sind vortrainiert auf dem [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)-Datensatz.
|
||||
|
||||
## [Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
Hier werden die vortrainierten YOLOv8 Detect Modelle gezeigt. Detect, Segment und Pose Modelle sind vortrainiert auf dem [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)-Datensatz, während die Classify Modelle vortrainiert sind auf dem [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)-Datensatz.
|
||||
|
||||
[Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) werden automatisch von der neuesten Ultralytics [Veröffentlichung](https://github.com/ultralytics/assets/releases) bei Erstbenutzung heruntergeladen.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>val<br>50-95 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
|--------------------------------------------------------------------------------------|-----------------------|----------------------|------------------------------------------|-----------------------------------------------|--------------------|-------------------|
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
|
||||
|
||||
- **mAP<sup>val</sup>** Werte sind für Single-Modell Single-Scale auf dem [COCO val2017](http://cocodataset.org) Datensatz.
|
||||
<br>Reproduzieren mit `yolo val detect data=coco.yaml device=0`
|
||||
- **Geschwindigkeit** gemittelt über COCO Val Bilder mit einer [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)-Instanz.
|
||||
<br>Reproduzieren mit `yolo val detect data=coco128.yaml batch=1 device=0|cpu`
|
||||
|
||||
## Training
|
||||
|
||||
YOLOv8n auf dem COCO128-Datensatz für 100 Epochen bei Bildgröße 640 trainieren. Für eine vollständige Liste verfügbarer Argumente siehe die [Konfigurationsseite](/../usage/cfg.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n.yaml') # ein neues Modell aus YAML aufbauen
|
||||
model = YOLO('yolov8n.pt') # ein vortrainiertes Modell laden (empfohlen für Training)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # aus YAML aufbauen und Gewichte übertragen
|
||||
|
||||
# Das Modell trainieren
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Ein neues Modell aus YAML aufbauen und Training von Grund auf starten
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# Training von einem vortrainierten *.pt Modell starten
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# Ein neues Modell aus YAML aufbauen, vortrainierte Gewichte übertragen und Training starten
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### Datenformat
|
||||
|
||||
Das Datenformat für YOLO-Erkennungsdatensätze finden Sie detailliert im [Dataset Guide](../../../datasets/detect/index.md). Um Ihren vorhandenen Datensatz von anderen Formaten (wie COCO etc.) in das YOLO-Format zu konvertieren, verwenden Sie bitte das [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO)-Tool von Ultralytics.
|
||||
|
||||
## Validierung
|
||||
|
||||
Genauigkeit des trainierten YOLOv8n-Modells auf dem COCO128-Datensatz validieren. Es müssen keine Argumente übergeben werden, da das `modell` seine Trainingsdaten und Argumente als Modellattribute beibehält.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zum/besten.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Das Modell validieren
|
||||
metrics = model.val() # keine Argumente nötig, Datensatz und Einstellungen erinnert
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # eine Liste enthält map50-95 jeder Kategorie
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # offizielles Modell validieren
|
||||
yolo detect val model=pfad/zum/besten.pt # benutzerdefiniertes Modell validieren
|
||||
```
|
||||
|
||||
## Vorhersage
|
||||
|
||||
Ein trainiertes YOLOv8n-Modell verwenden, um Vorhersagen auf Bildern durchzuführen.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zum/besten.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Mit dem Modell vorhersagen
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # Vorhersage auf einem Bild
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # Vorhersage mit offiziellem Modell
|
||||
yolo detect predict model=pfad/zum/besten.pt source='https://ultralytics.com/images/bus.jpg' # Vorhersage mit benutzerdefiniertem Modell
|
||||
```
|
||||
|
||||
Volle Details über den `predict`-Modus finden Sie auf der [Predict-Seite](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## Export
|
||||
|
||||
Ein YOLOv8n-Modell in ein anderes Format wie ONNX, CoreML usw. exportieren.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zum/besten.pt') # ein benutzerdefiniert trainiertes Modell laden
|
||||
|
||||
# Das Modell exportieren
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # offizielles Modell exportieren
|
||||
yolo export model=pfad/zum/besten.pt format=onnx # benutzerdefiniert trainiertes Modell exportieren
|
||||
```
|
||||
|
||||
Verfügbare YOLOv8 Exportformate sind in der untenstehenden Tabelle aufgeführt. Sie können direkt auf den exportierten Modellen Vorhersagen treffen oder diese validieren, zum Beispiel `yolo predict model=yolov8n.onnx`. Verwendungsbeispiele werden für Ihr Modell nach Abschluss des Exports angezeigt.
|
||||
|
||||
| Format | `format`-Argument | Modell | Metadaten | Argumente |
|
||||
|--------------------------------------------------------------------|-------------------|---------------------------|-----------|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
Volle Details zum `export` finden Sie auf der [Export-Seite](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1,55 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie, welche grundlegenden Aufgaben im Bereich der Computer Vision YOLOv8 durchführen kann, einschließlich Erkennung, Segmentierung, Klassifizierung und Haltungsschätzung, und wie sie in Ihren KI-Projekten verwendet werden können.
|
||||
keywords: Ultralytics, YOLOv8, Erkennung, Segmentierung, Klassifizierung, Pose-Schätzung, KI-Framework, Computer Vision-Aufgaben
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv8 Aufgaben
|
||||
|
||||
<br>
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/im/banner-tasks.png" alt="Ultralytics YOLO unterstützte Aufgaben">
|
||||
|
||||
YOLOv8 ist ein KI-Framework, das mehrere Aufgaben im Bereich der Computer Vision **unterstützt**. Das Framework kann für die [Erkennung](detect.md), [Segmentierung](segment.md), [Klassifizierung](classify.md) und die [Pose](pose.md)-Schätzung verwendet werden. Jede dieser Aufgaben hat ein unterschiedliches Ziel und Anwendungsgebiete.
|
||||
|
||||
!!! Note "Hinweis"
|
||||
|
||||
🚧 Unsere mehrsprachigen Dokumentation befindet sich derzeit im Aufbau und wir arbeiten hart daran, sie zu verbessern. Danke für Ihre Geduld! 🙏
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/NAs-cfq9BDw"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Schauen Sie zu:</strong> Entdecken Sie Ultralytics YOLO Aufgaben: Objekterkennung, Segmentierung, Verfolgung und Pose-Schätzung.
|
||||
</p>
|
||||
|
||||
## [Erkennung](detect.md)
|
||||
|
||||
Erkennung ist die primäre von YOLOv8 unterstützte Aufgabe. Sie beinhaltet das Erkennen von Objekten in einem Bild oder Videobild und das Zeichnen von Rahmen um sie herum. Die erkannten Objekte werden anhand ihrer Merkmale in verschiedene Kategorien klassifiziert. YOLOv8 kann mehrere Objekte in einem einzelnen Bild oder Videobild mit hoher Genauigkeit und Geschwindigkeit erkennen.
|
||||
|
||||
[Beispiele für Erkennung](detect.md){ .md-button }
|
||||
|
||||
## [Segmentierung](segment.md)
|
||||
|
||||
Segmentierung ist eine Aufgabe, die das Aufteilen eines Bildes in unterschiedliche Regionen anhand des Bildinhalts beinhaltet. Jeder Region wird basierend auf ihrem Inhalt eine Markierung zugewiesen. Diese Aufgabe ist nützlich in Anwendungen wie der Bildsegmentierung und medizinischen Bildgebung. YOLOv8 verwendet eine Variante der U-Net-Architektur, um die Segmentierung durchzuführen.
|
||||
|
||||
[Beispiele für Segmentierung](segment.md){ .md-button }
|
||||
|
||||
## [Klassifizierung](classify.md)
|
||||
|
||||
Klassifizierung ist eine Aufgabe, die das Einordnen eines Bildes in verschiedene Kategorien umfasst. YOLOv8 kann genutzt werden, um Bilder anhand ihres Inhalts zu klassifizieren. Es verwendet eine Variante der EfficientNet-Architektur, um die Klassifizierung durchzuführen.
|
||||
|
||||
[Beispiele für Klassifizierung](classify.md){ .md-button }
|
||||
|
||||
## [Pose](pose.md)
|
||||
|
||||
Die Pose-/Keypoint-Erkennung ist eine Aufgabe, die das Erkennen von spezifischen Punkten in einem Bild oder Videobild beinhaltet. Diese Punkte werden als Keypoints bezeichnet und werden zur Bewegungsverfolgung oder Pose-Schätzung verwendet. YOLOv8 kann Keypoints in einem Bild oder Videobild mit hoher Genauigkeit und Geschwindigkeit erkennen.
|
||||
|
||||
[Beispiele für Posen](pose.md){ .md-button }
|
||||
|
||||
## Fazit
|
||||
|
||||
YOLOv8 unterstützt mehrere Aufgaben, einschließlich Erkennung, Segmentierung, Klassifizierung und Keypoint-Erkennung. Jede dieser Aufgaben hat unterschiedliche Ziele und Anwendungsgebiete. Durch das Verständnis der Unterschiede zwischen diesen Aufgaben können Sie die geeignete Aufgabe für Ihre Anwendung im Bereich der Computer Vision auswählen.
|
||||
|
|
@ -1,185 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie, wie Sie Ultralytics YOLOv8 für Aufgaben der Pose-Schätzung verwenden können. Finden Sie vortrainierte Modelle, lernen Sie, wie man eigene trainiert, validiert, vorhersagt und exportiert.
|
||||
keywords: Ultralytics, YOLO, YOLOv8, Pose-Schätzung, Erkennung von Schlüsselpunkten, Objekterkennung, vortrainierte Modelle, maschinelles Lernen, künstliche Intelligenz
|
||||
---
|
||||
|
||||
# Pose-Schätzung
|
||||
|
||||

|
||||
|
||||
Die Pose-Schätzung ist eine Aufgabe, die das Identifizieren der Lage spezifischer Punkte in einem Bild beinhaltet, die normalerweise als Schlüsselpunkte bezeichnet werden. Die Schlüsselpunkte können verschiedene Teile des Objekts wie Gelenke, Landmarken oder andere charakteristische Merkmale repräsentieren. Die Positionen der Schlüsselpunkte sind üblicherweise als eine Gruppe von 2D `[x, y]` oder 3D `[x, y, sichtbar]` Koordinaten dargestellt.
|
||||
|
||||
Das Ergebnis eines Pose-Schätzungsmodells ist eine Gruppe von Punkten, die die Schlüsselpunkte auf einem Objekt im Bild darstellen, normalerweise zusammen mit den Konfidenzwerten für jeden Punkt. Die Pose-Schätzung eignet sich gut, wenn Sie spezifische Teile eines Objekts in einer Szene identifizieren müssen und deren Lage zueinander.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/Y28xXQmju64?si=pCY4ZwejZFu6Z4kZ"
|
||||
title="YouTube-Video-Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Ansehen:</strong> Pose-Schätzung mit Ultralytics YOLOv8.
|
||||
</p>
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
YOLOv8 _pose_-Modelle verwenden den Suffix `-pose`, z. B. `yolov8n-pose.pt`. Diese Modelle sind auf dem [COCO-Schlüsselpunkte](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml)-Datensatz trainiert und für eine Vielzahl von Pose-Schätzungsaufgaben geeignet.
|
||||
|
||||
## [Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
Hier werden vortrainierte YOLOv8 Pose-Modelle gezeigt. Erkennungs-, Segmentierungs- und Pose-Modelle sind auf dem [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)-Datensatz vortrainiert, während Klassifizierungsmodelle auf dem [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)-Datensatz vortrainiert sind.
|
||||
|
||||
[Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) werden automatisch aus der neuesten Ultralytics-[Veröffentlichung](https://github.com/ultralytics/assets/releases) bei erstmaliger Verwendung heruntergeladen.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>pose<br>50-95 | mAP<sup>pose<br>50 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
|------------------------------------------------------------------------------------------------------|-----------------------|-----------------------|--------------------|------------------------------------------|-----------------------------------------------|-----------------------|-------------------|
|
||||
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50,4 | 80,1 | 131,8 | 1,18 | 3,3 | 9,2 |
|
||||
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60,0 | 86,2 | 233,2 | 1,42 | 11,6 | 30,2 |
|
||||
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65,0 | 88,8 | 456,3 | 2,00 | 26,4 | 81,0 |
|
||||
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67,6 | 90,0 | 784,5 | 2,59 | 44,4 | 168,6 |
|
||||
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69,2 | 90,2 | 1607,1 | 3,73 | 69,4 | 263,2 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71,6 | 91,2 | 4088,7 | 10,04 | 99,1 | 1066,4 |
|
||||
|
||||
- **mAP<sup>val</sup>** Werte gelten für ein einzelnes Modell mit einfacher Skala auf dem [COCO Keypoints val2017](http://cocodataset.org)-Datensatz.
|
||||
<br>Zu reproduzieren mit `yolo val pose data=coco-pose.yaml device=0`.
|
||||
- **Geschwindigkeit** gemittelt über COCO-Validierungsbilder mit einer [Amazon EC2 P4d](https://aws.amazon.com/de/ec2/instance-types/p4/)-Instanz.
|
||||
<br>Zu reproduzieren mit `yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu`.
|
||||
|
||||
## Trainieren
|
||||
|
||||
Trainieren Sie ein YOLOv8-Pose-Modell auf dem COCO128-Pose-Datensatz.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-pose.yaml') # ein neues Modell aus YAML bauen
|
||||
model = YOLO('yolov8n-pose.pt') # ein vortrainiertes Modell laden (empfohlen für das Training)
|
||||
model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # aus YAML bauen und Gewichte übertragen
|
||||
|
||||
# Modell trainieren
|
||||
results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Ein neues Modell aus YAML bauen und das Training von Grund auf starten
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640
|
||||
|
||||
# Training von einem vortrainierten *.pt Modell starten
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
|
||||
# Ein neues Modell aus YAML bauen, vortrainierte Gewichte übertragen und das Training starten
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml pretrained=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### Datensatzformat
|
||||
|
||||
Das YOLO-Pose-Datensatzformat finden Sie detailliert im [Datensatz-Leitfaden](../../../datasets/pose/index.md). Um Ihren bestehenden Datensatz aus anderen Formaten (wie COCO usw.) in das YOLO-Format zu konvertieren, verwenden Sie bitte das [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO)-Tool von Ultralytics.
|
||||
|
||||
## Validieren
|
||||
|
||||
Die Genauigkeit des trainierten YOLOv8n-Pose-Modells auf dem COCO128-Pose-Datensatz validieren. Es müssen keine Argumente übergeben werden, da das `Modell` seine Trainings`daten` und Argumente als Modellattribute beibehält.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-pose.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Modell validieren
|
||||
metrics = model.val() # keine Argumente nötig, Datensatz und Einstellungen sind gespeichert
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # Liste enthält map50-95 jeder Kategorie
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo pose val model=yolov8n-pose.pt # offizielles Modell validieren
|
||||
yolo pose val model=pfad/zu/best.pt # benutzerdefiniertes Modell validieren
|
||||
```
|
||||
|
||||
## Vorhersagen
|
||||
|
||||
Ein trainiertes YOLOv8n-Pose-Modell verwenden, um Vorhersagen auf Bildern zu machen.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-pose.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Mit dem Modell Vorhersagen machen
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # Vorhersage auf einem Bild machen
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg' # Vorhersage mit dem offiziellen Modell machen
|
||||
yolo pose predict model=pfad/zu/best.pt source='https://ultralytics.com/images/bus.jpg' # Vorhersage mit dem benutzerdefinierten Modell machen
|
||||
```
|
||||
|
||||
Vollständige `predict`-Modusdetails finden Sie auf der [Vorhersage](https://docs.ultralytics.com/modes/predict/)-Seite.
|
||||
|
||||
## Exportieren
|
||||
|
||||
Ein YOLOv8n-Pose-Modell in ein anderes Format wie ONNX, CoreML usw. exportieren.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-pose.pt') # ein offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # ein benutzerdefiniertes Modell laden
|
||||
|
||||
# Modell exportieren
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-pose.pt format=onnx # offizielles Modell exportieren
|
||||
yolo export model=pfad/zu/best.pt format=onnx # benutzerdefiniertes Modell exportieren
|
||||
```
|
||||
|
||||
Verfügbare YOLOv8-Pose-Exportformate sind in der folgenden Tabelle aufgeführt. Sie können direkt auf exportierten Modellen vorhersagen oder validieren, z. B. `yolo predict model=yolov8n-pose.onnx`. Verwendungsbeispiele werden für Ihr Modell nach Abschluss des Exports angezeigt.
|
||||
|
||||
| Format | `format` Argument | Modell | Metadaten | Argumente |
|
||||
|--------------------------------------------------------------------|-------------------|--------------------------------|-----------|-----------------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-pose.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-pose.torchscript` | ✅ | `imgsz`, `optimieren` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-pose.onnx` | ✅ | `imgsz`, `halb`, `dynamisch`, `vereinfachen`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-pose_openvino_model/` | ✅ | `imgsz`, `halb` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-pose.engine` | ✅ | `imgsz`, `halb`, `dynamisch`, `vereinfachen`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-pose.mlpackage` | ✅ | `imgsz`, `halb`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-pose_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-pose.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-pose.tflite` | ✅ | `imgsz`, `halb`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-pose_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-pose_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-pose_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-pose_ncnn_model/` | ✅ | `imgsz`, `halb` |
|
||||
|
||||
Vollständige `export`-Details finden Sie auf der [Export](https://docs.ultralytics.com/modes/export/)-Seite.
|
||||
|
|
@ -1,188 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Erfahren Sie, wie Sie Instanzsegmentierungsmodelle mit Ultralytics YOLO verwenden. Anleitungen zum Training, zur Validierung, zur Bildvorhersage und zum Export von Modellen.
|
||||
Schlagworte: yolov8, Instanzsegmentierung, Ultralytics, COCO-Datensatz, Bildsegmentierung, Objekterkennung, Modelltraining, Modellvalidierung, Bildvorhersage, Modellexport
|
||||
---
|
||||
|
||||
# Instanzsegmentierung
|
||||
|
||||

|
||||
|
||||
Instanzsegmentierung geht einen Schritt weiter als die Objekterkennung und beinhaltet die Identifizierung einzelner Objekte in einem Bild und deren Abtrennung vom Rest des Bildes.
|
||||
|
||||
Das Ergebnis eines Instanzsegmentierungsmodells ist eine Reihe von Masken oder Konturen, die jedes Objekt im Bild umreißen, zusammen mit Klassenbezeichnungen und Vertrauensscores für jedes Objekt. Instanzsegmentierung ist nützlich, wenn man nicht nur wissen muss, wo sich Objekte in einem Bild befinden, sondern auch, welche genaue Form sie haben.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/o4Zd-IeMlSY?si=37nusCzDTd74Obsp"
|
||||
title="YouTube-Video-Player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Schauen Sie:</strong> Führen Sie Segmentierung mit dem vortrainierten Ultralytics YOLOv8 Modell in Python aus.
|
||||
</p>
|
||||
|
||||
!!! Tip "Tipp"
|
||||
|
||||
YOLOv8 Segment-Modelle verwenden das Suffix `-seg`, d.h. `yolov8n-seg.pt` und sind auf dem [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)-Datensatz vortrainiert.
|
||||
|
||||
## [Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
Hier werden vortrainierte YOLOv8 Segment-Modelle gezeigt. Detect-, Segment- und Pose-Modelle sind auf dem [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)-Datensatz vortrainiert, während Classify-Modelle auf dem [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)-Datensatz vortrainiert sind.
|
||||
|
||||
[Modelle](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) laden sich automatisch von der neuesten Ultralytics [Veröffentlichung](https://github.com/ultralytics/assets/releases) beim ersten Gebrauch herunter.
|
||||
|
||||
| Modell | Größe<br><sup>(Pixel) | mAP<sup>Kasten<br>50-95 | mAP<sup>Masken<br>50-95 | Geschwindigkeit<br><sup>CPU ONNX<br>(ms) | Geschwindigkeit<br><sup>A100 TensorRT<br>(ms) | Parameter<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
|----------------------------------------------------------------------------------------------|-----------------------|-------------------------|-------------------------|------------------------------------------|-----------------------------------------------|-----------------------|-------------------|
|
||||
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
|
||||
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
|
||||
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
|
||||
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
|
||||
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
|
||||
|
||||
- Die **mAP<sup>val</sup>**-Werte sind für ein einzelnes Modell, einzelne Skala auf dem [COCO val2017](http://cocodataset.org)-Datensatz.
|
||||
<br>Zum Reproduzieren nutzen Sie `yolo val segment data=coco.yaml device=0`
|
||||
- Die **Geschwindigkeit** ist über die COCO-Validierungsbilder gemittelt und verwendet eine [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)-Instanz.
|
||||
<br>Zum Reproduzieren `yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`
|
||||
|
||||
## Training
|
||||
|
||||
Trainieren Sie YOLOv8n-seg auf dem COCO128-seg-Datensatz für 100 Epochen mit einer Bildgröße von 640. Eine vollständige Liste der verfügbaren Argumente finden Sie auf der Seite [Konfiguration](/../usage/cfg.md).
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-seg.yaml') # ein neues Modell aus YAML erstellen
|
||||
model = YOLO('yolov8n-seg.pt') # ein vortrainiertes Modell laden (empfohlen für das Training)
|
||||
model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # aus YAML erstellen und Gewichte übertragen
|
||||
|
||||
# Das Modell trainieren
|
||||
results = model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Ein neues Modell aus YAML erstellen und das Training von vorne beginnen
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml epochs=100 imgsz=640
|
||||
|
||||
# Das Training von einem vortrainierten *.pt Modell aus starten
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
|
||||
# Ein neues Modell aus YAML erstellen, vortrainierte Gewichte darauf übertragen und das Training beginnen
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml pretrained=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### Datenformat
|
||||
|
||||
Das YOLO Segmentierungsdatenformat finden Sie detailliert im [Dataset Guide](../../../datasets/segment/index.md). Um Ihre vorhandenen Daten aus anderen Formaten (wie COCO usw.) in das YOLO-Format umzuwandeln, verwenden Sie bitte das [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO)-Tool von Ultralytics.
|
||||
|
||||
## Val
|
||||
|
||||
Validieren Sie die Genauigkeit des trainierten YOLOv8n-seg-Modells auf dem COCO128-seg-Datensatz. Es müssen keine Argumente übergeben werden, da das `Modell` seine Trainingsdaten und -argumente als Modellattribute behält.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-seg.pt') # offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # benutzerdefiniertes Modell laden
|
||||
|
||||
# Das Modell validieren
|
||||
metrics = model.val() # Keine Argumente erforderlich, Datensatz und Einstellungen werden behalten
|
||||
metrics.box.map # mAP50-95(B)
|
||||
metrics.box.map50 # mAP50(B)
|
||||
metrics.box.map75 # mAP75(B)
|
||||
metrics.box.maps # eine Liste enthält mAP50-95(B) für jede Kategorie
|
||||
metrics.seg.map # mAP50-95(M)
|
||||
metrics.seg.map50 # mAP50(M)
|
||||
metrics.seg.map75 # mAP75(M)
|
||||
metrics.seg.maps # eine Liste enthält mAP50-95(M) für jede Kategorie
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo segment val model=yolov8n-seg.pt # offizielles Modell validieren
|
||||
yolo segment val model=pfad/zu/best.pt # benutzerdefiniertes Modell validieren
|
||||
```
|
||||
|
||||
## Predict
|
||||
|
||||
Verwenden Sie ein trainiertes YOLOv8n-seg-Modell für Vorhersagen auf Bildern.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-seg.pt') # offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # benutzerdefiniertes Modell laden
|
||||
|
||||
# Mit dem Modell Vorhersagen treffen
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # Vorhersage auf einem Bild
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' # Vorhersage mit offiziellem Modell treffen
|
||||
yolo segment predict model=pfad/zu/best.pt source='https://ultralytics.com/images/bus.jpg' # Vorhersage mit benutzerdefiniertem Modell treffen
|
||||
```
|
||||
|
||||
Die vollständigen Details zum `predict`-Modus finden Sie auf der Seite [Predict](https://docs.ultralytics.com/modes/predict/).
|
||||
|
||||
## Export
|
||||
|
||||
Exportieren Sie ein YOLOv8n-seg-Modell in ein anderes Format wie ONNX, CoreML usw.
|
||||
|
||||
!!! Example "Beispiel"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Modell laden
|
||||
model = YOLO('yolov8n-seg.pt') # offizielles Modell laden
|
||||
model = YOLO('pfad/zu/best.pt') # benutzerdefiniertes trainiertes Modell laden
|
||||
|
||||
# Das Modell exportieren
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-seg.pt format=onnx # offizielles Modell exportieren
|
||||
yolo export model=pfad/zu/best.pt format=onnx # benutzerdefiniertes trainiertes Modell exportieren
|
||||
```
|
||||
|
||||
Die verfügbaren YOLOv8-seg-Exportformate sind in der folgenden Tabelle aufgeführt. Sie können direkt auf exportierten Modellen Vorhersagen treffen oder sie validieren, z.B. `yolo predict model=yolov8n-seg.onnx`. Verwendungsbeispiele werden für Ihr Modell nach dem Export angezeigt.
|
||||
|
||||
| Format | `format`-Argument | Modell | Metadaten | Argumente |
|
||||
|--------------------------------------------------------------------|-------------------|-------------------------------|-----------|-----------------------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-seg.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-seg.torchscript` | ✅ | `imgsz`, `optimieren` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-seg.onnx` | ✅ | `imgsz`, `halb`, `dynamisch`, `vereinfachen`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-seg_openvino_model/` | ✅ | `imgsz`, `halb` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-seg.engine` | ✅ | `imgsz`, `halb`, `dynamisch`, `vereinfachen`, `Arbeitsspeicher` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-seg.mlpackage` | ✅ | `imgsz`, `halb`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-seg_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-seg.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-seg.tflite` | ✅ | `imgsz`, `halb`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-seg_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-seg_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-seg_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-seg_ncnn_model/` | ✅ | `imgsz`, `halb` |
|
||||
|
||||
Die vollständigen Details zum `export` finden Sie auf der Seite [Export](https://docs.ultralytics.com/modes/export/).
|
||||
|
|
@ -1 +0,0 @@
|
|||
docs.ultralytics.com
|
||||
|
|
@ -1,152 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Step-by-step Quickstart Guide to Running YOLOv8 Object Detection Models on AzureML for Fast Prototyping and Testing
|
||||
keywords: Ultralytics, YOLOv8, Object Detection, Azure Machine Learning, Quickstart Guide, Prototype, Compute Instance, Terminal, Notebook, IPython Kernel, CLI, Python SDK
|
||||
---
|
||||
|
||||
# YOLOv8 🚀 on AzureML
|
||||
|
||||
## What is Azure?
|
||||
|
||||
[Azure](https://azure.microsoft.com/) is Microsoft's cloud computing platform, designed to help organizations move their workloads to the cloud from on-premises data centers. With the full spectrum of cloud services including those for computing, databases, analytics, machine learning, and networking, users can pick and choose from these services to develop and scale new applications, or run existing applications, in the public cloud.
|
||||
|
||||
## What is Azure Machine Learning (AzureML)?
|
||||
|
||||
Azure Machine Learning, commonly referred to as AzureML, is a fully managed cloud service that enables data scientists and developers to efficiently embed predictive analytics into their applications, helping organizations use massive data sets and bring all the benefits of the cloud to machine learning. AzureML offers a variety of services and capabilities aimed at making machine learning accessible, easy to use, and scalable. It provides capabilities like automated machine learning, drag-and-drop model training, as well as a robust Python SDK so that developers can make the most out of their machine learning models.
|
||||
|
||||
## How Does AzureML Benefit YOLO Users?
|
||||
|
||||
For users of YOLO (You Only Look Once), AzureML provides a robust, scalable, and efficient platform to both train and deploy machine learning models. Whether you are looking to run quick prototypes or scale up to handle more extensive data, AzureML's flexible and user-friendly environment offers various tools and services to fit your needs. You can leverage AzureML to:
|
||||
|
||||
- Easily manage large datasets and computational resources for training.
|
||||
- Utilize built-in tools for data preprocessing, feature selection, and model training.
|
||||
- Collaborate more efficiently with capabilities for MLOps (Machine Learning Operations), including but not limited to monitoring, auditing, and versioning of models and data.
|
||||
|
||||
In the subsequent sections, you will find a quickstart guide detailing how to run YOLOv8 object detection models using AzureML, either from a compute terminal or a notebook.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before you can get started, make sure you have access to an AzureML workspace. If you don't have one, you can create a new [AzureML workspace](https://learn.microsoft.com/azure/machine-learning/concept-workspace?view=azureml-api-2) by following Azure's official documentation. This workspace acts as a centralized place to manage all AzureML resources.
|
||||
|
||||
## Create a compute instance
|
||||
|
||||
From your AzureML workspace, select Compute > Compute instances > New, select the instance with the resources you need.
|
||||
|
||||
<p align="center">
|
||||
<img width="1280" src="https://github.com/ouphi/ultralytics/assets/17216799/3e92fcc0-a08e-41a4-af81-d289cfe3b8f2" alt="Create Azure Compute Instance">
|
||||
</p>
|
||||
|
||||
## Quickstart from Terminal
|
||||
|
||||
Start your compute and open a Terminal:
|
||||
|
||||
<p align="center">
|
||||
<img width="480" src="https://github.com/ouphi/ultralytics/assets/17216799/635152f1-f4a3-4261-b111-d416cb5ef357" alt="Open Terminal">
|
||||
</p>
|
||||
|
||||
### Create virtualenv
|
||||
|
||||
Create your conda virtualenv and install pip in it:
|
||||
|
||||
```bash
|
||||
conda create --name yolov8env -y
|
||||
conda activate yolov8env
|
||||
conda install pip -y
|
||||
```
|
||||
|
||||
Install the required dependencies:
|
||||
|
||||
```bash
|
||||
cd ultralytics
|
||||
pip install -r requirements.txt
|
||||
pip install ultralytics
|
||||
pip install onnx>=1.12.0
|
||||
```
|
||||
|
||||
### Perform YOLOv8 tasks
|
||||
|
||||
Predict:
|
||||
|
||||
```bash
|
||||
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
|
||||
```
|
||||
|
||||
Train a detection model for 10 epochs with an initial learning_rate of 0.01:
|
||||
|
||||
```bash
|
||||
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||
```
|
||||
|
||||
You can find more [instructions to use the Ultralytics CLI here](../quickstart.md#use-ultralytics-with-cli).
|
||||
|
||||
## Quickstart from a Notebook
|
||||
|
||||
### Create a new IPython kernel
|
||||
|
||||
Open the compute Terminal.
|
||||
|
||||
<p align="center">
|
||||
<img width="480" src="https://github.com/ouphi/ultralytics/assets/17216799/635152f1-f4a3-4261-b111-d416cb5ef357" alt="Open Terminal">
|
||||
</p>
|
||||
|
||||
From your compute terminal, you need to create a new ipykernel that will be used by your notebook to manage your dependencies:
|
||||
|
||||
```bash
|
||||
conda create --name yolov8env -y
|
||||
conda activate yolov8env
|
||||
conda install pip -y
|
||||
conda install ipykernel -y
|
||||
python -m ipykernel install --user --name yolov8env --display-name "yolov8env"
|
||||
```
|
||||
|
||||
Close your terminal and create a new notebook. From your Notebook, you can select the new kernel.
|
||||
|
||||
Then you can open a Notebook cell and install the required dependencies:
|
||||
|
||||
```bash
|
||||
%%bash
|
||||
source activate yolov8env
|
||||
cd ultralytics
|
||||
pip install -r requirements.txt
|
||||
pip install ultralytics
|
||||
pip install onnx>=1.12.0
|
||||
```
|
||||
|
||||
Note that we need to use the `source activate yolov8env` for all the %%bash cells, to make sure that the %%bash cell uses environment we want.
|
||||
|
||||
Run some predictions using the [Ultralytics CLI](../quickstart.md#use-ultralytics-with-cli):
|
||||
|
||||
```bash
|
||||
%%bash
|
||||
source activate yolov8env
|
||||
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
|
||||
```
|
||||
|
||||
Or with the [Ultralytics Python interface](../quickstart.md#use-ultralytics-with-python), for example to train the model:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO("yolov8n.pt") # load an official YOLOv8n model
|
||||
|
||||
# Use the model
|
||||
model.train(data="coco128.yaml", epochs=3) # train the model
|
||||
metrics = model.val() # evaluate model performance on the validation set
|
||||
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
|
||||
path = model.export(format="onnx") # export the model to ONNX format
|
||||
```
|
||||
|
||||
You can use either the Ultralytics CLI or Python interface for running YOLOv8 tasks, as described in the terminal section above.
|
||||
|
||||
By following these steps, you should be able to get YOLOv8 running quickly on AzureML for quick trials. For more advanced uses, you may refer to the full AzureML documentation linked at the beginning of this guide.
|
||||
|
||||
## Explore More with AzureML
|
||||
|
||||
This guide serves as an introduction to get you up and running with YOLOv8 on AzureML. However, it only scratches the surface of what AzureML can offer. To delve deeper and unlock the full potential of AzureML for your machine learning projects, consider exploring the following resources:
|
||||
|
||||
- [Create a Data Asset](https://learn.microsoft.com/azure/machine-learning/how-to-create-data-assets): Learn how to set up and manage your data assets effectively within the AzureML environment.
|
||||
- [Initiate an AzureML Job](https://learn.microsoft.com/azure/machine-learning/how-to-train-model): Get a comprehensive understanding of how to kickstart your machine learning training jobs on AzureML.
|
||||
- [Register a Model](https://learn.microsoft.com/azure/machine-learning/how-to-manage-models): Familiarize yourself with model management practices including registration, versioning, and deployment.
|
||||
- [Train YOLOv8 with AzureML Python SDK](https://medium.com/@ouphi/how-to-train-the-yolov8-model-with-azure-machine-learning-python-sdk-8268696be8ba): Explore a step-by-step guide on using the AzureML Python SDK to train your YOLOv8 models.
|
||||
- [Train YOLOv8 with AzureML CLI](https://medium.com/@ouphi/how-to-train-the-yolov8-model-with-azureml-and-the-az-cli-73d3c870ba8e): Discover how to utilize the command-line interface for streamlined training and management of YOLOv8 models on AzureML.
|
||||
|
|
@ -1,132 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Comprehensive guide to setting up and using Ultralytics YOLO models in a Conda environment. Learn how to install the package, manage dependencies, and get started with object detection projects.
|
||||
keywords: Ultralytics, YOLO, Conda, environment setup, object detection, package installation, deep learning, machine learning, guide
|
||||
---
|
||||
|
||||
# Conda Quickstart Guide for Ultralytics
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/266324397-32119e21-8c86-43e5-a00e-79827d303d10.png" alt="Ultralytics Conda Package Visual">
|
||||
</p>
|
||||
|
||||
This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and machine learning endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
|
||||
|
||||
[](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics)
|
||||
|
||||
## What You Will Learn
|
||||
|
||||
- Setting up a Conda environment
|
||||
- Installing Ultralytics via Conda
|
||||
- Initializing Ultralytics in your environment
|
||||
- Using Ultralytics Docker images with Conda
|
||||
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You should have Anaconda or Miniconda installed on your system. If not, download and install it from [Anaconda](https://www.anaconda.com/) or [Miniconda](https://docs.conda.io/projects/miniconda/en/latest/).
|
||||
|
||||
---
|
||||
|
||||
## Setting up a Conda Environment
|
||||
|
||||
First, let's create a new Conda environment. Open your terminal and run the following command:
|
||||
|
||||
```bash
|
||||
conda create --name ultralytics-env python=3.8 -y
|
||||
```
|
||||
|
||||
Activate the new environment:
|
||||
|
||||
```bash
|
||||
conda activate ultralytics-env
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Installing Ultralytics
|
||||
|
||||
You can install the Ultralytics package from the conda-forge channel. Execute the following command:
|
||||
|
||||
```bash
|
||||
conda install -c conda-forge ultralytics
|
||||
```
|
||||
|
||||
### Note on CUDA Environment
|
||||
|
||||
If you're working in a CUDA-enabled environment, it's a good practice to install `ultralytics`, `pytorch`, and `pytorch-cuda` together to resolve any conflicts:
|
||||
|
||||
```bash
|
||||
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Using Ultralytics
|
||||
|
||||
With Ultralytics installed, you can now start using its robust features for object detection, instance segmentation, and more. For example, to predict an image, you can run:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt') # initialize model
|
||||
results = model('path/to/image.jpg') # perform inference
|
||||
results.show() # display results
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Ultralytics Conda Docker Image
|
||||
|
||||
If you prefer using Docker, Ultralytics offers Docker images with a Conda environment included. You can pull these images from [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics).
|
||||
|
||||
Pull the latest Ultralytics image:
|
||||
|
||||
```bash
|
||||
# Set image name as a variable
|
||||
t=ultralytics/ultralytics:latest-conda
|
||||
|
||||
# Pull the latest Ultralytics image from Docker Hub
|
||||
sudo docker pull $t
|
||||
```
|
||||
|
||||
Run the image:
|
||||
|
||||
```bash
|
||||
# Run the Ultralytics image in a container with GPU support
|
||||
sudo docker run -it --ipc=host --gpus all $t # all GPUs
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
Certainly, you can include the following section in your Conda guide to inform users about speeding up installation using `libmamba`:
|
||||
|
||||
---
|
||||
|
||||
## Speeding Up Installation with Libmamba
|
||||
|
||||
If you're looking to [speed up the package installation](https://www.anaconda.com/blog/a-faster-conda-for-a-growing-community) process in Conda, you can opt to use `libmamba`, a fast, cross-platform, and dependency-aware package manager that serves as an alternative solver to Conda's default.
|
||||
|
||||
### How to Enable Libmamba
|
||||
|
||||
To enable `libmamba` as the solver for Conda, you can perform the following steps:
|
||||
|
||||
1. First, install the `conda-libmamba-solver` package. This can be skipped if your Conda version is 4.11 or above, as `libmamba` is included by default.
|
||||
|
||||
```bash
|
||||
conda install conda-libmamba-solver
|
||||
```
|
||||
|
||||
2. Next, configure Conda to use `libmamba` as the solver:
|
||||
|
||||
```bash
|
||||
conda config --set solver libmamba
|
||||
```
|
||||
|
||||
And that's it! Your Conda installation will now use `libmamba` as the solver, which should result in a faster package installation process.
|
||||
|
||||
---
|
||||
|
||||
Congratulations! You have successfully set up a Conda environment, installed the Ultralytics package, and are now ready to explore its rich functionalities. Feel free to dive deeper into the [Ultralytics documentation](../index.md) for more advanced tutorials and examples.
|
||||
|
|
@ -1,119 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Complete guide to setting up and using Ultralytics YOLO models with Docker. Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers.
|
||||
keywords: Ultralytics, YOLO, Docker, GPU, containerization, object detection, package installation, deep learning, machine learning, guide
|
||||
---
|
||||
|
||||
# Docker Quickstart Guide for Ultralytics
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/270173601-fc7011bd-e67c-452f-a31a-aa047dcd2771.png" alt="Ultralytics Docker Package Visual">
|
||||
</p>
|
||||
|
||||
This guide serves as a comprehensive introduction to setting up a Docker environment for your Ultralytics projects. [Docker](https://docker.com/) is a platform for developing, shipping, and running applications in containers. It is particularly beneficial for ensuring that the software will always run the same, regardless of where it's deployed. For more details, visit the Ultralytics Docker repository on [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics).
|
||||
|
||||
[](https://hub.docker.com/r/ultralytics/ultralytics)
|
||||
|
||||
## What You Will Learn
|
||||
|
||||
- Setting up Docker with NVIDIA support
|
||||
- Installing Ultralytics Docker images
|
||||
- Running Ultralytics in a Docker container
|
||||
- Mounting local directories into the container
|
||||
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Make sure Docker is installed on your system. If not, you can download and install it from [Docker's website](https://www.docker.com/products/docker-desktop).
|
||||
- Ensure that your system has an NVIDIA GPU and NVIDIA drivers are installed.
|
||||
|
||||
---
|
||||
|
||||
## Setting up Docker with NVIDIA Support
|
||||
|
||||
First, verify that the NVIDIA drivers are properly installed by running:
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
### Installing NVIDIA Docker Runtime
|
||||
|
||||
Now, let's install the NVIDIA Docker runtime to enable GPU support in Docker containers:
|
||||
|
||||
```bash
|
||||
# Add NVIDIA package repositories
|
||||
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
|
||||
distribution=$(lsb_release -cs)
|
||||
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
|
||||
|
||||
# Install NVIDIA Docker runtime
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y nvidia-docker2
|
||||
|
||||
# Restart Docker service to apply changes
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
### Verify NVIDIA Runtime with Docker
|
||||
|
||||
Run `docker info | grep -i runtime` to ensure that `nvidia` appears in the list of runtimes:
|
||||
|
||||
```bash
|
||||
docker info | grep -i runtime
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Installing Ultralytics Docker Images
|
||||
|
||||
Ultralytics offers several Docker images optimized for various platforms and use-cases:
|
||||
|
||||
- **Dockerfile:** GPU image, ideal for training.
|
||||
- **Dockerfile-arm64:** For ARM64 architecture, suitable for devices like [Raspberry Pi](raspberry-pi.md).
|
||||
- **Dockerfile-cpu:** CPU-only version for inference and non-GPU environments.
|
||||
- **Dockerfile-jetson:** Optimized for NVIDIA Jetson devices.
|
||||
- **Dockerfile-python:** Minimal Python environment for lightweight applications.
|
||||
- **Dockerfile-conda:** Includes [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) and Ultralytics package installed via Conda.
|
||||
|
||||
To pull the latest image:
|
||||
|
||||
```bash
|
||||
# Set image name as a variable
|
||||
t=ultralytics/ultralytics:latest
|
||||
|
||||
# Pull the latest Ultralytics image from Docker Hub
|
||||
sudo docker pull $t
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Running Ultralytics in Docker Container
|
||||
|
||||
Here's how to execute the Ultralytics Docker container:
|
||||
|
||||
```bash
|
||||
# Run with all GPUs
|
||||
sudo docker run -it --ipc=host --gpus all $t
|
||||
|
||||
# Run specifying which GPUs to use
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
|
||||
```
|
||||
|
||||
The `-it` flag assigns a pseudo-TTY and keeps stdin open, allowing you to interact with the container. The `--ipc=host` flag enables sharing of host's IPC namespace, essential for sharing memory between processes. The `--gpus` flag allows the container to access the host's GPUs.
|
||||
|
||||
### Note on File Accessibility
|
||||
|
||||
To work with files on your local machine within the container, you can use Docker volumes:
|
||||
|
||||
```bash
|
||||
# Mount a local directory into the container
|
||||
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
|
||||
```
|
||||
|
||||
Replace `/path/on/host` with the directory path on your local machine and `/path/in/container` with the desired path inside the Docker container.
|
||||
|
||||
---
|
||||
|
||||
Congratulations! You're now set up to use Ultralytics with Docker and ready to take advantage of its powerful capabilities. For alternate installation methods, feel free to explore the [Ultralytics quickstart documentation](../quickstart.md).
|
||||
|
|
@ -1,206 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Dive into hyperparameter tuning in Ultralytics YOLO models. Learn how to optimize performance using the Tuner class and genetic evolution.
|
||||
keywords: Ultralytics, YOLO, Hyperparameter Tuning, Tuner Class, Genetic Evolution, Optimization
|
||||
---
|
||||
|
||||
# Ultralytics YOLO Hyperparameter Tuning Guide
|
||||
|
||||
## Introduction
|
||||
|
||||
Hyperparameter tuning is not just a one-time set-up but an iterative process aimed at optimizing the machine learning model's performance metrics, such as accuracy, precision, and recall. In the context of Ultralytics YOLO, these hyperparameters could range from learning rate to architectural details, such as the number of layers or types of activation functions used.
|
||||
|
||||
### What are Hyperparameters?
|
||||
|
||||
Hyperparameters are high-level, structural settings for the algorithm. They are set prior to the training phase and remain constant during it. Here are some commonly tuned hyperparameters in Ultralytics YOLO:
|
||||
|
||||
- **Learning Rate** `lr0`: Determines the step size at each iteration while moving towards a minimum in the loss function.
|
||||
- **Batch Size** `batch`: Number of images processed simultaneously in a forward pass.
|
||||
- **Number of Epochs** `epochs`: An epoch is one complete forward and backward pass of all the training examples.
|
||||
- **Architecture Specifics**: Such as channel counts, number of layers, types of activation functions, etc.
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://user-images.githubusercontent.com/26833433/263858934-4f109a2f-82d9-4d08-8bd6-6fd1ff520bcd.png" alt="Hyperparameter Tuning Visual">
|
||||
</p>
|
||||
|
||||
For a full list of augmentation hyperparameters used in YOLOv8 please refer to the [configurations page](../usage/cfg.md#augmentation).
|
||||
|
||||
### Genetic Evolution and Mutation
|
||||
|
||||
Ultralytics YOLO uses genetic algorithms to optimize hyperparameters. Genetic algorithms are inspired by the mechanism of natural selection and genetics.
|
||||
|
||||
- **Mutation**: In the context of Ultralytics YOLO, mutation helps in locally searching the hyperparameter space by applying small, random changes to existing hyperparameters, producing new candidates for evaluation.
|
||||
- **Crossover**: Although crossover is a popular genetic algorithm technique, it is not currently used in Ultralytics YOLO for hyperparameter tuning. The focus is mainly on mutation for generating new hyperparameter sets.
|
||||
|
||||
## Preparing for Hyperparameter Tuning
|
||||
|
||||
Before you begin the tuning process, it's important to:
|
||||
|
||||
1. **Identify the Metrics**: Determine the metrics you will use to evaluate the model's performance. This could be AP50, F1-score, or others.
|
||||
2. **Set the Tuning Budget**: Define how much computational resources you're willing to allocate. Hyperparameter tuning can be computationally intensive.
|
||||
|
||||
## Steps Involved
|
||||
|
||||
### Initialize Hyperparameters
|
||||
|
||||
Start with a reasonable set of initial hyperparameters. This could either be the default hyperparameters set by Ultralytics YOLO or something based on your domain knowledge or previous experiments.
|
||||
|
||||
### Mutate Hyperparameters
|
||||
|
||||
Use the `_mutate` method to produce a new set of hyperparameters based on the existing set.
|
||||
|
||||
### Train Model
|
||||
|
||||
Training is performed using the mutated set of hyperparameters. The training performance is then assessed.
|
||||
|
||||
### Evaluate Model
|
||||
|
||||
Use metrics like AP50, F1-score, or custom metrics to evaluate the model's performance.
|
||||
|
||||
### Log Results
|
||||
|
||||
It's crucial to log both the performance metrics and the corresponding hyperparameters for future reference.
|
||||
|
||||
### Repeat
|
||||
|
||||
The process is repeated until either the set number of iterations is reached or the performance metric is satisfactory.
|
||||
|
||||
## Usage Example
|
||||
|
||||
Here's how to use the `model.tune()` method to utilize the `Tuner` class for hyperparameter tuning of YOLOv8n on COCO8 for 30 epochs with an AdamW optimizer and skipping plotting, checkpointing and validation other than on final epoch for faster Tuning.
|
||||
|
||||
!!! Example
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Initialize the YOLO model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Tune hyperparameters on COCO8 for 30 epochs
|
||||
model.tune(data='coco8.yaml', epochs=30, iterations=300, optimizer='AdamW', plots=False, save=False, val=False)
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
After you've successfully completed the hyperparameter tuning process, you will obtain several files and directories that encapsulate the results of the tuning. The following describes each:
|
||||
|
||||
### File Structure
|
||||
|
||||
Here's what the directory structure of the results will look like. Training directories like `train1/` contain individual tuning iterations, i.e. one model trained with one set of hyperparameters. The `tune/` directory contains tuning results from all the individual model trainings:
|
||||
|
||||
```plaintext
|
||||
runs/
|
||||
└── detect/
|
||||
├── train1/
|
||||
├── train2/
|
||||
├── ...
|
||||
└── tune/
|
||||
├── best_hyperparameters.yaml
|
||||
├── best_fitness.png
|
||||
├── tune_results.csv
|
||||
├── tune_scatter_plots.png
|
||||
└── weights/
|
||||
├── last.pt
|
||||
└── best.pt
|
||||
```
|
||||
|
||||
### File Descriptions
|
||||
|
||||
#### best_hyperparameters.yaml
|
||||
|
||||
This YAML file contains the best-performing hyperparameters found during the tuning process. You can use this file to initialize future trainings with these optimized settings.
|
||||
|
||||
- **Format**: YAML
|
||||
- **Usage**: Hyperparameter results
|
||||
- **Example**:
|
||||
```yaml
|
||||
# 558/900 iterations complete ✅ (45536.81s)
|
||||
# Results saved to /usr/src/ultralytics/runs/detect/tune
|
||||
# Best fitness=0.64297 observed at iteration 498
|
||||
# Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
|
||||
# Best fitness model is /usr/src/ultralytics/runs/detect/train498
|
||||
# Best fitness hyperparameters are printed below.
|
||||
|
||||
lr0: 0.00269
|
||||
lrf: 0.00288
|
||||
momentum: 0.73375
|
||||
weight_decay: 0.00015
|
||||
warmup_epochs: 1.22935
|
||||
warmup_momentum: 0.1525
|
||||
box: 18.27875
|
||||
cls: 1.32899
|
||||
dfl: 0.56016
|
||||
hsv_h: 0.01148
|
||||
hsv_s: 0.53554
|
||||
hsv_v: 0.13636
|
||||
degrees: 0.0
|
||||
translate: 0.12431
|
||||
scale: 0.07643
|
||||
shear: 0.0
|
||||
perspective: 0.0
|
||||
flipud: 0.0
|
||||
fliplr: 0.08631
|
||||
mosaic: 0.42551
|
||||
mixup: 0.0
|
||||
copy_paste: 0.0
|
||||
```
|
||||
|
||||
#### best_fitness.png
|
||||
|
||||
This is a plot displaying fitness (typically a performance metric like AP50) against the number of iterations. It helps you visualize how well the genetic algorithm performed over time.
|
||||
|
||||
- **Format**: PNG
|
||||
- **Usage**: Performance visualization
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://user-images.githubusercontent.com/26833433/266847423-9d0aea13-d5c4-4771-b06e-0b817a498260.png" alt="Hyperparameter Tuning Fitness vs Iteration">
|
||||
</p>
|
||||
|
||||
#### tune_results.csv
|
||||
|
||||
A CSV file containing detailed results of each iteration during the tuning. Each row in the file represents one iteration, and it includes metrics like fitness score, precision, recall, as well as the hyperparameters used.
|
||||
|
||||
- **Format**: CSV
|
||||
- **Usage**: Per-iteration results tracking.
|
||||
- **Example**:
|
||||
```csv
|
||||
fitness,lr0,lrf,momentum,weight_decay,warmup_epochs,warmup_momentum,box,cls,dfl,hsv_h,hsv_s,hsv_v,degrees,translate,scale,shear,perspective,flipud,fliplr,mosaic,mixup,copy_paste
|
||||
0.05021,0.01,0.01,0.937,0.0005,3.0,0.8,7.5,0.5,1.5,0.015,0.7,0.4,0.0,0.1,0.5,0.0,0.0,0.0,0.5,1.0,0.0,0.0
|
||||
0.07217,0.01003,0.00967,0.93897,0.00049,2.79757,0.81075,7.5,0.50746,1.44826,0.01503,0.72948,0.40658,0.0,0.0987,0.4922,0.0,0.0,0.0,0.49729,1.0,0.0,0.0
|
||||
0.06584,0.01003,0.00855,0.91009,0.00073,3.42176,0.95,8.64301,0.54594,1.72261,0.01503,0.59179,0.40658,0.0,0.0987,0.46955,0.0,0.0,0.0,0.49729,0.80187,0.0,0.0
|
||||
```
|
||||
|
||||
#### tune_scatter_plots.png
|
||||
|
||||
This file contains scatter plots generated from `tune_results.csv`, helping you visualize relationships between different hyperparameters and performance metrics. Note that hyperparameters initialized to 0 will not be tuned, such as `degrees` and `shear` below.
|
||||
|
||||
- **Format**: PNG
|
||||
- **Usage**: Exploratory data analysis
|
||||
|
||||
<p align="center">
|
||||
<img width="1000" src="https://user-images.githubusercontent.com/26833433/266847488-ec382f3d-79bc-4087-a0e0-42fb8b62cad2.png" alt="Hyperparameter Tuning Scatter Plots">
|
||||
</p>
|
||||
|
||||
#### weights/
|
||||
|
||||
This directory contains the saved PyTorch models for the last and the best iterations during the hyperparameter tuning process.
|
||||
|
||||
- **`last.pt`**: The last.pt are the weights from the last epoch of training.
|
||||
- **`best.pt`**: The best.pt weights for the iteration that achieved the best fitness score.
|
||||
|
||||
Using these results, you can make more informed decisions for your future model trainings and analyses. Feel free to consult these artifacts to understand how well your model performed and how you might improve it further.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The hyperparameter tuning process in Ultralytics YOLO is simplified yet powerful, thanks to its genetic algorithm-based approach focused on mutation. Following the steps outlined in this guide will assist you in systematically tuning your model to achieve better performance.
|
||||
|
||||
### Further Reading
|
||||
|
||||
1. [Hyperparameter Optimization in Wikipedia](https://en.wikipedia.org/wiki/Hyperparameter_optimization)
|
||||
2. [YOLOv5 Hyperparameter Evolution Guide](../yolov5/tutorials/hyperparameter_evolution.md)
|
||||
3. [Efficient Hyperparameter Tuning with Ray Tune and YOLOv8](../integrations/ray-tune.md)
|
||||
|
||||
For deeper insights, you can explore the `Tuner` class source code and accompanying documentation. Should you have any questions, feature requests, or need further assistance, feel free to reach out to us on [GitHub](https://github.com/ultralytics/ultralytics/issues/new/choose) or [Discord](https://ultralytics.com/discord).
|
||||
|
|
@ -1,37 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: In-depth exploration of Ultralytics' YOLO. Learn about the YOLO object detection model, how to train it on custom data, multi-GPU training, exporting, predicting, deploying, and more.
|
||||
keywords: Ultralytics, YOLO, Deep Learning, Object detection, PyTorch, Tutorial, Multi-GPU training, Custom data training, SAHI, Tiled Inference
|
||||
---
|
||||
|
||||
# Comprehensive Tutorials to Ultralytics YOLO
|
||||
|
||||
Welcome to the Ultralytics' YOLO 🚀 Guides! Our comprehensive tutorials cover various aspects of the YOLO object detection model, ranging from training and prediction to deployment. Built on PyTorch, YOLO stands out for its exceptional speed and accuracy in real-time object detection tasks.
|
||||
|
||||
Whether you're a beginner or an expert in deep learning, our tutorials offer valuable insights into the implementation and optimization of YOLO for your computer vision projects. Let's dive in!
|
||||
|
||||
## Guides
|
||||
|
||||
Here's a compilation of in-depth guides to help you master different aspects of Ultralytics YOLO.
|
||||
|
||||
* [YOLO Common Issues](yolo-common-issues.md) ⭐ RECOMMENDED: Practical solutions and troubleshooting tips to the most frequently encountered issues when working with Ultralytics YOLO models.
|
||||
* [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and F1 score used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
|
||||
* [Model Deployment Options](model-deployment-options.md): Overview of YOLO model deployment formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
|
||||
* [K-Fold Cross Validation](kfold-cross-validation.md) 🚀 NEW: Learn how to improve model generalization using K-Fold cross-validation technique.
|
||||
* [Hyperparameter Tuning](hyperparameter-tuning.md) 🚀 NEW: Discover how to optimize your YOLO models by fine-tuning hyperparameters using the Tuner class and genetic evolution algorithms.
|
||||
* [SAHI Tiled Inference](sahi-tiled-inference.md) 🚀 NEW: Comprehensive guide on leveraging SAHI's sliced inference capabilities with YOLOv8 for object detection in high-resolution images.
|
||||
* [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure Machine Learning platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
|
||||
* [Conda Quickstart](conda-quickstart.md) 🚀 NEW: Step-by-step guide to setting up a [Conda](https://anaconda.org/conda-forge/ultralytics) environment for Ultralytics. Learn how to install and start using the Ultralytics package efficiently with Conda.
|
||||
* [Docker Quickstart](docker-quickstart.md) 🚀 NEW: Complete guide to setting up and using Ultralytics YOLO models with [Docker](https://hub.docker.com/r/ultralytics/ultralytics). Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers for consistent development and deployment.
|
||||
* [Raspberry Pi](raspberry-pi.md) 🚀 NEW: Quickstart tutorial to run YOLO models to the latest Raspberry Pi hardware.
|
||||
* [Triton Inference Server Integration](triton-inference-server.md) 🚀 NEW: Dive into the integration of Ultralytics YOLOv8 with NVIDIA's Triton Inference Server for scalable and efficient deep learning inference deployments.
|
||||
* [YOLO Thread-Safe Inference](yolo-thread-safe-inference.md) 🚀 NEW: Guidelines for performing inference with YOLO models in a thread-safe manner. Learn the importance of thread safety and best practices to prevent race conditions and ensure consistent predictions.
|
||||
* [Isolating Segmentation Objects](isolating-segmentation-objects.md) 🚀 NEW: Step-by-step recipe and explanation on how to extract and/or isolate objects from images using Ultralytics Segmentation.
|
||||
|
||||
## Contribute to Our Guides
|
||||
|
||||
We welcome contributions from the community! If you've mastered a particular aspect of Ultralytics YOLO that's not yet covered in our guides, we encourage you to share your expertise. Writing a guide is a great way to give back to the community and help us make our documentation more comprehensive and user-friendly.
|
||||
|
||||
To get started, please read our [Contributing Guide](../help/contributing.md) for guidelines on how to open up a Pull Request (PR) 🛠️. We look forward to your contributions!
|
||||
|
||||
Let's work together to make the Ultralytics YOLO ecosystem more robust and versatile 🙏!
|
||||
|
|
@ -1,319 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: A concise guide on isolating segmented objects using Ultralytics.
|
||||
keywords: Ultralytics, YOLO, segmentation, Python, object detection, inference, dataset, prediction, instance segmentation, contours, binary mask, object mask, image processing
|
||||
---
|
||||
|
||||
# Isolating Segmentation Objects
|
||||
|
||||
After performing the [Segment Task](../tasks/segment.md), it's sometimes desirable to extract the isolated objects from the inference results. This guide provides a generic recipe on how to accomplish this using the Ultralytics [Predict Mode](../modes/predict.md).
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/ultralytics/ultralytics/assets/62214284/1787d76b-ad5f-43f9-a39c-d45c9157f38a" alt="Example Isolated Object Segmentation">
|
||||
</p>
|
||||
|
||||
## Recipe Walk Through
|
||||
|
||||
1. Begin with the necessary imports
|
||||
|
||||
```py
|
||||
from pathlib import Path
|
||||
|
||||
import cv2 as cv
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
```
|
||||
|
||||
???+ tip "Ultralytics Install"
|
||||
|
||||
See the Ultralytics [Quickstart](../quickstart.md/#install-ultralytics) Installation section for a quick walkthrough on installing the required libraries.
|
||||
|
||||
---
|
||||
|
||||
1. Load a model and run `predict()` method on a source.
|
||||
|
||||
```py
|
||||
m = YOLO('yolov8n-seg.pt')
|
||||
res = m.predict()
|
||||
```
|
||||
|
||||
??? question "No Prediction Arguments?"
|
||||
|
||||
Without specifying a source, the example images from the library will be used:
|
||||
|
||||
```
|
||||
'ultralytics/assets/bus.jpg'
|
||||
'ultralytics/assets/zidane.jpg'
|
||||
```
|
||||
|
||||
This is helpful for rapid testing with the `predict()` method.
|
||||
|
||||
For additional information about Segmentation Models, visit the [Segment Task](../tasks/segment.md/#models) page. To learn more about `predict()` method, see [Predict Mode](../modes/predict.md) section of the Documentation.
|
||||
|
||||
---
|
||||
|
||||
1. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
|
||||
|
||||
``` { .py .annotate }
|
||||
# (2) Iterate detection results (helpful for multiple images)
|
||||
for r in res:
|
||||
img = np.copy(r.orig_img)
|
||||
img_name = Path(r.path).stem # source image base-name
|
||||
|
||||
# Iterate each object contour (multiple detections)
|
||||
for ci,c in enumerate(r):
|
||||
# (1) Get detection class name
|
||||
label = c.names[c.boxes.cls.tolist().pop()]
|
||||
|
||||
```
|
||||
|
||||
1. To learn more about working with detection results, see [Boxes Section for Predict Mode](../modes/predict.md/#boxes).
|
||||
2. To learn more about `predict()` results see [Working with Results for Predict Mode](../modes/predict.md/#working-with-results)
|
||||
|
||||
??? info "For-Loop"
|
||||
|
||||
A single image will only iterate the first loop once. A single image with only a single detection will iterate each loop _only_ once.
|
||||
|
||||
---
|
||||
|
||||
1. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
|
||||
|
||||
{ width="240", align="right" }
|
||||
``` { .py .annotate }
|
||||
# Create binary mask
|
||||
b_mask = np.zeros(img.shape[:2], np.uint8)
|
||||
|
||||
# (1) Extract contour result
|
||||
contour = c.masks.xy.pop()
|
||||
# (2) Changing the type
|
||||
contour = contour.astype(np.int32)
|
||||
# (3) Reshaping
|
||||
contour = contour.reshape(-1, 1, 2)
|
||||
|
||||
|
||||
# Draw contour onto mask
|
||||
_ = cv.drawContours(b_mask,
|
||||
[contour],
|
||||
-1,
|
||||
(255, 255, 255),
|
||||
cv.FILLED)
|
||||
|
||||
```
|
||||
|
||||
1. For more info on `c.masks.xy` see [Masks Section from Predict Mode](../modes/predict.md/#masks).
|
||||
|
||||
2. Here, the values are cast into `np.int32` for compatibility with `drawContours()` function from OpenCV.
|
||||
|
||||
3. The OpenCV `drawContours()` function expects contours to have a shape of `[N, 1, 2]` expand section below for more details.
|
||||
|
||||
<details>
|
||||
<summary> Expand to understand what is happening when defining the <code>contour</code> variable.</summary>
|
||||
<p>
|
||||
|
||||
- `c.masks.xy` :: Provides the coordinates of the mask contour points in the format `(x, y)`. For more details, refer to the [Masks Section from Predict Mode](../modes/predict.md/#masks).
|
||||
|
||||
- `.pop()` :: As `masks.xy` is a list containing a single element, this element is extracted using the `pop()` method.
|
||||
|
||||
- `.astype(np.int32)` :: Using `masks.xy` will return with a data type of `float32`, but this won't be compatible with the OpenCV `drawContours()` function, so this will change the data type to `int32` for compatibility.
|
||||
|
||||
- `.reshape(-1, 1, 2)` :: Reformats the data into the required shape of of `[N, 1, 2]` where `N` is the number of contour points, with each point represented by a single entry `1`, and the entry is composed of `2` values. The `-1` denotes that the number of values along this dimension is flexible.
|
||||
|
||||
</details>
|
||||
<p></p>
|
||||
<details>
|
||||
<summary> Expand for an explanation of the <code>drawContours()</code> configuration.</summary>
|
||||
<p>
|
||||
|
||||
- Encapsulating the `contour` variable within square brackets, `[contour]`, was found to effectively generate the desired contour mask during testing.
|
||||
|
||||
- The value `-1` specified for the `drawContours()` parameter instructs the function to draw all contours present in the image.
|
||||
|
||||
- The `tuple` `(255, 255, 255)` represents the color white, which is the desired color for drawing the contour in this binary mask.
|
||||
|
||||
- The addition of `cv.FILLED` will color all pixels enclosed by the contour boundary the same, in this case, all enclosed pixels will be white.
|
||||
|
||||
- See [OpenCV Documentation on `drawContours()`](https://docs.opencv.org/4.8.0/d6/d6e/group__imgproc__draw.html#ga746c0625f1781f1ffc9056259103edbc) for more information.
|
||||
|
||||
</details>
|
||||
<p></p>
|
||||
|
||||
---
|
||||
|
||||
1. Next the there are 2 options for how to move forward with the image from this point and a subsequent option for each.
|
||||
|
||||
### Object Isolation Options
|
||||
|
||||
!!! Example ""
|
||||
|
||||
=== "Black Background Pixels"
|
||||
|
||||
```py
|
||||
# Create 3-channel mask
|
||||
mask3ch = cv.cvtColor(b_mask, cv.COLOR_GRAY2BGR)
|
||||
|
||||
# Isolate object with binary mask
|
||||
isolated = cv.bitwise_and(mask3ch, img)
|
||||
|
||||
```
|
||||
|
||||
??? question "How does this work?"
|
||||
|
||||
- First, the binary mask is first converted from a single-channel image to a three-channel image. This conversion is necessary for the subsequent step where the mask and the original image are combined. Both images must have the same number of channels to be compatible with the blending operation.
|
||||
|
||||
- The original image and the three-channel binary mask are merged using the OpenCV function `bitwise_and()`. This operation retains <u>only</u> pixel values that are greater than zero `(> 0)` from both images. Since the mask pixels are greater than zero `(> 0)` <u>only</u> within the contour region, the pixels remaining from the original image are those that overlap with the contour.
|
||||
|
||||
### Isolate with Black Pixels: Sub-options
|
||||
|
||||
??? info "Full-size Image"
|
||||
|
||||
There are no additional steps required if keeping full size image.
|
||||
|
||||
<figure markdown>
|
||||
{ width=240 }
|
||||
<figcaption>Example full-size output</figcaption>
|
||||
</figure>
|
||||
|
||||
??? info "Cropped object Image"
|
||||
|
||||
Additional steps required to crop image to only include object region.
|
||||
|
||||
{ align="right" }
|
||||
``` { .py .annotate }
|
||||
# (1) Bounding box coordinates
|
||||
x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
|
||||
# Crop image to object region
|
||||
iso_crop = isolated[y1:y2, x1:x2]
|
||||
|
||||
```
|
||||
|
||||
1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
|
||||
|
||||
??? question "What does this code do?"
|
||||
|
||||
- The `c.boxes.xyxy.cpu().numpy()` call retrieves the bounding boxes as a NumPy array in the `xyxy` format, where `xmin`, `ymin`, `xmax`, and `ymax` represent the coordinates of the bounding box rectangle. See [Boxes Section from Predict Mode](../modes/predict.md/#boxes) for more details.
|
||||
|
||||
- The `squeeze()` operation removes any unnecessary dimensions from the NumPy array, ensuring it has the expected shape.
|
||||
|
||||
- Converting the coordinate values using `.astype(np.int32)` changes the box coordinates data type from `float32` to `int32`, making them compatible for image cropping using index slices.
|
||||
|
||||
- Finally, the bounding box region is cropped from the image using index slicing. The bounds are defined by the `[ymin:ymax, xmin:xmax]` coordinates of the detection bounding box.
|
||||
|
||||
=== "Transparent Background Pixels"
|
||||
|
||||
```py
|
||||
# Isolate object with transparent background (when saved as PNG)
|
||||
isolated = np.dstack([img, b_mask])
|
||||
|
||||
```
|
||||
|
||||
??? question "How does this work?"
|
||||
|
||||
- Using the NumPy `dstack()` function (array stacking along depth-axis) in conjunction with the binary mask generated, will create an image with four channels. This allows for all pixels outside of the object contour to be transparent when saving as a `PNG` file.
|
||||
|
||||
### Isolate with Transparent Pixels: Sub-options
|
||||
|
||||
??? info "Full-size Image"
|
||||
|
||||
There are no additional steps required if keeping full size image.
|
||||
|
||||
<figure markdown>
|
||||
{ width=240 }
|
||||
<figcaption>Example full-size output + transparent background</figcaption>
|
||||
</figure>
|
||||
|
||||
??? info "Cropped object Image"
|
||||
|
||||
Additional steps required to crop image to only include object region.
|
||||
|
||||
{ align="right" }
|
||||
``` { .py .annotate }
|
||||
# (1) Bounding box coordinates
|
||||
x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
|
||||
# Crop image to object region
|
||||
iso_crop = isolated[y1:y2, x1:x2]
|
||||
|
||||
```
|
||||
|
||||
1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
|
||||
|
||||
??? question "What does this code do?"
|
||||
|
||||
- When using `c.boxes.xyxy.cpu().numpy()`, the bounding boxes are returned as a NumPy array, using the `xyxy` box coordinates format, which correspond to the points `xmin, ymin, xmax, ymax` for the bounding box (rectangle), see [Boxes Section from Predict Mode](../modes/predict.md/#boxes) for more information.
|
||||
|
||||
- Adding `squeeze()` ensures that any extraneous dimensions are removed from the NumPy array.
|
||||
|
||||
- Converting the coordinate values using `.astype(np.int32)` changes the box coordinates data type from `float32` to `int32` which will be compatible when cropping the image using index slices.
|
||||
|
||||
- Finally the image region for the bounding box is cropped using index slicing, where the bounds are set using the `[ymin:ymax, xmin:xmax]` coordinates of the detection bounding box.
|
||||
|
||||
??? question "What if I want the cropped object **including** the background?"
|
||||
|
||||
This is a built in feature for the Ultralytics library. See the `save_crop` argument for [Predict Mode Inference Arguments](../modes/predict.md/#inference-arguments) for details.
|
||||
|
||||
---
|
||||
|
||||
1. <u>What to do next is entirely left to the you as the developer.</u> A basic example of one possible next step (saving the image to file for future use) is shown.
|
||||
|
||||
- **NOTE:** this step is optional and can be skipped if not required for your specific use case.
|
||||
|
||||
??? example "Example Final Step"
|
||||
|
||||
```py
|
||||
# Save isolated object to file
|
||||
_ = cv.imwrite(f'{img_name}_{label}-{ci}.png', iso_crop)
|
||||
```
|
||||
|
||||
- In this example, the `img_name` is the base-name of the source image file, `label` is the detected class-name, and `ci` is the index of the object detection (in case of multiple instances with the same class name).
|
||||
|
||||
## Full Example code
|
||||
|
||||
Here, all steps from the previous section are combined into a single block of code. For repeated use, it would be optimal to define a function to do some or all commands contained in the `for`-loops, but that is an exercise left to the reader.
|
||||
|
||||
``` { .py .annotate }
|
||||
from pathlib import Path
|
||||
|
||||
import cv2 as cv
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
|
||||
m = YOLO('yolov8n-seg.pt')#(4)!
|
||||
res = m.predict()#(3)!
|
||||
|
||||
# iterate detection results (5)
|
||||
for r in res:
|
||||
img = np.copy(r.orig_img)
|
||||
img_name = Path(r.path).stem
|
||||
|
||||
# iterate each object contour (6)
|
||||
for ci,c in enumerate(r):
|
||||
label = c.names[c.boxes.cls.tolist().pop()]
|
||||
|
||||
b_mask = np.zeros(img.shape[:2], np.uint8)
|
||||
|
||||
# Create contour mask (1)
|
||||
contour = c.masks.xy.pop().astype(np.int32).reshape(-1, 1, 2)
|
||||
_ = cv.drawContours(b_mask, [contour], -1, (255, 255, 255), cv.FILLED)
|
||||
|
||||
# Choose one:
|
||||
|
||||
# OPTION-1: Isolate object with black background
|
||||
mask3ch = cv.cvtColor(b_mask, cv.COLOR_GRAY2BGR)
|
||||
isolated = cv.bitwise_and(mask3ch, img)
|
||||
|
||||
# OPTION-2: Isolate object with transparent background (when saved as PNG)
|
||||
isolated = np.dstack([img, b_mask])
|
||||
|
||||
# OPTIONAL: detection crop (from either OPT1 or OPT2)
|
||||
x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
|
||||
iso_crop = isolated[y1:y2, x1:x2]
|
||||
|
||||
# TODO your actions go here (2)
|
||||
|
||||
```
|
||||
|
||||
1. The line populating `contour` is combined into a single line here, where it was split to multiple above.
|
||||
2. {==What goes here is up to you!==}
|
||||
3. See [Predict Mode](../modes/predict.md) for additional information.
|
||||
4. See [Segment Task](../tasks/segment.md/#models) for more information.
|
||||
5. Learn more about [Working with Results](../modes/predict.md/#working-with-results)
|
||||
6. Learn more about [Segmentation Mask Results](../modes/predict.md/#masks)
|
||||
|
|
@ -1,278 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: An in-depth guide demonstrating the implementation of K-Fold Cross Validation with the Ultralytics ecosystem for object detection datasets, leveraging Python, YOLO, and sklearn.
|
||||
keywords: K-Fold cross validation, Ultralytics, YOLO detection format, Python, sklearn, object detection
|
||||
---
|
||||
|
||||
# K-Fold Cross Validation with Ultralytics
|
||||
|
||||
## Introduction
|
||||
|
||||
This comprehensive guide illustrates the implementation of K-Fold Cross Validation for object detection datasets within the Ultralytics ecosystem. We'll leverage the YOLO detection format and key Python libraries such as sklearn, pandas, and PyYaml to guide you through the necessary setup, the process of generating feature vectors, and the execution of a K-Fold dataset split.
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/258589390-8d815058-ece8-48b9-a94e-0e1ab53ea0f6.png" alt="K-Fold Cross Validation Overview">
|
||||
</p>
|
||||
|
||||
Whether your project involves the Fruit Detection dataset or a custom data source, this tutorial aims to help you comprehend and apply K-Fold Cross Validation to bolster the reliability and robustness of your machine learning models. While we're applying `k=5` folds for this tutorial, keep in mind that the optimal number of folds can vary depending on your dataset and the specifics of your project.
|
||||
|
||||
Without further ado, let's dive in!
|
||||
|
||||
## Setup
|
||||
|
||||
- Your annotations should be in the [YOLO detection format](../datasets/detect/index.md).
|
||||
|
||||
- This guide assumes that annotation files are locally available.
|
||||
|
||||
- For our demonstration, we use the [Fruit Detection](https://www.kaggle.com/datasets/lakshaytyagi01/fruit-detection/code) dataset.
|
||||
- This dataset contains a total of 8479 images.
|
||||
- It includes 6 class labels, each with its total instance counts listed below.
|
||||
|
||||
| Class Label | Instance Count |
|
||||
|:------------|:--------------:|
|
||||
| Apple | 7049 |
|
||||
| Grapes | 7202 |
|
||||
| Pineapple | 1613 |
|
||||
| Orange | 15549 |
|
||||
| Banana | 3536 |
|
||||
| Watermelon | 1976 |
|
||||
|
||||
- Necessary Python packages include:
|
||||
|
||||
- `ultralytics`
|
||||
- `sklearn`
|
||||
- `pandas`
|
||||
- `pyyaml`
|
||||
|
||||
- This tutorial operates with `k=5` folds. However, you should determine the best number of folds for your specific dataset.
|
||||
|
||||
1. Initiate a new Python virtual environment (`venv`) for your project and activate it. Use `pip` (or your preferred package manager) to install:
|
||||
|
||||
- The Ultralytics library: `pip install -U ultralytics`. Alternatively, you can clone the official [repo](https://github.com/ultralytics/ultralytics).
|
||||
- Scikit-learn, pandas, and PyYAML: `pip install -U scikit-learn pandas pyyaml`.
|
||||
|
||||
2. Verify that your annotations are in the [YOLO detection format](../datasets/detect/index.md).
|
||||
|
||||
- For this tutorial, all annotation files are found in the `Fruit-Detection/labels` directory.
|
||||
|
||||
## Generating Feature Vectors for Object Detection Dataset
|
||||
|
||||
1. Start by creating a new Python file and import the required libraries.
|
||||
|
||||
```python
|
||||
import datetime
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from collections import Counter
|
||||
|
||||
import yaml
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from ultralytics import YOLO
|
||||
from sklearn.model_selection import KFold
|
||||
```
|
||||
|
||||
2. Proceed to retrieve all label files for your dataset.
|
||||
|
||||
```python
|
||||
dataset_path = Path('./Fruit-detection') # replace with 'path/to/dataset' for your custom data
|
||||
labels = sorted(dataset_path.rglob("*labels/*.txt")) # all data in 'labels'
|
||||
```
|
||||
|
||||
3. Now, read the contents of the dataset YAML file and extract the indices of the class labels.
|
||||
|
||||
```python
|
||||
yaml_file = 'path/to/data.yaml' # your data YAML with data directories and names dictionary
|
||||
with open(yaml_file, 'r', encoding="utf8") as y:
|
||||
classes = yaml.safe_load(y)['names']
|
||||
cls_idx = sorted(classes.keys())
|
||||
```
|
||||
|
||||
4. Initialize an empty `pandas` DataFrame.
|
||||
|
||||
```python
|
||||
indx = [l.stem for l in labels] # uses base filename as ID (no extension)
|
||||
labels_df = pd.DataFrame([], columns=cls_idx, index=indx)
|
||||
```
|
||||
|
||||
5. Count the instances of each class-label present in the annotation files.
|
||||
|
||||
```python
|
||||
for label in labels:
|
||||
lbl_counter = Counter()
|
||||
|
||||
with open(label,'r') as lf:
|
||||
lines = lf.readlines()
|
||||
|
||||
for l in lines:
|
||||
# classes for YOLO label uses integer at first position of each line
|
||||
lbl_counter[int(l.split(' ')[0])] += 1
|
||||
|
||||
labels_df.loc[label.stem] = lbl_counter
|
||||
|
||||
labels_df = labels_df.fillna(0.0) # replace `nan` values with `0.0`
|
||||
```
|
||||
|
||||
6. The following is a sample view of the populated DataFrame:
|
||||
|
||||
```pandas
|
||||
0 1 2 3 4 5
|
||||
'0000a16e4b057580_jpg.rf.00ab48988370f64f5ca8ea4...' 0.0 0.0 0.0 0.0 0.0 7.0
|
||||
'0000a16e4b057580_jpg.rf.7e6dce029fb67f01eb19aa7...' 0.0 0.0 0.0 0.0 0.0 7.0
|
||||
'0000a16e4b057580_jpg.rf.bc4d31cdcbe229dd022957a...' 0.0 0.0 0.0 0.0 0.0 7.0
|
||||
'00020ebf74c4881c_jpg.rf.508192a0a97aa6c4a3b6882...' 0.0 0.0 0.0 1.0 0.0 0.0
|
||||
'00020ebf74c4881c_jpg.rf.5af192a2254c8ecc4188a25...' 0.0 0.0 0.0 1.0 0.0 0.0
|
||||
... ... ... ... ... ... ...
|
||||
'ff4cd45896de38be_jpg.rf.c4b5e967ca10c7ced3b9e97...' 0.0 0.0 0.0 0.0 0.0 2.0
|
||||
'ff4cd45896de38be_jpg.rf.ea4c1d37d2884b3e3cbce08...' 0.0 0.0 0.0 0.0 0.0 2.0
|
||||
'ff5fd9c3c624b7dc_jpg.rf.bb519feaa36fc4bf630a033...' 1.0 0.0 0.0 0.0 0.0 0.0
|
||||
'ff5fd9c3c624b7dc_jpg.rf.f0751c9c3aa4519ea3c9d6a...' 1.0 0.0 0.0 0.0 0.0 0.0
|
||||
'fffe28b31f2a70d4_jpg.rf.7ea16bd637ba0711c53b540...' 0.0 6.0 0.0 0.0 0.0 0.0
|
||||
```
|
||||
|
||||
The rows index the label files, each corresponding to an image in your dataset, and the columns correspond to your class-label indices. Each row represents a pseudo feature-vector, with the count of each class-label present in your dataset. This data structure enables the application of K-Fold Cross Validation to an object detection dataset.
|
||||
|
||||
## K-Fold Dataset Split
|
||||
|
||||
1. Now we will use the `KFold` class from `sklearn.model_selection` to generate `k` splits of the dataset.
|
||||
|
||||
- Important:
|
||||
- Setting `shuffle=True` ensures a randomized distribution of classes in your splits.
|
||||
- By setting `random_state=M` where `M` is a chosen integer, you can obtain repeatable results.
|
||||
|
||||
```python
|
||||
ksplit = 5
|
||||
kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # setting random_state for repeatable results
|
||||
|
||||
kfolds = list(kf.split(labels_df))
|
||||
```
|
||||
|
||||
2. The dataset has now been split into `k` folds, each having a list of `train` and `val` indices. We will construct a DataFrame to display these results more clearly.
|
||||
|
||||
```python
|
||||
folds = [f'split_{n}' for n in range(1, ksplit + 1)]
|
||||
folds_df = pd.DataFrame(index=indx, columns=folds)
|
||||
|
||||
for idx, (train, val) in enumerate(kfolds, start=1):
|
||||
folds_df[f'split_{idx}'].loc[labels_df.iloc[train].index] = 'train'
|
||||
folds_df[f'split_{idx}'].loc[labels_df.iloc[val].index] = 'val'
|
||||
```
|
||||
|
||||
3. Now we will calculate the distribution of class labels for each fold as a ratio of the classes present in `val` to those present in `train`.
|
||||
|
||||
```python
|
||||
fold_lbl_distrb = pd.DataFrame(index=folds, columns=cls_idx)
|
||||
|
||||
for n, (train_indices, val_indices) in enumerate(kfolds, start=1):
|
||||
train_totals = labels_df.iloc[train_indices].sum()
|
||||
val_totals = labels_df.iloc[val_indices].sum()
|
||||
|
||||
# To avoid division by zero, we add a small value (1E-7) to the denominator
|
||||
ratio = val_totals / (train_totals + 1E-7)
|
||||
fold_lbl_distrb.loc[f'split_{n}'] = ratio
|
||||
```
|
||||
|
||||
The ideal scenario is for all class ratios to be reasonably similar for each split and across classes. This, however, will be subject to the specifics of your dataset.
|
||||
|
||||
4. Next, we create the directories and dataset YAML files for each split.
|
||||
|
||||
```python
|
||||
supported_extensions = ['.jpg', '.jpeg', '.png']
|
||||
|
||||
# Initialize an empty list to store image file paths
|
||||
images = []
|
||||
|
||||
# Loop through supported extensions and gather image files
|
||||
for ext in supported_extensions:
|
||||
images.extend(sorted((dataset_path / 'images').rglob(f"*{ext}")))
|
||||
|
||||
# Create the necessary directories and dataset YAML files (unchanged)
|
||||
save_path = Path(dataset_path / f'{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val')
|
||||
save_path.mkdir(parents=True, exist_ok=True)
|
||||
ds_yamls = []
|
||||
|
||||
for split in folds_df.columns:
|
||||
# Create directories
|
||||
split_dir = save_path / split
|
||||
split_dir.mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'train' / 'images').mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'train' / 'labels').mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'val' / 'images').mkdir(parents=True, exist_ok=True)
|
||||
(split_dir / 'val' / 'labels').mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# Create dataset YAML files
|
||||
dataset_yaml = split_dir / f'{split}_dataset.yaml'
|
||||
ds_yamls.append(dataset_yaml)
|
||||
|
||||
with open(dataset_yaml, 'w') as ds_y:
|
||||
yaml.safe_dump({
|
||||
'path': split_dir.as_posix(),
|
||||
'train': 'train',
|
||||
'val': 'val',
|
||||
'names': classes
|
||||
}, ds_y)
|
||||
```
|
||||
|
||||
5. Lastly, copy images and labels into the respective directory ('train' or 'val') for each split.
|
||||
|
||||
- __NOTE:__ The time required for this portion of the code will vary based on the size of your dataset and your system hardware.
|
||||
|
||||
```python
|
||||
for image, label in zip(images, labels):
|
||||
for split, k_split in folds_df.loc[image.stem].items():
|
||||
# Destination directory
|
||||
img_to_path = save_path / split / k_split / 'images'
|
||||
lbl_to_path = save_path / split / k_split / 'labels'
|
||||
|
||||
# Copy image and label files to new directory (SamefileError if file already exists)
|
||||
shutil.copy(image, img_to_path / image.name)
|
||||
shutil.copy(label, lbl_to_path / label.name)
|
||||
```
|
||||
|
||||
## Save Records (Optional)
|
||||
|
||||
Optionally, you can save the records of the K-Fold split and label distribution DataFrames as CSV files for future reference.
|
||||
|
||||
```python
|
||||
folds_df.to_csv(save_path / "kfold_datasplit.csv")
|
||||
fold_lbl_distrb.to_csv(save_path / "kfold_label_distribution.csv")
|
||||
```
|
||||
|
||||
## Train YOLO using K-Fold Data Splits
|
||||
|
||||
1. First, load the YOLO model.
|
||||
|
||||
```python
|
||||
weights_path = 'path/to/weights.pt'
|
||||
model = YOLO(weights_path, task='detect')
|
||||
```
|
||||
|
||||
2. Next, iterate over the dataset YAML files to run training. The results will be saved to a directory specified by the `project` and `name` arguments. By default, this directory is 'exp/runs#' where # is an integer index.
|
||||
|
||||
```python
|
||||
results = {}
|
||||
|
||||
# Define your additional arguments here
|
||||
batch = 16
|
||||
project = 'kfold_demo'
|
||||
epochs = 100
|
||||
|
||||
for k in range(ksplit):
|
||||
dataset_yaml = ds_yamls[k]
|
||||
model.train(data=dataset_yaml,epochs=epochs, batch=batch, project=project) # include any train arguments
|
||||
results[k] = model.metrics # save output metrics for further analysis
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this guide, we have explored the process of using K-Fold cross-validation for training the YOLO object detection model. We learned how to split our dataset into K partitions, ensuring a balanced class distribution across the different folds.
|
||||
|
||||
We also explored the procedure for creating report DataFrames to visualize the data splits and label distributions across these splits, providing us a clear insight into the structure of our training and validation sets.
|
||||
|
||||
Optionally, we saved our records for future reference, which could be particularly useful in large-scale projects or when troubleshooting model performance.
|
||||
|
||||
Finally, we implemented the actual model training using each split in a loop, saving our training results for further analysis and comparison.
|
||||
|
||||
This technique of K-Fold cross-validation is a robust way of making the most out of your available data, and it helps to ensure that your model performance is reliable and consistent across different data subsets. This results in a more generalizable and reliable model that is less likely to overfit to specific data patterns.
|
||||
|
||||
Remember that although we used YOLO in this guide, these steps are mostly transferable to other machine learning models. Understanding these steps allows you to apply cross-validation effectively in your own machine learning projects. Happy coding!
|
||||
|
|
@ -1,305 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: A guide to help determine which deployment option to choose for your YOLOv8 model, including essential considerations.
|
||||
keywords: YOLOv8, Deployment, PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, CoreML, TensorFlow, Export
|
||||
---
|
||||
|
||||
# Understanding YOLOv8’s Deployment Options
|
||||
|
||||
## Introduction
|
||||
|
||||
*Setting the Scene:* You've come a long way on your journey with YOLOv8. You've diligently collected data, meticulously annotated it, and put in the hours to train and rigorously evaluate your custom YOLOv8 model. Now, it’s time to put your model to work for your specific application, use case, or project. But there's a critical decision that stands before you: how to export and deploy your model effectively.
|
||||
|
||||
This guide walks you through YOLOv8’s deployment options and the essential factors to consider to choose the right option for your project.
|
||||
|
||||
## How to Select the Right Deployment Option for Your YOLOv8 Model
|
||||
|
||||
When it's time to deploy your YOLOv8 model, selecting a suitable export format is very important. As outlined in the [Ultralytics YOLOv8 Modes documentation](../modes/export.md#usage-examples), the model.export() function allows for converting your trained model into a variety of formats tailored to diverse environments and performance requirements.
|
||||
|
||||
The ideal format depends on your model's intended operational context, balancing speed, hardware constraints, and ease of integration. In the following section, we'll take a closer look at each export option, understanding when to choose each one.
|
||||
|
||||
### YOLOv8’s Deployment Options
|
||||
|
||||
Let’s walk through the different YOLOv8 deployment options. For a detailed walkthrough of the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
|
||||
|
||||
#### PyTorch
|
||||
|
||||
PyTorch is an open-source machine learning library widely used for applications in deep learning and artificial intelligence. It provides a high level of flexibility and speed, which has made it a favorite among researchers and developers.
|
||||
|
||||
- **Performance Benchmarks**: PyTorch is known for its ease of use and flexibility, which may result in a slight trade-off in raw performance when compared to other frameworks that are more specialized and optimized.
|
||||
|
||||
- **Compatibility and Integration**: Offers excellent compatibility with various data science and machine learning libraries in Python.
|
||||
|
||||
- **Community Support and Ecosystem**: One of the most vibrant communities, with extensive resources for learning and troubleshooting.
|
||||
|
||||
- **Case Studies**: Commonly used in research prototypes, many academic papers reference models deployed in PyTorch.
|
||||
|
||||
- **Maintenance and Updates**: Regular updates with active development and support for new features.
|
||||
|
||||
- **Security Considerations**: Regular patches for security issues, but security is largely dependent on the overall environment it’s deployed in.
|
||||
|
||||
- **Hardware Acceleration**: Supports CUDA for GPU acceleration, essential for speeding up model training and inference.
|
||||
|
||||
#### TorchScript
|
||||
|
||||
TorchScript extends PyTorch’s capabilities by allowing the exportation of models to be run in a C++ runtime environment. This makes it suitable for production environments where Python is unavailable.
|
||||
|
||||
- **Performance Benchmarks**: Can offer improved performance over native PyTorch, especially in production environments.
|
||||
|
||||
- **Compatibility and Integration**: Designed for seamless transition from PyTorch to C++ production environments, though some advanced features might not translate perfectly.
|
||||
|
||||
- **Community Support and Ecosystem**: Benefits from PyTorch’s large community but has a narrower scope of specialized developers.
|
||||
|
||||
- **Case Studies**: Widely used in industry settings where Python’s performance overhead is a bottleneck.
|
||||
|
||||
- **Maintenance and Updates**: Maintained alongside PyTorch with consistent updates.
|
||||
|
||||
- **Security Considerations**: Offers improved security by enabling the running of models in environments without full Python installations.
|
||||
|
||||
- **Hardware Acceleration**: Inherits PyTorch’s CUDA support, ensuring efficient GPU utilization.
|
||||
|
||||
#### ONNX
|
||||
|
||||
The Open Neural Network Exchange (ONNX) is a format that allows for model interoperability across different frameworks, which can be critical when deploying to various platforms.
|
||||
|
||||
- **Performance Benchmarks**: ONNX models may experience a variable performance depending on the specific runtime they are deployed on.
|
||||
|
||||
- **Compatibility and Integration**: High interoperability across multiple platforms and hardware due to its framework-agnostic nature.
|
||||
|
||||
- **Community Support and Ecosystem**: Supported by many organizations, leading to a broad ecosystem and a variety of tools for optimization.
|
||||
|
||||
- **Case Studies**: Frequently used to move models between different machine learning frameworks, demonstrating its flexibility.
|
||||
|
||||
- **Maintenance and Updates**: As an open standard, ONNX is regularly updated to support new operations and models.
|
||||
|
||||
- **Security Considerations**: As with any cross-platform tool, it's essential to ensure secure practices in the conversion and deployment pipeline.
|
||||
|
||||
- **Hardware Acceleration**: With ONNX Runtime, models can leverage various hardware optimizations.
|
||||
|
||||
#### OpenVINO
|
||||
|
||||
OpenVINO is an Intel toolkit designed to facilitate the deployment of deep learning models across Intel hardware, enhancing performance and speed.
|
||||
|
||||
- **Performance Benchmarks**: Specifically optimized for Intel CPUs, GPUs, and VPUs, offering significant performance boosts on compatible hardware.
|
||||
|
||||
- **Compatibility and Integration**: Works best within the Intel ecosystem but also supports a range of other platforms.
|
||||
|
||||
- **Community Support and Ecosystem**: Backed by Intel, with a solid user base especially in the computer vision domain.
|
||||
|
||||
- **Case Studies**: Often utilized in IoT and edge computing scenarios where Intel hardware is prevalent.
|
||||
|
||||
- **Maintenance and Updates**: Intel regularly updates OpenVINO to support the latest deep learning models and Intel hardware.
|
||||
|
||||
- **Security Considerations**: Provides robust security features suitable for deployment in sensitive applications.
|
||||
|
||||
- **Hardware Acceleration**: Tailored for acceleration on Intel hardware, leveraging dedicated instruction sets and hardware features.
|
||||
|
||||
For more details on deployment using OpenVINO, refer to the Ultralytics Integration documentation: [Intel OpenVINO Export](../integrations/openvino.md).
|
||||
|
||||
#### TensorRT
|
||||
|
||||
TensorRT is a high-performance deep learning inference optimizer and runtime from NVIDIA, ideal for applications needing speed and efficiency.
|
||||
|
||||
- **Performance Benchmarks**: Delivers top-tier performance on NVIDIA GPUs with support for high-speed inference.
|
||||
|
||||
- **Compatibility and Integration**: Best suited for NVIDIA hardware, with limited support outside this environment.
|
||||
|
||||
- **Community Support and Ecosystem**: Strong support network through NVIDIA’s developer forums and documentation.
|
||||
|
||||
- **Case Studies**: Widely adopted in industries requiring real-time inference on video and image data.
|
||||
|
||||
- **Maintenance and Updates**: NVIDIA maintains TensorRT with frequent updates to enhance performance and support new GPU architectures.
|
||||
|
||||
- **Security Considerations**: Like many NVIDIA products, it has a strong emphasis on security, but specifics depend on the deployment environment.
|
||||
|
||||
- **Hardware Acceleration**: Exclusively designed for NVIDIA GPUs, providing deep optimization and acceleration.
|
||||
|
||||
#### CoreML
|
||||
|
||||
CoreML is Apple’s machine learning framework, optimized for on-device performance in the Apple ecosystem, including iOS, macOS, watchOS, and tvOS.
|
||||
|
||||
- **Performance Benchmarks**: Optimized for on-device performance on Apple hardware with minimal battery usage.
|
||||
|
||||
- **Compatibility and Integration**: Exclusively for Apple's ecosystem, providing a streamlined workflow for iOS and macOS applications.
|
||||
|
||||
- **Community Support and Ecosystem**: Strong support from Apple and a dedicated developer community, with extensive documentation and tools.
|
||||
|
||||
- **Case Studies**: Commonly used in applications that require on-device machine learning capabilities on Apple products.
|
||||
|
||||
- **Maintenance and Updates**: Regularly updated by Apple to support the latest machine learning advancements and Apple hardware.
|
||||
|
||||
- **Security Considerations**: Benefits from Apple's focus on user privacy and data security.
|
||||
|
||||
- **Hardware Acceleration**: Takes full advantage of Apple's neural engine and GPU for accelerated machine learning tasks.
|
||||
|
||||
#### TF SavedModel
|
||||
|
||||
TF SavedModel is TensorFlow’s format for saving and serving machine learning models, particularly suited for scalable server environments.
|
||||
|
||||
- **Performance Benchmarks**: Offers scalable performance in server environments, especially when used with TensorFlow Serving.
|
||||
|
||||
- **Compatibility and Integration**: Wide compatibility across TensorFlow's ecosystem, including cloud and enterprise server deployments.
|
||||
|
||||
- **Community Support and Ecosystem**: Large community support due to TensorFlow's popularity, with a vast array of tools for deployment and optimization.
|
||||
|
||||
- **Case Studies**: Extensively used in production environments for serving deep learning models at scale.
|
||||
|
||||
- **Maintenance and Updates**: Supported by Google and the TensorFlow community, ensuring regular updates and new features.
|
||||
|
||||
- **Security Considerations**: Deployment using TensorFlow Serving includes robust security features for enterprise-grade applications.
|
||||
|
||||
- **Hardware Acceleration**: Supports various hardware accelerations through TensorFlow's backends.
|
||||
|
||||
#### TF GraphDef
|
||||
|
||||
TF GraphDef is a TensorFlow format that represents the model as a graph, which is beneficial for environments where a static computation graph is required.
|
||||
|
||||
- **Performance Benchmarks**: Provides stable performance for static computation graphs, with a focus on consistency and reliability.
|
||||
|
||||
- **Compatibility and Integration**: Easily integrates within TensorFlow's infrastructure but less flexible compared to SavedModel.
|
||||
|
||||
- **Community Support and Ecosystem**: Good support from TensorFlow's ecosystem, with many resources available for optimizing static graphs.
|
||||
|
||||
- **Case Studies**: Useful in scenarios where a static graph is necessary, such as in certain embedded systems.
|
||||
|
||||
- **Maintenance and Updates**: Regular updates alongside TensorFlow's core updates.
|
||||
|
||||
- **Security Considerations**: Ensures safe deployment with TensorFlow's established security practices.
|
||||
|
||||
- **Hardware Acceleration**: Can utilize TensorFlow's hardware acceleration options, though not as flexible as SavedModel.
|
||||
|
||||
#### TF Lite
|
||||
|
||||
TF Lite is TensorFlow’s solution for mobile and embedded device machine learning, providing a lightweight library for on-device inference.
|
||||
|
||||
- **Performance Benchmarks**: Designed for speed and efficiency on mobile and embedded devices.
|
||||
|
||||
- **Compatibility and Integration**: Can be used on a wide range of devices due to its lightweight nature.
|
||||
|
||||
- **Community Support and Ecosystem**: Backed by Google, it has a robust community and a growing number of resources for developers.
|
||||
|
||||
- **Case Studies**: Popular in mobile applications that require on-device inference with minimal footprint.
|
||||
|
||||
- **Maintenance and Updates**: Regularly updated to include the latest features and optimizations for mobile devices.
|
||||
|
||||
- **Security Considerations**: Provides a secure environment for running models on end-user devices.
|
||||
|
||||
- **Hardware Acceleration**: Supports a variety of hardware acceleration options, including GPU and DSP.
|
||||
|
||||
#### TF Edge TPU
|
||||
|
||||
TF Edge TPU is designed for high-speed, efficient computing on Google's Edge TPU hardware, perfect for IoT devices requiring real-time processing.
|
||||
|
||||
- **Performance Benchmarks**: Specifically optimized for high-speed, efficient computing on Google's Edge TPU hardware.
|
||||
|
||||
- **Compatibility and Integration**: Works exclusively with TensorFlow Lite models on Edge TPU devices.
|
||||
|
||||
- **Community Support and Ecosystem**: Growing support with resources provided by Google and third-party developers.
|
||||
|
||||
- **Case Studies**: Used in IoT devices and applications that require real-time processing with low latency.
|
||||
|
||||
- **Maintenance and Updates**: Continually improved upon to leverage the capabilities of new Edge TPU hardware releases.
|
||||
|
||||
- **Security Considerations**: Integrates with Google's robust security for IoT and edge devices.
|
||||
|
||||
- **Hardware Acceleration**: Custom-designed to take full advantage of Google Coral devices.
|
||||
|
||||
#### TF.js
|
||||
|
||||
TensorFlow.js (TF.js) is a library that brings machine learning capabilities directly to the browser, offering a new realm of possibilities for web developers and users alike. It allows for the integration of machine learning models in web applications without the need for back-end infrastructure.
|
||||
|
||||
- **Performance Benchmarks**: Enables machine learning directly in the browser with reasonable performance, depending on the client device.
|
||||
|
||||
- **Compatibility and Integration**: High compatibility with web technologies, allowing for easy integration into web applications.
|
||||
|
||||
- **Community Support and Ecosystem**: Support from a community of web and Node.js developers, with a variety of tools for deploying ML models in browsers.
|
||||
|
||||
- **Case Studies**: Ideal for interactive web applications that benefit from client-side machine learning without the need for server-side processing.
|
||||
|
||||
- **Maintenance and Updates**: Maintained by the TensorFlow team with contributions from the open-source community.
|
||||
|
||||
- **Security Considerations**: Runs within the browser's secure context, utilizing the security model of the web platform.
|
||||
|
||||
- **Hardware Acceleration**: Performance can be enhanced with web-based APIs that access hardware acceleration like WebGL.
|
||||
|
||||
#### PaddlePaddle
|
||||
|
||||
PaddlePaddle is an open-source deep learning framework developed by Baidu. It is designed to be both efficient for researchers and easy to use for developers. It's particularly popular in China and offers specialized support for Chinese language processing.
|
||||
|
||||
- **Performance Benchmarks**: Offers competitive performance with a focus on ease of use and scalability.
|
||||
|
||||
- **Compatibility and Integration**: Well-integrated within Baidu's ecosystem and supports a wide range of applications.
|
||||
|
||||
- **Community Support and Ecosystem**: While the community is smaller globally, it's rapidly growing, especially in China.
|
||||
|
||||
- **Case Studies**: Commonly used in Chinese markets and by developers looking for alternatives to other major frameworks.
|
||||
|
||||
- **Maintenance and Updates**: Regularly updated with a focus on serving Chinese language AI applications and services.
|
||||
|
||||
- **Security Considerations**: Emphasizes data privacy and security, catering to Chinese data governance standards.
|
||||
|
||||
- **Hardware Acceleration**: Supports various hardware accelerations, including Baidu's own Kunlun chips.
|
||||
|
||||
#### ncnn
|
||||
|
||||
ncnn is a high-performance neural network inference framework optimized for the mobile platform. It stands out for its lightweight nature and efficiency, making it particularly well-suited for mobile and embedded devices where resources are limited.
|
||||
|
||||
- **Performance Benchmarks**: Highly optimized for mobile platforms, offering efficient inference on ARM-based devices.
|
||||
|
||||
- **Compatibility and Integration**: Suitable for applications on mobile phones and embedded systems with ARM architecture.
|
||||
|
||||
- **Community Support and Ecosystem**: Supported by a niche but active community focused on mobile and embedded ML applications.
|
||||
|
||||
- **Case Studies**: Favoured for mobile applications where efficiency and speed are critical on Android and other ARM-based systems.
|
||||
|
||||
- **Maintenance and Updates**: Continuously improved to maintain high performance on a range of ARM devices.
|
||||
|
||||
- **Security Considerations**: Focuses on running locally on the device, leveraging the inherent security of on-device processing.
|
||||
|
||||
- **Hardware Acceleration**: Tailored for ARM CPUs and GPUs, with specific optimizations for these architectures.
|
||||
|
||||
## Comparative Analysis of YOLOv8 Deployment Options
|
||||
|
||||
The following table provides a snapshot of the various deployment options available for YOLOv8 models, helping you to assess which may best fit your project needs based on several critical criteria. For an in-depth look at each deployment option's format, please see the [Ultralytics documentation page on export formats](../modes/export.md#export-formats).
|
||||
|
||||
| Deployment Option | Performance Benchmarks | Compatibility and Integration | Community Support and Ecosystem | Case Studies | Maintenance and Updates | Security Considerations | Hardware Acceleration |
|
||||
|-------------------|-------------------------------------------------|------------------------------------------------|-----------------------------------------------|--------------------------------------------|---------------------------------------------|---------------------------------------------------|------------------------------------|
|
||||
| PyTorch | Good flexibility; may trade off raw performance | Excellent with Python libraries | Extensive resources and community | Research and prototypes | Regular, active development | Dependent on deployment environment | CUDA support for GPU acceleration |
|
||||
| TorchScript | Better for production than PyTorch | Smooth transition from PyTorch to C++ | Specialized but narrower than PyTorch | Industry where Python is a bottleneck | Consistent updates with PyTorch | Improved security without full Python | Inherits CUDA support from PyTorch |
|
||||
| ONNX | Variable depending on runtime | High across different frameworks | Broad ecosystem, supported by many orgs | Flexibility across ML frameworks | Regular updates for new operations | Ensure secure conversion and deployment practices | Various hardware optimizations |
|
||||
| OpenVINO | Optimized for Intel hardware | Best within Intel ecosystem | Solid in computer vision domain | IoT and edge with Intel hardware | Regular updates for Intel hardware | Robust features for sensitive applications | Tailored for Intel hardware |
|
||||
| TensorRT | Top-tier on NVIDIA GPUs | Best for NVIDIA hardware | Strong network through NVIDIA | Real-time video and image inference | Frequent updates for new GPUs | Emphasis on security | Designed for NVIDIA GPUs |
|
||||
| CoreML | Optimized for on-device Apple hardware | Exclusive to Apple ecosystem | Strong Apple and developer support | On-device ML on Apple products | Regular Apple updates | Focus on privacy and security | Apple neural engine and GPU |
|
||||
| TF SavedModel | Scalable in server environments | Wide compatibility in TensorFlow ecosystem | Large support due to TensorFlow popularity | Serving models at scale | Regular updates by Google and community | Robust features for enterprise | Various hardware accelerations |
|
||||
| TF GraphDef | Stable for static computation graphs | Integrates well with TensorFlow infrastructure | Resources for optimizing static graphs | Scenarios requiring static graphs | Updates alongside TensorFlow core | Established TensorFlow security practices | TensorFlow acceleration options |
|
||||
| TF Lite | Speed and efficiency on mobile/embedded | Wide range of device support | Robust community, Google backed | Mobile applications with minimal footprint | Latest features for mobile | Secure environment on end-user devices | GPU and DSP among others |
|
||||
| TF Edge TPU | Optimized for Google's Edge TPU hardware | Exclusive to Edge TPU devices | Growing with Google and third-party resources | IoT devices requiring real-time processing | Improvements for new Edge TPU hardware | Google's robust IoT security | Custom-designed for Google Coral |
|
||||
| TF.js | Reasonable in-browser performance | High with web technologies | Web and Node.js developers support | Interactive web applications | TensorFlow team and community contributions | Web platform security model | Enhanced with WebGL and other APIs |
|
||||
| PaddlePaddle | Competitive, easy to use and scalable | Baidu ecosystem, wide application support | Rapidly growing, especially in China | Chinese market and language processing | Focus on Chinese AI applications | Emphasizes data privacy and security | Including Baidu's Kunlun chips |
|
||||
| ncnn | Optimized for mobile ARM-based devices | Mobile and embedded ARM systems | Niche but active mobile/embedded ML community | Android and ARM systems efficiency | High performance maintenance on ARM | On-device security advantages | ARM CPUs and GPUs optimizations |
|
||||
|
||||
This comparative analysis gives you a high-level overview. For deployment, it's essential to consider the specific requirements and constraints of your project, and consult the detailed documentation and resources available for each option.
|
||||
|
||||
## Community and Support
|
||||
|
||||
When you're getting started with YOLOv8, having a helpful community and support can make a significant impact. Here's how to connect with others who share your interests and get the assistance you need.
|
||||
|
||||
### Engage with the Broader Community
|
||||
|
||||
- **GitHub Discussions:** The YOLOv8 repository on GitHub has a "Discussions" section where you can ask questions, report issues, and suggest improvements.
|
||||
|
||||
- **Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and developers.
|
||||
|
||||
### Official Documentation and Resources
|
||||
|
||||
- **Ultralytics YOLOv8 Docs:** The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
|
||||
|
||||
These resources will help you tackle challenges and stay updated on the latest trends and best practices in the YOLOv8 community.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this guide, we've explored the different deployment options for YOLOv8. We've also discussed the important factors to consider when making your choice. These options allow you to customize your model for various environments and performance requirements, making it suitable for real-world applications.
|
||||
|
||||
Don't forget that the YOLOv8 and Ultralytics community is a valuable source of help. Connect with other developers and experts to learn unique tips and solutions you might not find in regular documentation. Keep seeking knowledge, exploring new ideas, and sharing your experiences.
|
||||
|
||||
Happy deploying!
|
||||
|
|
@ -1,196 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Quick start guide to setting up YOLO on a Raspberry Pi with a Pi Camera using the libcamera stack. Detailed comparison between Raspberry Pi 3, 4 and 5 models.
|
||||
keywords: Ultralytics, YOLO, Raspberry Pi, Pi Camera, libcamera, quick start guide, Raspberry Pi 4 vs Raspberry Pi 5, YOLO on Raspberry Pi, hardware setup, machine learning, AI
|
||||
---
|
||||
|
||||
# Quick Start Guide: Raspberry Pi and Pi Camera with YOLOv5 and YOLOv8
|
||||
|
||||
This comprehensive guide aims to expedite your journey with YOLO object detection models on a [Raspberry Pi](https://www.raspberrypi.com/) using a [Pi Camera](https://www.raspberrypi.com/products/camera-module-v2/). Whether you're a student, hobbyist, or a professional, this guide is designed to get you up and running in less than 30 minutes. The instructions here are rigorously tested to minimize setup issues, allowing you to focus on utilizing YOLO for your specific projects.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/yul4gq_LrOI"
|
||||
title="Introducing Raspberry Pi 5" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Raspberry Pi 5 updates and improvements.
|
||||
</p>
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Raspberry Pi 3, 4 or 5
|
||||
- Pi Camera
|
||||
- 64-bit Raspberry Pi Operating System
|
||||
|
||||
Connect the Pi Camera to your Raspberry Pi via a CSI cable and install the 64-bit Raspberry Pi Operating System. Verify your camera with the following command:
|
||||
|
||||
```bash
|
||||
libcamera-hello
|
||||
```
|
||||
|
||||
You should see a video feed from your camera.
|
||||
|
||||
## Choose Your YOLO Version: YOLOv5 or YOLOv8
|
||||
|
||||
This guide offers you the flexibility to start with either [YOLOv5](https://github.com/ultralytics/yolov5) or [YOLOv8](https://github.com/ultralytics/ultralytics). Both versions have their unique advantages and use-cases. The choice is yours, but remember, the guide's aim is not just quick setup but also a robust foundation for your future work in object detection.
|
||||
|
||||
## Hardware Specifics: At a Glance
|
||||
|
||||
To assist you in making an informed hardware decision, we've summarized the key hardware specifics of Raspberry Pi 3, 4, and 5 in the table below:
|
||||
|
||||
| Feature | Raspberry Pi 3 | Raspberry Pi 4 | Raspberry Pi 5 |
|
||||
|----------------------------|------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------|----------------------------------------------------------------------|
|
||||
| **CPU** | 1.2GHz Quad-Core ARM Cortex-A53 | 1.5GHz Quad-core 64-bit ARM Cortex-A72 | 2.4GHz Quad-core 64-bit Arm Cortex-A76 |
|
||||
| **RAM** | 1GB LPDDR2 | 2GB, 4GB or 8GB LPDDR4 | *Details not yet available* |
|
||||
| **USB Ports** | 4 x USB 2.0 | 2 x USB 2.0, 2 x USB 3.0 | 2 x USB 3.0, 2 x USB 2.0 |
|
||||
| **Network** | Ethernet & Wi-Fi 802.11n | Gigabit Ethernet & Wi-Fi 802.11ac | Gigabit Ethernet with PoE+ support, Dual-band 802.11ac Wi-Fi® |
|
||||
| **Performance** | Slower, may require lighter YOLO models | Faster, can run complex YOLO models | *Details not yet available* |
|
||||
| **Power Requirement** | 2.5A power supply | 3.0A USB-C power supply | *Details not yet available* |
|
||||
| **Official Documentation** | [Link](https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2837/README.md) | [Link](https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2711/README.md) | [Link](https://www.raspberrypi.com/news/introducing-raspberry-pi-5/) |
|
||||
|
||||
Please make sure to follow the instructions specific to your Raspberry Pi model to ensure a smooth setup process.
|
||||
|
||||
## Quick Start with YOLOv5
|
||||
|
||||
This section outlines how to set up YOLOv5 on a Raspberry Pi with a Pi Camera. These steps are designed to be compatible with the libcamera camera stack introduced in Raspberry Pi OS Bullseye.
|
||||
|
||||
### Install Necessary Packages
|
||||
|
||||
1. Update the Raspberry Pi:
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade -y
|
||||
sudo apt-get autoremove -y
|
||||
```
|
||||
|
||||
2. Clone the YOLOv5 repository:
|
||||
|
||||
```bash
|
||||
cd ~
|
||||
git clone https://github.com/Ultralytics/yolov5.git
|
||||
```
|
||||
|
||||
3. Install the required dependencies:
|
||||
|
||||
```bash
|
||||
cd ~/yolov5
|
||||
pip3 install -r requirements.txt
|
||||
```
|
||||
|
||||
4. For Raspberry Pi 3, install compatible versions of PyTorch and Torchvision (skip for Raspberry Pi 4):
|
||||
|
||||
```bash
|
||||
pip3 uninstall torch torchvision
|
||||
pip3 install torch==1.11.0 torchvision==0.12.0
|
||||
```
|
||||
|
||||
### Modify `detect.py`
|
||||
|
||||
To enable TCP streams via SSH or the CLI, minor modifications are needed in `detect.py`.
|
||||
|
||||
1. Open `detect.py`:
|
||||
|
||||
```bash
|
||||
sudo nano ~/yolov5/detect.py
|
||||
```
|
||||
|
||||
2. Find and modify the `is_url` line to accept TCP streams:
|
||||
|
||||
```python
|
||||
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://', 'tcp://'))
|
||||
```
|
||||
|
||||
3. Comment out the `view_img` line:
|
||||
|
||||
```python
|
||||
# view_img = check_imshow(warn=True)
|
||||
```
|
||||
|
||||
4. Save and exit:
|
||||
|
||||
```bash
|
||||
CTRL + O -> ENTER -> CTRL + X
|
||||
```
|
||||
|
||||
### Initiate TCP Stream with Libcamera
|
||||
|
||||
1. Start the TCP stream:
|
||||
|
||||
```bash
|
||||
libcamera-vid -n -t 0 --width 1280 --height 960 --framerate 1 --inline --listen -o tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
Keep this terminal session running for the next steps.
|
||||
|
||||
### Perform YOLOv5 Inference
|
||||
|
||||
1. Run the YOLOv5 detection:
|
||||
|
||||
```bash
|
||||
cd ~/yolov5
|
||||
python3 detect.py --source=tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
## Quick Start with YOLOv8
|
||||
|
||||
Follow this section if you are interested in setting up YOLOv8 instead. The steps are quite similar but are tailored for YOLOv8's specific needs.
|
||||
|
||||
### Install Necessary Packages
|
||||
|
||||
1. Update the Raspberry Pi:
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade -y
|
||||
sudo apt-get autoremove -y
|
||||
```
|
||||
|
||||
2. Install the `ultralytics` Python package:
|
||||
|
||||
```bash
|
||||
pip3 install ultralytics
|
||||
```
|
||||
|
||||
3. Reboot:
|
||||
|
||||
```bash
|
||||
sudo reboot
|
||||
```
|
||||
|
||||
### Initiate TCP Stream with Libcamera
|
||||
|
||||
1. Start the TCP stream:
|
||||
|
||||
```bash
|
||||
libcamera-vid -n -t 0 --width 1280 --height 960 --framerate 1 --inline --listen -o tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
### Perform YOLOv8 Inference
|
||||
|
||||
To perform inference with YOLOv8, you can use the following Python code snippet:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model('tcp://127.0.0.1:8888', stream=True)
|
||||
|
||||
while True:
|
||||
for result in results:
|
||||
boxes = result.boxes
|
||||
probs = result.probs
|
||||
```
|
||||
|
||||
## Next Steps
|
||||
|
||||
Congratulations on successfully setting up YOLO on your Raspberry Pi! For further learning and support, visit [Ultralytics](https://ultralytics.com/) and [Kashmir World Foundation](https://www.kashmirworldfoundation.org/).
|
||||
|
||||
## Acknowledgements and Citations
|
||||
|
||||
This guide was initially created by Daan Eeltink for Kashmir World Foundation, an organization dedicated to the use of YOLO for the conservation of endangered species. We acknowledge their pioneering work and educational focus in the realm of object detection technologies.
|
||||
|
||||
For more information about Kashmir World Foundation's activities, you can visit their [website](https://www.kashmirworldfoundation.org/).
|
||||
|
|
@ -1,185 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: A comprehensive guide on how to use YOLOv8 with SAHI for standard and sliced inference in object detection tasks.
|
||||
keywords: YOLOv8, SAHI, Sliced Inference, Object Detection, Ultralytics, Large Scale Image Analysis, High-Resolution Imagery
|
||||
---
|
||||
|
||||
# Ultralytics Docs: Using YOLOv8 with SAHI for Sliced Inference
|
||||
|
||||
Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced object detection performance.
|
||||
|
||||
<p align="center">
|
||||
<img width="1024" src="https://raw.githubusercontent.com/obss/sahi/main/resources/sliced_inference.gif" alt="SAHI Sliced Inference Overview">
|
||||
</p>
|
||||
|
||||
## Introduction to SAHI
|
||||
|
||||
SAHI (Slicing Aided Hyper Inference) is an innovative library designed to optimize object detection algorithms for large-scale and high-resolution imagery. Its core functionality lies in partitioning images into manageable slices, running object detection on each slice, and then stitching the results back together. SAHI is compatible with a range of object detection models, including the YOLO series, thereby offering flexibility while ensuring optimized use of computational resources.
|
||||
|
||||
### Key Features of SAHI
|
||||
|
||||
- **Seamless Integration**: SAHI integrates effortlessly with YOLO models, meaning you can start slicing and detecting without a lot of code modification.
|
||||
- **Resource Efficiency**: By breaking down large images into smaller parts, SAHI optimizes the memory usage, allowing you to run high-quality detection on hardware with limited resources.
|
||||
- **High Accuracy**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
|
||||
|
||||
## What is Sliced Inference?
|
||||
|
||||
Sliced Inference refers to the practice of subdividing a large or high-resolution image into smaller segments (slices), conducting object detection on these slices, and then recompiling the slices to reconstruct the object locations on the original image. This technique is invaluable in scenarios where computational resources are limited or when working with extremely high-resolution images that could otherwise lead to memory issues.
|
||||
|
||||
### Benefits of Sliced Inference
|
||||
|
||||
- **Reduced Computational Burden**: Smaller image slices are faster to process, and they consume less memory, enabling smoother operation on lower-end hardware.
|
||||
|
||||
- **Preserved Detection Quality**: Since each slice is treated independently, there is no reduction in the quality of object detection, provided the slices are large enough to capture the objects of interest.
|
||||
|
||||
- **Enhanced Scalability**: The technique allows for object detection to be more easily scaled across different sizes and resolutions of images, making it ideal for a wide range of applications from satellite imagery to medical diagnostics.
|
||||
|
||||
<table border="0">
|
||||
<tr>
|
||||
<th>YOLOv8 without SAHI</th>
|
||||
<th>YOLOv8 with SAHI</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><img src="https://user-images.githubusercontent.com/26833433/266123241-260a9740-5998-4e9a-ad04-b39b7767e731.png" alt="YOLOv8 without SAHI" width="640"></td>
|
||||
<td><img src="https://user-images.githubusercontent.com/26833433/266123245-55f696ad-ec74-4e71-9155-c211d693bb69.png" alt="YOLOv8 with SAHI" width="640"></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Installation and Preparation
|
||||
|
||||
### Installation
|
||||
|
||||
To get started, install the latest versions of SAHI and Ultralytics:
|
||||
|
||||
```bash
|
||||
pip install -U ultralytics sahi
|
||||
```
|
||||
|
||||
### Import Modules and Download Resources
|
||||
|
||||
Here's how to import the necessary modules and download a YOLOv8 model and some test images:
|
||||
|
||||
```python
|
||||
from sahi.utils.yolov8 import download_yolov8s_model
|
||||
from sahi import AutoDetectionModel
|
||||
from sahi.utils.cv import read_image
|
||||
from sahi.utils.file import download_from_url
|
||||
from sahi.predict import get_prediction, get_sliced_prediction, predict
|
||||
from pathlib import Path
|
||||
from IPython.display import Image
|
||||
|
||||
# Download YOLOv8 model
|
||||
yolov8_model_path = "models/yolov8s.pt"
|
||||
download_yolov8s_model(yolov8_model_path)
|
||||
|
||||
# Download test images
|
||||
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg', 'demo_data/small-vehicles1.jpeg')
|
||||
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png', 'demo_data/terrain2.png')
|
||||
```
|
||||
|
||||
## Standard Inference with YOLOv8
|
||||
|
||||
### Instantiate the Model
|
||||
|
||||
You can instantiate a YOLOv8 model for object detection like this:
|
||||
|
||||
```python
|
||||
detection_model = AutoDetectionModel.from_pretrained(
|
||||
model_type='yolov8',
|
||||
model_path=yolov8_model_path,
|
||||
confidence_threshold=0.3,
|
||||
device="cpu", # or 'cuda:0'
|
||||
)
|
||||
```
|
||||
|
||||
### Perform Standard Prediction
|
||||
|
||||
Perform standard inference using an image path or a numpy image.
|
||||
|
||||
```python
|
||||
# With an image path
|
||||
result = get_prediction("demo_data/small-vehicles1.jpeg", detection_model)
|
||||
|
||||
# With a numpy image
|
||||
result = get_prediction(read_image("demo_data/small-vehicles1.jpeg"), detection_model)
|
||||
```
|
||||
|
||||
### Visualize Results
|
||||
|
||||
Export and visualize the predicted bounding boxes and masks:
|
||||
|
||||
```python
|
||||
result.export_visuals(export_dir="demo_data/")
|
||||
Image("demo_data/prediction_visual.png")
|
||||
```
|
||||
|
||||
## Sliced Inference with YOLOv8
|
||||
|
||||
Perform sliced inference by specifying the slice dimensions and overlap ratios:
|
||||
|
||||
```python
|
||||
result = get_sliced_prediction(
|
||||
"demo_data/small-vehicles1.jpeg",
|
||||
detection_model,
|
||||
slice_height=256,
|
||||
slice_width=256,
|
||||
overlap_height_ratio=0.2,
|
||||
overlap_width_ratio=0.2
|
||||
)
|
||||
```
|
||||
|
||||
## Handling Prediction Results
|
||||
|
||||
SAHI provides a `PredictionResult` object, which can be converted into various annotation formats:
|
||||
|
||||
```python
|
||||
# Access the object prediction list
|
||||
object_prediction_list = result.object_prediction_list
|
||||
|
||||
# Convert to COCO annotation, COCO prediction, imantics, and fiftyone formats
|
||||
result.to_coco_annotations()[:3]
|
||||
result.to_coco_predictions(image_id=1)[:3]
|
||||
result.to_imantics_annotations()[:3]
|
||||
result.to_fiftyone_detections()[:3]
|
||||
```
|
||||
|
||||
## Batch Prediction
|
||||
|
||||
For batch prediction on a directory of images:
|
||||
|
||||
```python
|
||||
predict(
|
||||
model_type="yolov8",
|
||||
model_path="path/to/yolov8n.pt",
|
||||
model_device="cpu", # or 'cuda:0'
|
||||
model_confidence_threshold=0.4,
|
||||
source="path/to/dir",
|
||||
slice_height=256,
|
||||
slice_width=256,
|
||||
overlap_height_ratio=0.2,
|
||||
overlap_width_ratio=0.2,
|
||||
)
|
||||
```
|
||||
|
||||
That's it! Now you're equipped to use YOLOv8 with SAHI for both standard and sliced inference.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use SAHI in your research or development work, please cite the original SAHI paper and acknowledge the authors:
|
||||
|
||||
!!! Quote ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{akyon2022sahi,
|
||||
title={Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection},
|
||||
author={Akyon, Fatih Cagatay and Altinuc, Sinan Onur and Temizel, Alptekin},
|
||||
journal={2022 IEEE International Conference on Image Processing (ICIP)},
|
||||
doi={10.1109/ICIP46576.2022.9897990},
|
||||
pages={966-970},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
|
||||
We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the computer vision community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
|
||||
|
|
@ -1,137 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: A step-by-step guide on integrating Ultralytics YOLOv8 with Triton Inference Server for scalable and high-performance deep learning inference deployments.
|
||||
keywords: YOLOv8, Triton Inference Server, ONNX, Deep Learning Deployment, Scalable Inference, Ultralytics, NVIDIA, Object Detection, Cloud Inferencing
|
||||
---
|
||||
|
||||
# Triton Inference Server with Ultralytics YOLOv8
|
||||
|
||||
The [Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server) (formerly known as TensorRT Inference Server) is an open-source software solution developed by NVIDIA. It provides a cloud inferencing solution optimized for NVIDIA GPUs. Triton simplifies the deployment of AI models at scale in production. Integrating Ultralytics YOLOv8 with Triton Inference Server allows you to deploy scalable, high-performance deep learning inference workloads. This guide provides steps to set up and test the integration.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/NQDtfSi5QF4"
|
||||
title="Getting Started with NVIDIA Triton Inference Server" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Getting Started with NVIDIA Triton Inference Server.
|
||||
</p>
|
||||
|
||||
## What is Triton Inference Server?
|
||||
|
||||
Triton Inference Server is designed to deploy a variety of AI models in production. It supports a wide range of deep learning and machine learning frameworks, including TensorFlow, PyTorch, ONNX Runtime, and many others. Its primary use cases are:
|
||||
|
||||
- Serving multiple models from a single server instance.
|
||||
- Dynamic model loading and unloading without server restart.
|
||||
- Ensemble inferencing, allowing multiple models to be used together to achieve results.
|
||||
- Model versioning for A/B testing and rolling updates.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Ensure you have the following prerequisites before proceeding:
|
||||
|
||||
- Docker installed on your machine.
|
||||
- Install `tritonclient`:
|
||||
```bash
|
||||
pip install tritonclient[all]
|
||||
```
|
||||
|
||||
## Exporting YOLOv8 to ONNX Format
|
||||
|
||||
Before deploying the model on Triton, it must be exported to the ONNX format. ONNX (Open Neural Network Exchange) is a format that allows models to be transferred between different deep learning frameworks. Use the `export` function from the `YOLO` class:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load an official model
|
||||
|
||||
# Export the model
|
||||
onnx_file = model.export(format='onnx', dynamic=True)
|
||||
```
|
||||
|
||||
## Setting Up Triton Model Repository
|
||||
|
||||
The Triton Model Repository is a storage location where Triton can access and load models.
|
||||
|
||||
1. Create the necessary directory structure:
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
||||
# Define paths
|
||||
triton_repo_path = Path('tmp') / 'triton_repo'
|
||||
triton_model_path = triton_repo_path / 'yolo'
|
||||
|
||||
# Create directories
|
||||
(triton_model_path / '1').mkdir(parents=True, exist_ok=True)
|
||||
```
|
||||
|
||||
2. Move the exported ONNX model to the Triton repository:
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
||||
# Move ONNX model to Triton Model path
|
||||
Path(onnx_file).rename(triton_model_path / '1' / 'model.onnx')
|
||||
|
||||
# Create config file
|
||||
(triton_model_path / 'config.pbtxt').touch()
|
||||
```
|
||||
|
||||
## Running Triton Inference Server
|
||||
|
||||
Run the Triton Inference Server using Docker:
|
||||
|
||||
```python
|
||||
import subprocess
|
||||
import time
|
||||
|
||||
from tritonclient.http import InferenceServerClient
|
||||
|
||||
# Define image https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver
|
||||
tag = 'nvcr.io/nvidia/tritonserver:23.09-py3' # 6.4 GB
|
||||
|
||||
# Pull the image
|
||||
subprocess.call(f'docker pull {tag}', shell=True)
|
||||
|
||||
# Run the Triton server and capture the container ID
|
||||
container_id = subprocess.check_output(
|
||||
f'docker run -d --rm -v {triton_repo_path}:/models -p 8000:8000 {tag} tritonserver --model-repository=/models',
|
||||
shell=True).decode('utf-8').strip()
|
||||
|
||||
# Wait for the Triton server to start
|
||||
triton_client = InferenceServerClient(url='localhost:8000', verbose=False, ssl=False)
|
||||
|
||||
# Wait until model is ready
|
||||
for _ in range(10):
|
||||
with contextlib.suppress(Exception):
|
||||
assert triton_client.is_model_ready(model_name)
|
||||
break
|
||||
time.sleep(1)
|
||||
```
|
||||
|
||||
Then run inference using the Triton Server model:
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load the Triton Server model
|
||||
model = YOLO(f'http://localhost:8000/yolo', task='detect')
|
||||
|
||||
# Run inference on the server
|
||||
results = model('path/to/image.jpg')
|
||||
```
|
||||
|
||||
Cleanup the container:
|
||||
|
||||
```python
|
||||
# Kill and remove the container at the end of the test
|
||||
subprocess.call(f'docker kill {container_id}', shell=True)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
By following the above steps, you can deploy and run Ultralytics YOLOv8 models efficiently on Triton Inference Server, providing a scalable and high-performance solution for deep learning inference tasks. If you face any issues or have further queries, refer to the [official Triton documentation](https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.html) or reach out to the Ultralytics community for support.
|
||||
|
|
@ -1,276 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: A comprehensive guide to troubleshooting common issues encountered while working with YOLOv8 in the Ultralytics ecosystem.
|
||||
keywords: Troubleshooting, Ultralytics, YOLOv8, Installation Errors, Training Data, Model Performance, Hyperparameter Tuning, Deployment
|
||||
---
|
||||
|
||||
# Troubleshooting Common YOLO Issues
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/273067258-7c1b9aee-b4e8-43b5-befd-588d4f0bd361.png" alt="YOLO Common Issues Image">
|
||||
</p>
|
||||
|
||||
## Introduction
|
||||
|
||||
This guide serves as a comprehensive aid for troubleshooting common issues encountered while working with YOLOv8 on your Ultralytics projects. Navigating through these issues can be a breeze with the right guidance, ensuring your projects remain on track without unnecessary delays.
|
||||
|
||||
## Common Issues
|
||||
|
||||
### Installation Errors
|
||||
|
||||
Installation errors can arise due to various reasons, such as incompatible versions, missing dependencies, or incorrect environment setups. First, check to make sure you are doing the following:
|
||||
|
||||
- You're using Python 3.8 or later as recommended.
|
||||
|
||||
- Ensure that you have the correct version of PyTorch (1.8 or later) installed.
|
||||
|
||||
- Consider using virtual environments to avoid conflicts.
|
||||
|
||||
- Follow the [official installation guide](../quickstart.md) step by step.
|
||||
|
||||
Additionally, here are some common installation issues users have encountered, along with their respective solutions:
|
||||
|
||||
- Import Errors or Dependency Issues - If you're getting errors during the import of YOLOv8, or you're having issues related to dependencies, consider the following troubleshooting steps:
|
||||
|
||||
- **Fresh Installation**: Sometimes, starting with a fresh installation can resolve unexpected issues. Especially with libraries like Ultralytics, where updates might introduce changes to the file tree structure or functionalities.
|
||||
|
||||
- **Update Regularly**: Ensure you're using the latest version of the library. Older versions might not be compatible with recent updates, leading to potential conflicts or issues.
|
||||
|
||||
- **Check Dependencies**: Verify that all required dependencies are correctly installed and are of the compatible versions.
|
||||
|
||||
- **Review Changes**: If you initially cloned or installed an older version, be aware that significant updates might affect the library's structure or functionalities. Always refer to the official documentation or changelogs to understand any major changes.
|
||||
|
||||
- Remember, keeping your libraries and dependencies up-to-date is crucial for a smooth and error-free experience.
|
||||
|
||||
- Running YOLOv8 on GPU - If you're having trouble running YOLOv8 on GPU, consider the following troubleshooting steps:
|
||||
|
||||
- **Verify CUDA Compatibility and Installation**: Ensure your GPU is CUDA compatible and that CUDA is correctly installed. Use the `nvidia-smi` command to check the status of your NVIDIA GPU and CUDA version.
|
||||
|
||||
- **Check PyTorch and CUDA Integration**: Ensure PyTorch can utilize CUDA by running `import torch; print(torch.cuda.is_available())` in a Python terminal. If it returns 'True', PyTorch is set up to use CUDA.
|
||||
|
||||
- **Environment Activation**: Ensure you're in the correct environment where all necessary packages are installed.
|
||||
|
||||
- **Update Your Packages**: Outdated packages might not be compatible with your GPU. Keep them updated.
|
||||
|
||||
- **Program Configuration**: Check if the program or code specifies GPU usage. In YOLOv8, this might be in the settings or configuration.
|
||||
|
||||
### Model Training Issues
|
||||
|
||||
This section will address common issues faced while training and their respective explanations and solutions.
|
||||
|
||||
#### Verification of Configuration Settings
|
||||
|
||||
**Issue**: You are unsure whether the configuration settings in the `.yaml` file are being applied correctly during model training.
|
||||
|
||||
**Solution**: The configuration settings in the `.yaml` file should be applied when using the `model.train()` function. To ensure that these settings are correctly applied, follow these steps:
|
||||
|
||||
- Confirm that the path to your `.yaml` configuration file is correct.
|
||||
- Make sure you pass the path to your `.yaml` file as the `data` argument when calling `model.train()`, as shown below:
|
||||
|
||||
```python
|
||||
model.train(data='/path/to/your/data.yaml', batch=4)
|
||||
```
|
||||
|
||||
#### Accelerating Training with Multiple GPUs
|
||||
|
||||
**Issue**: Training is slow on a single GPU, and you want to speed up the process using multiple GPUs.
|
||||
|
||||
**Solution**: Increasing the batch size can accelerate training, but it's essential to consider GPU memory capacity. To speed up training with multiple GPUs, follow these steps:
|
||||
|
||||
- Ensure that you have multiple GPUs available.
|
||||
|
||||
- Modify your .yaml configuration file to specify the number of GPUs to use, e.g., gpus: 4.
|
||||
|
||||
- Increase the batch size accordingly to fully utilize the multiple GPUs without exceeding memory limits.
|
||||
|
||||
- Modify your training command to utilize multiple GPUs:
|
||||
|
||||
```python
|
||||
# Adjust the batch size and other settings as needed to optimize training speed
|
||||
model.train(data='/path/to/your/data.yaml', batch=32, multi_scale=True)
|
||||
```
|
||||
|
||||
#### Continuous Monitoring Parameters
|
||||
|
||||
**Issue**: You want to know which parameters should be continuously monitored during training, apart from loss.
|
||||
|
||||
**Solution**: While loss is a crucial metric to monitor, it's also essential to track other metrics for model performance optimization. Some key metrics to monitor during training include:
|
||||
|
||||
- Precision
|
||||
- Recall
|
||||
- Mean Average Precision (mAP)
|
||||
|
||||
You can access these metrics from the training logs or by using tools like TensorBoard or wandb for visualization. Implementing early stopping based on these metrics can help you achieve better results.
|
||||
|
||||
#### Tools for Tracking Training Progress
|
||||
|
||||
**Issue**: You are looking for recommendations on tools to track training progress.
|
||||
|
||||
**Solution**: To track and visualize training progress, you can consider using the following tools:
|
||||
|
||||
- [TensorBoard](https://www.tensorflow.org/tensorboard): TensorBoard is a popular choice for visualizing training metrics, including loss, accuracy, and more. You can integrate it with your YOLOv8 training process.
|
||||
- [Comet](https://bit.ly/yolov8-readme-comet): Comet provides an extensive toolkit for experiment tracking and comparison. It allows you to track metrics, hyperparameters, and even model weights. Integration with YOLO models is also straightforward, providing you with a complete overview of your experiment cycle.
|
||||
- [Ultralytics HUB](https://hub.ultralytics.com): Ultralytics HUB offers a specialized environment for tracking YOLO models, giving you a one-stop platform to manage metrics, datasets, and even collaborate with your team. Given its tailored focus on YOLO, it offers more customized tracking options.
|
||||
|
||||
Each of these tools offers its own set of advantages, so you may want to consider the specific needs of your project when making a choice.
|
||||
|
||||
#### How to Check if Training is Happening on the GPU
|
||||
|
||||
**Issue**: The 'device' value in the training logs is 'null,' and you're unsure if training is happening on the GPU.
|
||||
|
||||
**Solution**: The 'device' value being 'null' typically means that the training process is set to automatically use an available GPU, which is the default behavior. To ensure training occurs on a specific GPU, you can manually set the 'device' value to the GPU index (e.g., '0' for the first GPU) in your .yaml configuration file:
|
||||
|
||||
```yaml
|
||||
device: 0
|
||||
```
|
||||
|
||||
This will explicitly assign the training process to the specified GPU. If you wish to train on the CPU, set 'device' to 'cpu'.
|
||||
|
||||
Keep an eye on the 'runs' folder for logs and metrics to monitor training progress effectively.
|
||||
|
||||
#### Key Considerations for Effective Model Training
|
||||
|
||||
Here are some things to keep in mind, if you are facing issues related to model training.
|
||||
|
||||
**Dataset Format and Labels**
|
||||
|
||||
- Importance: The foundation of any machine learning model lies in the quality and format of the data it is trained on.
|
||||
|
||||
- Recommendation: Ensure that your custom dataset and its associated labels adhere to the expected format. It's crucial to verify that annotations are accurate and of high quality. Incorrect or subpar annotations can derail the model's learning process, leading to unpredictable outcomes.
|
||||
|
||||
**Model Convergence**
|
||||
|
||||
- Importance: Achieving model convergence ensures that the model has sufficiently learned from the training data.
|
||||
|
||||
- Recommendation: When training a model 'from scratch', it's vital to ensure that the model reaches a satisfactory level of convergence. This might necessitate a longer training duration, with more epochs, compared to when you're fine-tuning an existing model.
|
||||
|
||||
**Learning Rate and Batch Size**
|
||||
|
||||
- Importance: These hyperparameters play a pivotal role in determining how the model updates its weights during training.
|
||||
|
||||
- Recommendation: Regularly evaluate if the chosen learning rate and batch size are optimal for your specific dataset. Parameters that are not in harmony with the dataset's characteristics can hinder the model's performance.
|
||||
|
||||
**Class Distribution**
|
||||
|
||||
- Importance: The distribution of classes in your dataset can influence the model's prediction tendencies.
|
||||
|
||||
- Recommendation: Regularly assess the distribution of classes within your dataset. If there's a class imbalance, there's a risk that the model will develop a bias towards the more prevalent class. This bias can be evident in the confusion matrix, where the model might predominantly predict the majority class.
|
||||
|
||||
**Cross-Check with Pretrained Weights**
|
||||
|
||||
- Importance: Leveraging pretrained weights can provide a solid starting point for model training, especially when data is limited.
|
||||
|
||||
- Recommendation: As a diagnostic step, consider training your model using the same data but initializing it with pretrained weights. If this approach yields a well-formed confusion matrix, it could suggest that the 'from scratch' model might require further training or adjustments.
|
||||
|
||||
### Issues Related to Model Predictions
|
||||
|
||||
This section will address common issues faced during model prediction.
|
||||
|
||||
#### Getting Bounding Box Predictions With Your YOLOv8 Custom Model
|
||||
|
||||
**Issue**: When running predictions with a custom YOLOv8 model, there are challenges with the format and visualization of the bounding box coordinates.
|
||||
|
||||
**Solution**:
|
||||
|
||||
- Coordinate Format: YOLOv8 provides bounding box coordinates in absolute pixel values. To convert these to relative coordinates (ranging from 0 to 1), you need to divide by the image dimensions. For example, let’s say your image size is 640x640. Then you would do the following:
|
||||
|
||||
```python
|
||||
# Convert absolute coordinates to relative coordinates
|
||||
x1 = x1 / 640 # Divide x-coordinates by image width
|
||||
x2 = x2 / 640
|
||||
y1 = y1 / 640 # Divide y-coordinates by image height
|
||||
y2 = y2 / 640
|
||||
```
|
||||
|
||||
- File Name: To obtain the file name of the image you're predicting on, access the image file path directly from the result object within your prediction loop.
|
||||
|
||||
#### Filtering Objects in YOLOv8 Predictions
|
||||
|
||||
**Issue**: Facing issues with how to filter and display only specific objects in the prediction results when running YOLOv8 using the Ultralytics library.
|
||||
|
||||
**Solution**: To detect specific classes use the classes argument to specify the classes you want to include in the output. For instance, to detect only cars (assuming 'cars' have class index 2):
|
||||
|
||||
```shell
|
||||
yolo task=detect mode=segment model=yolov8n-seg.pt source='path/to/car.mp4' show=True classes=2
|
||||
```
|
||||
|
||||
#### Understanding Precision Metrics in YOLOv8
|
||||
|
||||
**Issue**: Confusion regarding the difference between box precision, mask precision, and confusion matrix precision in YOLOv8.
|
||||
|
||||
**Solution**: Box precision measures the accuracy of predicted bounding boxes compared to the actual ground truth boxes using IoU (Intersection over Union) as the metric. Mask precision assesses the agreement between predicted segmentation masks and ground truth masks in pixel-wise object classification. Confusion matrix precision, on the other hand, focuses on overall classification accuracy across all classes and does not consider the geometric accuracy of predictions. It's important to note that a bounding box can be geometrically accurate (true positive) even if the class prediction is wrong, leading to differences between box precision and confusion matrix precision. These metrics evaluate distinct aspects of a model's performance, reflecting the need for different evaluation metrics in various tasks.
|
||||
|
||||
#### Extracting Object Dimensions in YOLOv8
|
||||
|
||||
**Issue**: Difficulty in retrieving the length and height of detected objects in YOLOv8, especially when multiple objects are detected in an image.
|
||||
|
||||
**Solution**: To retrieve the bounding box dimensions, first use the Ultralytics YOLOv8 model to predict objects in an image. Then, extract the width and height information of bounding boxes from the prediction results.
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a pre-trained YOLOv8 model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Specify the source image
|
||||
source = 'https://ultralytics.com/images/bus.jpg'
|
||||
|
||||
# Make predictions
|
||||
results = model.predict(source, save=True, imgsz=320, conf=0.5)
|
||||
|
||||
# Extract bounding box dimensions
|
||||
boxes = results[0].boxes.xywh.cpu()
|
||||
for box in boxes:
|
||||
x, y, w, h = box
|
||||
print(f"Width of Box: {w}, Height of Box: {h}")
|
||||
```
|
||||
|
||||
### Deployment Challenges
|
||||
|
||||
#### GPU Deployment Issues
|
||||
|
||||
**Issue:** Deploying models in a multi-GPU environment can sometimes lead to unexpected behaviors like unexpected memory usage, inconsistent results across GPUs, etc.
|
||||
|
||||
**Solution:** Check for default GPU initialization. Some frameworks, like PyTorch, might initialize CUDA operations on a default GPU before transitioning to the designated GPUs. To bypass unexpected default initializations, specify the GPU directly during deployment and prediction. Then, use tools to monitor GPU utilization and memory usage to identify any anomalies in real-time. Also, ensure you're using the latest version of the framework or library.
|
||||
|
||||
#### Model Conversion/Exporting Issues
|
||||
|
||||
**Issue:** During the process of converting or exporting machine learning models to different formats or platforms, users might encounter errors or unexpected behaviors.
|
||||
|
||||
**Solution:**
|
||||
|
||||
- Compatibility Check: Ensure that you are using versions of libraries and frameworks that are compatible with each other. Mismatched versions can lead to unexpected errors during conversion.
|
||||
|
||||
- Environment Reset: If you're using an interactive environment like Jupyter or Colab, consider restarting your environment after making significant changes or installations. A fresh start can sometimes resolve underlying issues.
|
||||
|
||||
- Official Documentation: Always refer to the official documentation of the tool or library you are using for conversion. It often contains specific guidelines and best practices for model exporting.
|
||||
|
||||
- Community Support: Check the library or framework's official repository for similar issues reported by other users. The maintainers or community might have provided solutions or workarounds in discussion threads.
|
||||
|
||||
- Update Regularly: Ensure that you are using the latest version of the tool or library. Developers frequently release updates that fix known bugs or improve functionality.
|
||||
|
||||
- Test Incrementally: Before performing a full conversion, test the process with a smaller model or dataset to identify potential issues early on.
|
||||
|
||||
## Community and Support
|
||||
|
||||
Engaging with a community of like-minded individuals can significantly enhance your experience and success in working with YOLOv8. Below are some channels and resources you may find helpful.
|
||||
|
||||
### Forums and Channels for Getting Help
|
||||
|
||||
**GitHub Issues:** The YOLOv8 repository on GitHub has an [Issues tab](https://github.com/ultralytics/ultralytics/issues) where you can ask questions, report bugs, and suggest new features. The community and maintainers are active here, and it’s a great place to get help with specific problems.
|
||||
|
||||
**Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and the developers.
|
||||
|
||||
### Official Documentation and Resources
|
||||
|
||||
**Ultralytics YOLOv8 Docs**: The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
|
||||
|
||||
These resources should provide a solid foundation for troubleshooting and improving your YOLOv8 projects, as well as connecting with others in the YOLOv8 community.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Troubleshooting is an integral part of any development process, and being equipped with the right knowledge can significantly reduce the time and effort spent in resolving issues. This guide aimed to address the most common challenges faced by users of the YOLOv8 model within the Ultralytics ecosystem. By understanding and addressing these common issues, you can ensure smoother project progress and achieve better results with your computer vision tasks.
|
||||
|
||||
Remember, the Ultralytics community is a valuable resource. Engaging with fellow developers and experts can provide additional insights and solutions that might not be covered in standard documentation. Always keep learning, experimenting, and sharing your experiences to contribute to the collective knowledge of the community.
|
||||
|
||||
Happy troubleshooting!
|
||||
|
|
@ -1,165 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: A comprehensive guide on various performance metrics related to YOLOv8, their significance, and how to interpret them.
|
||||
keywords: YOLOv8, Performance metrics, Object detection, Intersection over Union (IoU), Average Precision (AP), Mean Average Precision (mAP), Precision, Recall, Validation mode, Ultralytics
|
||||
---
|
||||
|
||||
# Performance Metrics Deep Dive
|
||||
|
||||
## Introduction
|
||||
|
||||
Performance metrics are key tools to evaluate the accuracy and efficiency of object detection models. They shed light on how effectively a model can identify and localize objects within images. Additionally, they help in understanding the model's handling of false positives and false negatives. These insights are crucial for evaluating and enhancing the model's performance. In this guide, we will explore various performance metrics associated with YOLOv8, their significance, and how to interpret them.
|
||||
|
||||
## Object Detection Metrics
|
||||
|
||||
Let’s start by discussing some metrics that are not only important to YOLOv8 but are broadly applicable across different object detection models.
|
||||
|
||||
- **Intersection over Union (IoU):** IoU is a measure that quantifies the overlap between a predicted bounding box and a ground truth bounding box. It plays a fundamental role in evaluating the accuracy of object localization.
|
||||
|
||||
- **Average Precision (AP):** AP computes the area under the precision-recall curve, providing a single value that encapsulates the model's precision and recall performance.
|
||||
|
||||
- **Mean Average Precision (mAP):** mAP extends the concept of AP by calculating the average AP values across multiple object classes. This is useful in multi-class object detection scenarios to provide a comprehensive evaluation of the model's performance.
|
||||
|
||||
- **Precision and Recall:** Precision quantifies the proportion of true positives among all positive predictions, assessing the model's capability to avoid false positives. On the other hand, Recall calculates the proportion of true positives among all actual positives, measuring the model's ability to detect all instances of a class.
|
||||
|
||||
- **F1 Score:** The F1 Score is the harmonic mean of precision and recall, providing a balanced assessment of a model's performance while considering both false positives and false negatives.
|
||||
|
||||
## How to Calculate Metrics for YOLOv8 Model
|
||||
|
||||
Now, we can explore [YOLOv8's Validation mode](../modes/val.md) that can be used to compute the above discussed evaluation metrics.
|
||||
|
||||
Using the validation mode is simple. Once you have a trained model, you can invoke the model.val() function. This function will then process the validation dataset and return a variety of performance metrics. But what do these metrics mean? And how should you interpret them?
|
||||
|
||||
### Interpreting the Output
|
||||
|
||||
Let's break down the output of the model.val() function and understand each segment of the output.
|
||||
|
||||
#### Class-wise Metrics
|
||||
|
||||
One of the sections of the output is the class-wise breakdown of performance metrics. This granular information is useful when you are trying to understand how well the model is doing for each specific class, especially in datasets with a diverse range of object categories. For each class in the dataset the following is provided:
|
||||
|
||||
- **Class**: This denotes the name of the object class, such as "person", "car", or "dog".
|
||||
|
||||
- **Images**: This metric tells you the number of images in the validation set that contain the object class.
|
||||
|
||||
- **Instances**: This provides the count of how many times the class appears across all images in the validation set.
|
||||
|
||||
- **Box(P, R, mAP50, mAP50-95)**: This metric provides insights into the model's performance in detecting objects:
|
||||
|
||||
- **P (Precision)**: The accuracy of the detected objects, indicating how many detections were correct.
|
||||
|
||||
- **R (Recall)**: The ability of the model to identify all instances of objects in the images.
|
||||
|
||||
- **mAP50**: Mean average precision calculated at an intersection over union (IoU) threshold of 0.50. It's a measure of the model's accuracy considering only the "easy" detections.
|
||||
|
||||
- **mAP50-95**: The average of the mean average precision calculated at varying IoU thresholds, ranging from 0.50 to 0.95. It gives a comprehensive view of the model's performance across different levels of detection difficulty.
|
||||
|
||||
#### Speed Metrics
|
||||
|
||||
The speed of inference can be as critical as accuracy, especially in real-time object detection scenarios. This section breaks down the time taken for various stages of the validation process, from preprocessing to post-processing.
|
||||
|
||||
#### COCO Metrics Evaluation
|
||||
|
||||
For users validating on the COCO dataset, additional metrics are calculated using the COCO evaluation script. These metrics give insights into precision and recall at different IoU thresholds and for objects of different sizes.
|
||||
|
||||
#### Visual Outputs
|
||||
|
||||
The model.val() function, apart from producing numeric metrics, also yields visual outputs that can provide a more intuitive understanding of the model's performance. Here's a breakdown of the visual outputs you can expect:
|
||||
|
||||
- **F1 Score Curve (`F1_curve.png`)**: This curve represents the F1 score across various thresholds. Interpreting this curve can offer insights into the model's balance between false positives and false negatives over different thresholds.
|
||||
|
||||
- **Precision-Recall Curve (`PR_curve.png`)**: An integral visualization for any classification problem, this curve showcases the trade-offs between precision and recall at varied thresholds. It becomes especially significant when dealing with imbalanced classes.
|
||||
|
||||
- **Precision Curve (`P_curve.png`)**: A graphical representation of precision values at different thresholds. This curve helps in understanding how precision varies as the threshold changes.
|
||||
|
||||
- **Recall Curve (`R_curve.png`)**: Correspondingly, this graph illustrates how the recall values change across different thresholds.
|
||||
|
||||
- **Confusion Matrix (`confusion_matrix.png`)**: The confusion matrix provides a detailed view of the outcomes, showcasing the counts of true positives, true negatives, false positives, and false negatives for each class.
|
||||
|
||||
- **Normalized Confusion Matrix (`confusion_matrix_normalized.png`)**: This visualization is a normalized version of the confusion matrix. It represents the data in proportions rather than raw counts. This format makes it simpler to compare the performance across classes.
|
||||
|
||||
- **Validation Batch Labels (`val_batchX_labels.jpg`)**: These images depict the ground truth labels for distinct batches from the validation dataset. They provide a clear picture of what the objects are and their respective locations as per the dataset.
|
||||
|
||||
- **Validation Batch Predictions (`val_batchX_pred.jpg`)**: Contrasting the label images, these visuals display the predictions made by the YOLOv8 model for the respective batches. By comparing these to the label images, you can easily assess how well the model detects and classifies objects visually.
|
||||
|
||||
#### Results Storage
|
||||
|
||||
For future reference, the results are saved to a directory, typically named runs/detect/val.
|
||||
|
||||
## Choosing the Right Metrics
|
||||
|
||||
Choosing the right metrics to evaluate often depends on the specific application.
|
||||
|
||||
- **mAP:** Suitable for a broad assessment of model performance.
|
||||
|
||||
- **IoU:** Essential when precise object location is crucial.
|
||||
|
||||
- **Precision:** Important when minimizing false detections is a priority.
|
||||
|
||||
- **Recall:** Vital when it's important to detect every instance of an object.
|
||||
|
||||
- **F1 Score:** Useful when a balance between precision and recall is needed.
|
||||
|
||||
For real-time applications, speed metrics like FPS (Frames Per Second) and latency are crucial to ensure timely results.
|
||||
|
||||
## Interpretation of Results
|
||||
|
||||
It’s important to understand the metrics. Here's what some of the commonly observed lower scores might suggest:
|
||||
|
||||
- **Low mAP:** Indicates the model may need general refinements.
|
||||
|
||||
- **Low IoU:** The model might be struggling to pinpoint objects accurately. Different bounding box methods could help.
|
||||
|
||||
- **Low Precision:** The model may be detecting too many non-existent objects. Adjusting confidence thresholds might reduce this.
|
||||
|
||||
- **Low Recall:** The model could be missing real objects. Improving feature extraction or using more data might help.
|
||||
|
||||
- **Imbalanced F1 Score:** There's a disparity between precision and recall.
|
||||
|
||||
- **Class-specific AP:** Low scores here can highlight classes the model struggles with.
|
||||
|
||||
## Case Studies
|
||||
|
||||
Real-world examples can help clarify how these metrics work in practice.
|
||||
|
||||
### Case 1
|
||||
|
||||
- **Situation:** mAP and F1 Score are suboptimal, but while Recall is good, Precision isn't.
|
||||
|
||||
- **Interpretation & Action:** There might be too many incorrect detections. Tightening confidence thresholds could reduce these, though it might also slightly decrease recall.
|
||||
|
||||
### Case 2
|
||||
|
||||
- **Situation:** mAP and Recall are acceptable, but IoU is lacking.
|
||||
|
||||
- **Interpretation & Action:** The model detects objects well but might not be localizing them precisely. Refining bounding box predictions might help.
|
||||
|
||||
### Case 3
|
||||
|
||||
- **Situation:** Some classes have a much lower AP than others, even with a decent overall mAP.
|
||||
|
||||
- **Interpretation & Action:** These classes might be more challenging for the model. Using more data for these classes or adjusting class weights during training could be beneficial.
|
||||
|
||||
## Connect and Collaborate
|
||||
|
||||
Tapping into a community of enthusiasts and experts can amplify your journey with YOLOv8. Here are some avenues that can facilitate learning, troubleshooting, and networking.
|
||||
|
||||
### Engage with the Broader Community
|
||||
|
||||
- **GitHub Issues:** The YOLOv8 repository on GitHub has an [Issues tab](https://github.com/ultralytics/ultralytics/issues) where you can ask questions, report bugs, and suggest new features. The community and maintainers are active here, and it’s a great place to get help with specific problems.
|
||||
|
||||
- **Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and the developers.
|
||||
|
||||
### Official Documentation and Resources:
|
||||
|
||||
- **Ultralytics YOLOv8 Docs:** The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
|
||||
|
||||
Using these resources will not only guide you through any challenges but also keep you updated with the latest trends and best practices in the YOLOv8 community.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this guide, we've taken a close look at the essential performance metrics for YOLOv8. These metrics are key to understanding how well a model is performing and are vital for anyone aiming to fine-tune their models. They offer the necessary insights for improvements and to make sure the model works effectively in real-life situations.
|
||||
|
||||
Remember, the YOLOv8 and Ultralytics community is an invaluable asset. Engaging with fellow developers and experts can open doors to insights and solutions not found in standard documentation. As you journey through object detection, keep the spirit of learning alive, experiment with new strategies, and share your findings. By doing so, you contribute to the community's collective wisdom and ensure its growth.
|
||||
|
||||
Happy object detecting!
|
||||
|
|
@ -1,108 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: This guide provides best practices for performing thread-safe inference with YOLO models, ensuring reliable and concurrent predictions in multi-threaded applications.
|
||||
keywords: thread-safe, YOLO inference, multi-threading, concurrent predictions, YOLO models, Ultralytics, Python threading, safe YOLO usage, AI concurrency
|
||||
---
|
||||
|
||||
# Thread-Safe Inference with YOLO Models
|
||||
|
||||
Running YOLO models in a multi-threaded environment requires careful consideration to ensure thread safety. Python's `threading` module allows you to run several threads concurrently, but when it comes to using YOLO models across these threads, there are important safety issues to be aware of. This page will guide you through creating thread-safe YOLO model inference.
|
||||
|
||||
## Understanding Python Threading
|
||||
|
||||
Python threads are a form of parallelism that allow your program to run multiple operations at once. However, Python's Global Interpreter Lock (GIL) means that only one thread can execute Python bytecode at a time.
|
||||
|
||||
<p align="center">
|
||||
<img width="800" src="https://user-images.githubusercontent.com/26833433/281418476-7f478570-fd77-4a40-bf3d-74b4db4d668c.png" alt="Single vs Multi-Thread Examples">
|
||||
</p>
|
||||
|
||||
While this sounds like a limitation, threads can still provide concurrency, especially for I/O-bound operations or when using operations that release the GIL, like those performed by YOLO's underlying C libraries.
|
||||
|
||||
## The Danger of Shared Model Instances
|
||||
|
||||
Instantiating a YOLO model outside your threads and sharing this instance across multiple threads can lead to race conditions, where the internal state of the model is inconsistently modified due to concurrent accesses. This is particularly problematic when the model or its components hold state that is not designed to be thread-safe.
|
||||
|
||||
### Non-Thread-Safe Example: Single Model Instance
|
||||
|
||||
When using threads in Python, it's important to recognize patterns that can lead to concurrency issues. Here is what you should avoid: sharing a single YOLO model instance across multiple threads.
|
||||
|
||||
```python
|
||||
# Unsafe: Sharing a single model instance across threads
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
# Instantiate the model outside the thread
|
||||
shared_model = YOLO("yolov8n.pt")
|
||||
|
||||
|
||||
def predict(image_path):
|
||||
results = shared_model.predict(image_path)
|
||||
# Process results
|
||||
|
||||
|
||||
# Starting threads that share the same model instance
|
||||
Thread(target=predict, args=("image1.jpg",)).start()
|
||||
Thread(target=predict, args=("image2.jpg",)).start()
|
||||
```
|
||||
|
||||
In the example above, the `shared_model` is used by multiple threads, which can lead to unpredictable results because `predict` could be executed simultaneously by multiple threads.
|
||||
|
||||
### Non-Thread-Safe Example: Multiple Model Instances
|
||||
|
||||
Similarly, here is an unsafe pattern with multiple YOLO model instances:
|
||||
|
||||
```python
|
||||
# Unsafe: Sharing multiple model instances across threads can still lead to issues
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
# Instantiate multiple models outside the thread
|
||||
shared_model_1 = YOLO("yolov8n_1.pt")
|
||||
shared_model_2 = YOLO("yolov8n_2.pt")
|
||||
|
||||
|
||||
def predict(model, image_path):
|
||||
results = model.predict(image_path)
|
||||
# Process results
|
||||
|
||||
|
||||
# Starting threads with individual model instances
|
||||
Thread(target=predict, args=(shared_model_1, "image1.jpg")).start()
|
||||
Thread(target=predict, args=(shared_model_2, "image2.jpg")).start()
|
||||
```
|
||||
|
||||
Even though there are two separate model instances, the risk of concurrency issues still exists. If the internal implementation of `YOLO` is not thread-safe, using separate instances might not prevent race conditions, especially if these instances share any underlying resources or states that are not thread-local.
|
||||
|
||||
## Thread-Safe Inference
|
||||
|
||||
To perform thread-safe inference, you should instantiate a separate YOLO model within each thread. This ensures that each thread has its own isolated model instance, eliminating the risk of race conditions.
|
||||
|
||||
### Thread-Safe Example
|
||||
|
||||
Here's how to instantiate a YOLO model inside each thread for safe parallel inference:
|
||||
|
||||
```python
|
||||
# Safe: Instantiating a single model inside each thread
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
|
||||
def thread_safe_predict(image_path):
|
||||
# Instantiate a new model inside the thread
|
||||
local_model = YOLO("yolov8n.pt")
|
||||
results = local_model.predict(image_path)
|
||||
# Process results
|
||||
|
||||
|
||||
# Starting threads that each have their own model instance
|
||||
Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
|
||||
Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
|
||||
```
|
||||
|
||||
In this example, each thread creates its own `YOLO` instance. This prevents any thread from interfering with the model state of another, thus ensuring that each thread performs inference safely and without unexpected interactions with the other threads.
|
||||
|
||||
## Conclusion
|
||||
|
||||
When using YOLO models with Python's `threading`, always instantiate your models within the thread that will use them to ensure thread safety. This practice avoids race conditions and makes sure that your inference tasks run reliably.
|
||||
|
||||
For more advanced scenarios and to further optimize your multi-threaded inference performance, consider using process-based parallelism with `multiprocessing` or leveraging a task queue with dedicated worker processes.
|
||||
|
|
@ -1,61 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Learn how Ultralytics leverages Continuous Integration (CI) for maintaining high-quality code. Explore our CI tests and the status of these tests for our repositories.
|
||||
keywords: continuous integration, software development, CI tests, Ultralytics repositories, high-quality code, Docker Deployment, Broken Links, CodeQL, PyPi Publishing
|
||||
---
|
||||
|
||||
# Continuous Integration (CI)
|
||||
|
||||
Continuous Integration (CI) is an essential aspect of software development which involves integrating changes and testing them automatically. CI allows us to maintain high-quality code by catching issues early and often in the development process. At Ultralytics, we use various CI tests to ensure the quality and integrity of our codebase.
|
||||
|
||||
## CI Actions
|
||||
|
||||
Here's a brief description of our CI actions:
|
||||
|
||||
- **CI:** This is our primary CI test that involves running unit tests, linting checks, and sometimes more comprehensive tests depending on the repository.
|
||||
- **Docker Deployment:** This test checks the deployment of the project using Docker to ensure the Dockerfile and related scripts are working correctly.
|
||||
- **Broken Links:** This test scans the codebase for any broken or dead links in our markdown or HTML files.
|
||||
- **CodeQL:** CodeQL is a tool from GitHub that performs semantic analysis on our code, helping to find potential security vulnerabilities and maintain high-quality code.
|
||||
- **PyPi Publishing:** This test checks if the project can be packaged and published to PyPi without any errors.
|
||||
|
||||
### CI Results
|
||||
|
||||
Below is the table showing the status of these CI tests for our main repositories:
|
||||
|
||||
| Repository | CI | Docker Deployment | Broken Links | CodeQL | PyPi and Docs Publishing |
|
||||
|-----------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [yolov3](https://github.com/ultralytics/yolov3) | [](https://github.com/ultralytics/yolov3/actions/workflows/ci-testing.yml) | [](https://github.com/ultralytics/yolov3/actions/workflows/docker.yml) | [](https://github.com/ultralytics/yolov3/actions/workflows/links.yml) | [](https://github.com/ultralytics/yolov3/actions/workflows/codeql-analysis.yml) | |
|
||||
| [yolov5](https://github.com/ultralytics/yolov5) | [](https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml) | [](https://github.com/ultralytics/yolov5/actions/workflows/docker.yml) | [](https://github.com/ultralytics/yolov5/actions/workflows/links.yml) | [](https://github.com/ultralytics/yolov5/actions/workflows/codeql-analysis.yml) | |
|
||||
| [ultralytics](https://github.com/ultralytics/ultralytics) | [](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) |
|
||||
| [hub](https://github.com/ultralytics/hub) | [](https://github.com/ultralytics/hub/actions/workflows/ci.yaml) | | [](https://github.com/ultralytics/hub/actions/workflows/links.yml) | | |
|
||||
| [docs](https://github.com/ultralytics/docs) | | | [](https://github.com/ultralytics/docs/actions/workflows/links.yml) | | [](https://github.com/ultralytics/docs/actions/workflows/pages/pages-build-deployment) |
|
||||
|
||||
Each badge shows the status of the last run of the corresponding CI test on the `main` branch of the respective repository. If a test fails, the badge will display a "failing" status, and if it passes, it will display a "passing" status.
|
||||
|
||||
If you notice a test failing, it would be a great help if you could report it through a GitHub issue in the respective repository.
|
||||
|
||||
Remember, a successful CI test does not mean that everything is perfect. It is always recommended to manually review the code before deployment or merging changes.
|
||||
|
||||
## Code Coverage
|
||||
|
||||
Code coverage is a metric that represents the percentage of your codebase that is executed when your tests run. It provides insight into how well your tests exercise your code and can be crucial in identifying untested parts of your application. A high code coverage percentage is often associated with a lower likelihood of bugs. However, it's essential to understand that code coverage doesn't guarantee the absence of defects. It merely indicates which parts of the code have been executed by the tests.
|
||||
|
||||
### Integration with [codecov.io](https://codecov.io/)
|
||||
|
||||
At Ultralytics, we have integrated our repositories with [codecov.io](https://codecov.io/), a popular online platform for measuring and visualizing code coverage. Codecov provides detailed insights, coverage comparisons between commits, and visual overlays directly on your code, indicating which lines were covered.
|
||||
|
||||
By integrating with Codecov, we aim to maintain and improve the quality of our code by focusing on areas that might be prone to errors or need further testing.
|
||||
|
||||
### Coverage Results
|
||||
|
||||
To quickly get a glimpse of the code coverage status of the `ultralytics` python package, we have included a badge and and sunburst visual of the `ultralytics` coverage results. These images show the percentage of code covered by our tests, offering an at-a-glance metric of our testing efforts. For full details please see https://codecov.io/github/ultralytics/ultralytics.
|
||||
|
||||
| Repository | Code Coverage |
|
||||
|-----------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [ultralytics](https://github.com/ultralytics/ultralytics) | [](https://codecov.io/gh/ultralytics/ultralytics) |
|
||||
|
||||
In the sunburst graphic below, the inner-most circle is the entire project, moving away from the center are folders then, finally, a single file. The size and color of each slice is representing the number of statements and the coverage, respectively.
|
||||
|
||||
<a href="https://codecov.io/github/ultralytics/ultralytics">
|
||||
<img src="https://codecov.io/gh/ultralytics/ultralytics/branch/main/graphs/sunburst.svg?token=HHW7IIVFVY" alt="Ultralytics Codecov Image">
|
||||
</a>
|
||||
|
|
@ -1,31 +0,0 @@
|
|||
---
|
||||
description: Understand terms governing contributions to Ultralytics projects including source code, bug fixes, documentation and more. Read our Contributor License Agreement.
|
||||
keywords: Ultralytics, Contributor License Agreement, Open Source Software, Contributions, Copyright License, Patent License, Moral Rights
|
||||
---
|
||||
|
||||
# Ultralytics Individual Contributor License Agreement
|
||||
|
||||
Thank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics SE or its affiliates (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms governing any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any manner, to Ultralytics in respect of any of the Projects (collectively “Contributions”). If you have any questions respecting this Agreement, please contact hello@ultralytics.com.
|
||||
|
||||
You agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses granted in this Agreement, you retain all of your right, title and interest in and to your Contributions.
|
||||
|
||||
**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
|
||||
|
||||
**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer your Contributions, where such license applies only to those patent claims licensable by you that are necessarily infringed by your Contributions alone or by combination of your Contributions with the Project to which such Contributions were submitted, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
|
||||
|
||||
**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to assert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and their respective direct and indirect sublicensees.
|
||||
|
||||
**Third Party Content/Rights.
|
||||
** If your Contribution includes or is based on any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any third party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”), then you agree to include with the submission of your Contribution full details respecting such Third Party Content and Third Party Rights, including, without limitation, identification of which aspects of your Contribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the Third Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable third party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater certainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights do not apply to any portion of a Project that is incorporated into your Contribution to that same Project.
|
||||
|
||||
**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were created in the course of your employment with your past or present employer(s), you represent that such employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer
|
||||
(s) has waived all of their right, title or interest in or to your Contributions.
|
||||
|
||||
**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis"
|
||||
basis, without any warranties or conditions, express or implied, including, without limitation, any implied warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not required to provide support for your Contributions, except to the extent you desire to provide support.
|
||||
|
||||
**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions into any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be made at the sole discretion of Ultralytics or its authorized delegates ..
|
||||
|
||||
**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of New York, United States of America, without giving effect to its principles or rules regarding conflicts of laws, other than such principles directing application of New York law. The parties hereby submit to venue in, and jurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event that any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction to be unenforceable, the remaining portions hereof shall remain in full force and effect.
|
||||
|
||||
**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses hereunder.
|
||||
|
|
@ -1,39 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Find solutions to your common Ultralytics YOLO related queries. Learn about hardware requirements, fine-tuning YOLO models, conversion to ONNX/TensorFlow, and more.
|
||||
keywords: Ultralytics, YOLO, FAQ, hardware requirements, ONNX, TensorFlow, real-time detection, YOLO accuracy
|
||||
---
|
||||
|
||||
# Ultralytics YOLO Frequently Asked Questions (FAQ)
|
||||
|
||||
This FAQ section addresses some common questions and issues users might encounter while working with Ultralytics YOLO repositories.
|
||||
|
||||
## 1. What are the hardware requirements for running Ultralytics YOLO?
|
||||
|
||||
Ultralytics YOLO can be run on a variety of hardware configurations, including CPUs, GPUs, and even some edge devices. However, for optimal performance and faster training and inference, we recommend using a GPU with a minimum of 8GB of memory. NVIDIA GPUs with CUDA support are ideal for this purpose.
|
||||
|
||||
## 2. How do I fine-tune a pre-trained YOLO model on my custom dataset?
|
||||
|
||||
To fine-tune a pre-trained YOLO model on your custom dataset, you'll need to create a dataset configuration file (YAML) that defines the dataset's properties, such as the path to the images, the number of classes, and class names. Next, you'll need to modify the model configuration file to match the number of classes in your dataset. Finally, use the `train.py` script to start the training process with your custom dataset and the pre-trained model. You can find a detailed guide on fine-tuning YOLO in the Ultralytics documentation.
|
||||
|
||||
## 3. How do I convert a YOLO model to ONNX or TensorFlow format?
|
||||
|
||||
Ultralytics provides built-in support for converting YOLO models to ONNX format. You can use the `export.py` script to convert a saved model to ONNX format. If you need to convert the model to TensorFlow format, you can use the ONNX model as an intermediary and then use the ONNX-TensorFlow converter to convert the ONNX model to TensorFlow format.
|
||||
|
||||
## 4. Can I use Ultralytics YOLO for real-time object detection?
|
||||
|
||||
Yes, Ultralytics YOLO is designed to be efficient and fast, making it suitable for real-time object detection tasks. The actual performance will depend on your hardware configuration and the complexity of the model. Using a GPU and optimizing the model for your specific use case can help achieve real-time performance.
|
||||
|
||||
## 5. How can I improve the accuracy of my YOLO model?
|
||||
|
||||
Improving the accuracy of a YOLO model may involve several strategies, such as:
|
||||
|
||||
- Fine-tuning the model on more annotated data
|
||||
- Data augmentation to increase the variety of training samples
|
||||
- Using a larger or more complex model architecture
|
||||
- Adjusting the learning rate, batch size, and other hyperparameters
|
||||
- Using techniques like transfer learning or knowledge distillation
|
||||
|
||||
Remember that there's often a trade-off between accuracy and inference speed, so finding the right balance is crucial for your specific application.
|
||||
|
||||
If you have any more questions or need assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through GitHub Issues or the official discussion forum.
|
||||
|
|
@ -1,88 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Explore Ultralytics community’s Code of Conduct, ensuring a supportive, inclusive environment for contributors & members at all levels. Find our guidelines on acceptable behavior & enforcement.
|
||||
keywords: Ultralytics, code of conduct, community, contribution, behavior guidelines, enforcement, open source contributions
|
||||
---
|
||||
|
||||
# Ultralytics Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our community include:
|
||||
|
||||
- Demonstrating empathy and kindness toward other people
|
||||
- Being respectful of differing opinions, viewpoints, and experiences
|
||||
- Giving and gracefully accepting constructive feedback
|
||||
- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
|
||||
- Focusing on what is best not just for us as individuals, but for the overall community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
- The use of sexualized language or imagery, and sexual attention or advances of any kind
|
||||
- Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
- Public or private harassment
|
||||
- Publishing others' private information, such as a physical or email address, without their explicit permission
|
||||
- Other conduct which could reasonably be considered inappropriate in a professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at hello@ultralytics.com. All complaints will be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
|
@ -1,76 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Learn how to contribute to Ultralytics YOLO projects – guidelines for pull requests, reporting bugs, code conduct and CLA signing.
|
||||
keywords: Ultralytics, YOLO, open-source, contribute, pull request, bug report, coding guidelines, CLA, code of conduct, GitHub
|
||||
---
|
||||
|
||||
# Contributing to Ultralytics Open-Source YOLO Repositories
|
||||
|
||||
First of all, thank you for your interest in contributing to Ultralytics open-source YOLO repositories! Your contributions will help improve the project and benefit the community. This document provides guidelines and best practices to get you started.
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [Code of Conduct](#code-of-conduct)
|
||||
- [Pull Requests](#pull-requests)
|
||||
- [CLA Signing](#cla-signing)
|
||||
- [Google-Style Docstrings](#google-style-docstrings)
|
||||
- [GitHub Actions CI Tests](#github-actions-ci-tests)
|
||||
- [Bug Reports](#bug-reports)
|
||||
- [Minimum Reproducible Example](#minimum-reproducible-example)
|
||||
- [License and Copyright](#license-and-copyright)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
All contributors are expected to adhere to the [Code of Conduct](code_of_conduct.md) to ensure a welcoming and inclusive environment for everyone.
|
||||
|
||||
## Pull Requests
|
||||
|
||||
We welcome contributions in the form of pull requests. To make the review process smoother, please follow these guidelines:
|
||||
|
||||
1. **Fork the repository**: Fork the Ultralytics YOLO repository to your own GitHub account.
|
||||
|
||||
2. **Create a branch**: Create a new branch in your forked repository with a descriptive name for your changes.
|
||||
|
||||
3. **Make your changes**: Make the changes you want to contribute. Ensure that your changes follow the coding style of the project and do not introduce new errors or warnings.
|
||||
|
||||
4. **Test your changes**: Test your changes locally to ensure that they work as expected and do not introduce new issues.
|
||||
|
||||
5. **Commit your changes**: Commit your changes with a descriptive commit message. Make sure to include any relevant issue numbers in your commit message.
|
||||
|
||||
6. **Create a pull request**: Create a pull request from your forked repository to the main Ultralytics YOLO repository. In the pull request description, provide a clear explanation of your changes and how they improve the project.
|
||||
|
||||
### CLA Signing
|
||||
|
||||
Before we can accept your pull request, you need to sign a [Contributor License Agreement (CLA)](CLA.md). This is a legal document stating that you agree to the terms of contributing to the Ultralytics YOLO repositories. The CLA ensures that your contributions are properly licensed and that the project can continue to be distributed under the AGPL-3.0 license.
|
||||
|
||||
To sign the CLA, follow the instructions provided by the CLA bot after you submit your PR.
|
||||
|
||||
### Google-Style Docstrings
|
||||
|
||||
When adding new functions or classes, please include a [Google-style docstring](https://google.github.io/styleguide/pyguide.html) to provide clear and concise documentation for other developers. This will help ensure that your contributions are easy to understand and maintain.
|
||||
|
||||
Example Google-style docstring:
|
||||
|
||||
```python
|
||||
def example_function(arg1: int, arg2: int) -> bool:
|
||||
"""
|
||||
Example function that demonstrates Google-style docstrings.
|
||||
|
||||
Args:
|
||||
arg1 (int): The first argument.
|
||||
arg2 (int): The second argument.
|
||||
|
||||
Returns:
|
||||
(bool): True if successful, False otherwise.
|
||||
|
||||
Examples:
|
||||
>>> result = example_function(1, 2) # returns False
|
||||
"""
|
||||
if arg1 == arg2:
|
||||
return True
|
||||
return False
|
||||
```
|
||||
|
||||
### GitHub Actions CI Tests
|
||||
|
||||
Before your pull request can be merged, all GitHub Actions Continuous Integration (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues
|
||||
|
|
@ -1,37 +0,0 @@
|
|||
---
|
||||
comments: false
|
||||
description: Discover Ultralytics’ EHS policy principles and implementation measures. Committed to safety, environment, and continuous improvement for a sustainable future.
|
||||
keywords: Ultralytics policy, EHS, environment, health and safety, compliance, prevention, continuous improvement, risk management, emergency preparedness, resource allocation, communication
|
||||
---
|
||||
|
||||
# Ultralytics Environmental, Health and Safety (EHS) Policy
|
||||
|
||||
At Ultralytics, we recognize that the long-term success of our company relies not only on the products and services we offer, but also the manner in which we conduct our business. We are committed to ensuring the safety and well-being of our employees, stakeholders, and the environment, and we will continuously strive to mitigate our impact on the environment while promoting health and safety.
|
||||
|
||||
## Policy Principles
|
||||
|
||||
1. **Compliance**: We will comply with all applicable laws, regulations, and standards related to EHS, and we will strive to exceed these standards where possible.
|
||||
|
||||
2. **Prevention**: We will work to prevent accidents, injuries, and environmental harm by implementing risk management measures and ensuring all our operations and procedures are safe.
|
||||
|
||||
3. **Continuous Improvement**: We will continuously improve our EHS performance by setting measurable objectives, monitoring our performance, auditing our operations, and revising our policies and procedures as needed.
|
||||
|
||||
4. **Communication**: We will communicate openly about our EHS performance and will engage with stakeholders to understand and address their concerns and expectations.
|
||||
|
||||
5. **Education and Training**: We will educate and train our employees and contractors in appropriate EHS procedures and practices.
|
||||
|
||||
## Implementation Measures
|
||||
|
||||
1. **Responsibility and Accountability**: Every employee and contractor working at or with Ultralytics is responsible for adhering to this policy. Managers and supervisors are accountable for ensuring this policy is implemented within their areas of control.
|
||||
|
||||
2. **Risk Management**: We will identify, assess, and manage EHS risks associated with our operations and activities to prevent accidents, injuries, and environmental harm.
|
||||
|
||||
3. **Resource Allocation**: We will allocate the necessary resources to ensure the effective implementation of our EHS policy, including the necessary equipment, personnel, and training.
|
||||
|
||||
4. **Emergency Preparedness and Response**: We will develop, maintain, and test emergency preparedness and response plans to ensure we can respond effectively to EHS incidents.
|
||||
|
||||
5. **Monitoring and Review**: We will monitor and review our EHS performance regularly to identify opportunities for improvement and ensure we are meeting our objectives.
|
||||
|
||||
This policy reflects our commitment to minimizing our environmental footprint, ensuring the safety and well-being of our employees, and continuously improving our performance.
|
||||
|
||||
Please remember that the implementation of an effective EHS policy requires the involvement and commitment of everyone working at or with Ultralytics. We encourage you to take personal responsibility for your safety and the safety of others, and to take care of the environment in which we live and work.
|
||||
|
|
@ -1,19 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Find comprehensive guides and documents on Ultralytics YOLO tasks. Includes FAQs, contributing guides, CI guide, CLA, MRE guide, code of conduct & more.
|
||||
keywords: Ultralytics, YOLO, guides, documents, FAQ, contributing, CI guide, CLA, MRE guide, code of conduct, EHS policy, security policy, privacy policy
|
||||
---
|
||||
|
||||
Welcome to the Ultralytics Help page! We are dedicated to providing you with detailed resources to enhance your experience with the Ultralytics YOLO models and repositories. This page serves as your portal to guides and documentation designed to assist you with various tasks and answer questions you may encounter while engaging with our repositories.
|
||||
|
||||
- [Frequently Asked Questions (FAQ)](FAQ.md): Find answers to common questions and issues encountered by the community of Ultralytics YOLO users and contributors.
|
||||
- [Contributing Guide](contributing.md): Discover the protocols for making contributions, including how to submit pull requests, report bugs, and more.
|
||||
- [Continuous Integration (CI) Guide](CI.md): Gain insights into the CI processes we employ, complete with status reports for each Ultralytics repository.
|
||||
- [Contributor License Agreement (CLA)](CLA.md): Review the CLA to understand the rights and responsibilities associated with contributing to Ultralytics projects.
|
||||
- [Minimum Reproducible Example (MRE) Guide](minimum_reproducible_example.md): Learn the process for creating an MRE, which is crucial for the timely and effective resolution of bug reports.
|
||||
- [Code of Conduct](code_of_conduct.md): Our community guidelines support a respectful and open atmosphere for all collaborators.
|
||||
- [Environmental, Health and Safety (EHS) Policy](environmental-health-safety.md): Delve into our commitment to sustainability and the well-being of all our stakeholders.
|
||||
- [Security Policy](security.md): Familiarize yourself with our security protocols and the procedure for reporting vulnerabilities.
|
||||
- [Privacy Policy](privacy.md): Read our privacy policy to understand how we protect your data and respect your privacy in all our services and operations.
|
||||
|
||||
We encourage you to review these resources for a seamless and productive experience. Our aim is to foster a helpful and friendly environment for everyone in the Ultralytics community. Should you require additional support, please feel free to reach out via GitHub Issues or our official discussion forums. Happy coding!
|
||||
|
|
@ -1,78 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Learn how to create minimum reproducible examples (MRE) for efficient bug reporting in Ultralytics YOLO repositories with this step-by-step guide.
|
||||
keywords: Ultralytics, YOLO, minimum reproducible example, MRE, bug reports, guide, dependencies, code, troubleshooting
|
||||
---
|
||||
|
||||
# Creating a Minimum Reproducible Example for Bug Reports in Ultralytics YOLO Repositories
|
||||
|
||||
When submitting a bug report for Ultralytics YOLO repositories, it's essential to provide a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) (MRE). An MRE is a small, self-contained piece of code that demonstrates the problem you're experiencing. Providing an MRE helps maintainers and contributors understand the issue and work on a fix more efficiently. This guide explains how to create an MRE when submitting bug reports to Ultralytics YOLO repositories.
|
||||
|
||||
## 1. Isolate the Problem
|
||||
|
||||
The first step in creating an MRE is to isolate the problem. This means removing any unnecessary code or dependencies that are not directly related to the issue. Focus on the specific part of the code that is causing the problem and remove any irrelevant code.
|
||||
|
||||
## 2. Use Public Models and Datasets
|
||||
|
||||
When creating an MRE, use publicly available models and datasets to reproduce the issue. For example, use the 'yolov8n.pt' model and the 'coco8.yaml' dataset. This ensures that the maintainers and contributors can easily run your example and investigate the problem without needing access to proprietary data or custom models.
|
||||
|
||||
## 3. Include All Necessary Dependencies
|
||||
|
||||
Make sure to include all the necessary dependencies in your MRE. If your code relies on external libraries, specify the required packages and their versions. Ideally, provide a `requirements.txt` file or list the dependencies in your bug report.
|
||||
|
||||
## 4. Write a Clear Description of the Issue
|
||||
|
||||
Provide a clear and concise description of the issue you're experiencing. Explain the expected behavior and the actual behavior you're encountering. If applicable, include any relevant error messages or logs.
|
||||
|
||||
## 5. Format Your Code Properly
|
||||
|
||||
When submitting an MRE, format your code properly using code blocks in the issue description. This makes it easier for others to read and understand your code. In GitHub, you can create a code block by wrapping your code with triple backticks (\```) and specifying the language:
|
||||
|
||||
<pre>
|
||||
```python
|
||||
# Your Python code goes here
|
||||
```
|
||||
</pre>
|
||||
|
||||
## 6. Test Your MRE
|
||||
|
||||
Before submitting your MRE, test it to ensure that it accurately reproduces the issue. Make sure that others can run your example without any issues or modifications.
|
||||
|
||||
## Example of an MRE
|
||||
|
||||
Here's an example of an MRE for a hypothetical bug report:
|
||||
|
||||
**Bug description:**
|
||||
|
||||
When running the `detect.py` script on the sample image from the 'coco8.yaml' dataset, I get an error related to the dimensions of the input tensor.
|
||||
|
||||
**MRE:**
|
||||
|
||||
```python
|
||||
import torch
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load the model
|
||||
model = YOLO("yolov8n.pt")
|
||||
|
||||
# Load a 0-channel image
|
||||
image = torch.rand(1, 0, 640, 640)
|
||||
|
||||
# Run the model
|
||||
results = model(image)
|
||||
```
|
||||
|
||||
**Error message:**
|
||||
|
||||
```
|
||||
RuntimeError: Expected input[1, 0, 640, 640] to have 3 channels, but got 0 channels instead
|
||||
```
|
||||
|
||||
**Dependencies:**
|
||||
|
||||
- torch==2.0.0
|
||||
- ultralytics==8.0.90
|
||||
|
||||
In this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model ('yolov8n.pt'), includes all necessary dependencies, and provides a clear description of the problem along with the error message.
|
||||
|
||||
By following these guidelines, you'll help the maintainers and contributors of Ultralytics YOLO repositories to understand and resolve your issue more efficiently.
|
||||
|
|
@ -1,137 +0,0 @@
|
|||
---
|
||||
description: Learn about how Ultralytics collects and uses data to improve user experience, ensure software stability, and address privacy concerns, with options to opt-out.
|
||||
keywords: Ultralytics, Data Collection, User Privacy, Google Analytics, Sentry, Crash Reporting, Anonymized Data, Privacy Settings, Opt-Out
|
||||
---
|
||||
|
||||
# Data Collection for Ultralytics Python Package
|
||||
|
||||
## Overview
|
||||
|
||||
[Ultralytics](https://ultralytics.com) is dedicated to the continuous enhancement of the user experience and the capabilities of our Python package, including the advanced YOLO models we develop. Our approach involves the gathering of anonymized usage statistics and crash reports, helping us identify opportunities for improvement and ensuring the reliability of our software. This transparency document outlines what data we collect, its purpose, and the choice you have regarding this data collection.
|
||||
|
||||
## Anonymized Google Analytics
|
||||
|
||||
[Google Analytics](https://developers.google.com/analytics) is a web analytics service offered by Google that tracks and reports website traffic. It allows us to collect data about how our Python package is used, which is crucial for making informed decisions about design and functionality.
|
||||
|
||||
### What We Collect
|
||||
|
||||
- **Usage Metrics**: These metrics help us understand how frequently and in what ways the package is utilized, what features are favored, and the typical command-line arguments that are used.
|
||||
- **System Information**: We collect general non-identifiable information about your computing environment to ensure our package performs well across various systems.
|
||||
- **Performance Data**: Understanding the performance of our models during training, validation, and inference helps us in identifying optimization opportunities.
|
||||
|
||||
For more information about Google Analytics and data privacy, visit [Google Analytics Privacy](https://support.google.com/analytics/answer/6004245).
|
||||
|
||||
### How We Use This Data
|
||||
|
||||
- **Feature Improvement**: Insights from usage metrics guide us in enhancing user satisfaction and interface design.
|
||||
- **Optimization**: Performance data assist us in fine-tuning our models for better efficiency and speed across diverse hardware and software configurations.
|
||||
- **Trend Analysis**: By studying usage trends, we can predict and respond to the evolving needs of our community.
|
||||
|
||||
### Privacy Considerations
|
||||
|
||||
We take several measures to ensure the privacy and security of the data you entrust to us:
|
||||
|
||||
- **Anonymization**: We configure Google Analytics to anonymize the data collected, which means no personally identifiable information (PII) is gathered. You can use our services with the assurance that your personal details remain private.
|
||||
- **Aggregation**: Data is analyzed only in aggregate form. This practice ensures that patterns can be observed without revealing any individual user's activity.
|
||||
- **No Image Data Collection**: Ultralytics does not collect, process, or view any training or inference images.
|
||||
|
||||
## Sentry Crash Reporting
|
||||
|
||||
[Sentry](https://sentry.io/) is a developer-centric error tracking software that aids in identifying, diagnosing, and resolving issues in real-time, ensuring the robustness and reliability of applications. Within our package, it plays a crucial role by providing insights through crash reporting, significantly contributing to the stability and ongoing refinement of our software.
|
||||
|
||||
!!! Note
|
||||
|
||||
Crash reporting via Sentry is activated only if the `sentry-sdk` Python package is pre-installed on your system. This package isn't included in the `ultralytics` prerequisites and won't be installed automatically by Ultralytics.
|
||||
|
||||
### What We Collect
|
||||
|
||||
If the `sentry-sdk` Python package is pre-installed on your system a crash event may send the following information:
|
||||
|
||||
- **Crash Logs**: Detailed reports on the application's condition at the time of a crash, which are vital for our debugging efforts.
|
||||
- **Error Messages**: We record error messages generated during the operation of our package to understand and resolve potential issues quickly.
|
||||
|
||||
To learn more about how Sentry handles data, please visit [Sentry's Privacy Policy](https://sentry.io/privacy/).
|
||||
|
||||
### How We Use This Data
|
||||
|
||||
- **Debugging**: Analyzing crash logs and error messages enables us to swiftly identify and correct software bugs.
|
||||
- **Stability Metrics**: By constantly monitoring for crashes, we aim to improve the stability and reliability of our package.
|
||||
|
||||
### Privacy Considerations
|
||||
|
||||
- **Sensitive Information**: We ensure that crash logs are scrubbed of any personally identifiable or sensitive user data, safeguarding the confidentiality of your information.
|
||||
- **Controlled Collection**: Our crash reporting mechanism is meticulously calibrated to gather only what is essential for troubleshooting while respecting user privacy.
|
||||
|
||||
By detailing the tools used for data collection and offering additional background information with URLs to their respective privacy pages, users are provided with a comprehensive view of our practices, emphasizing transparency and respect for user privacy.
|
||||
|
||||
## Disabling Data Collection
|
||||
|
||||
We believe in providing our users with full control over their data. By default, our package is configured to collect analytics and crash reports to help improve the experience for all users. However, we respect that some users may prefer to opt out of this data collection.
|
||||
|
||||
To opt out of sending analytics and crash reports, you can simply set `sync=False` in your YOLO settings. This ensures that no data is transmitted from your machine to our analytics tools.
|
||||
|
||||
### Inspecting Settings
|
||||
|
||||
To gain insight into the current configuration of your settings, you can view them directly:
|
||||
|
||||
!!! Example "View settings"
|
||||
|
||||
=== "Python"
|
||||
You can use Python to view your settings. Start by importing the `settings` object from the `ultralytics` module. Print and return settings using the following commands:
|
||||
```python
|
||||
from ultralytics import settings
|
||||
|
||||
# View all settings
|
||||
print(settings)
|
||||
|
||||
# Return analytics and crash reporting setting
|
||||
value = settings['sync']
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
Alternatively, the command-line interface allows you to check your settings with a simple command:
|
||||
```bash
|
||||
yolo settings
|
||||
```
|
||||
|
||||
### Modifying Settings
|
||||
|
||||
Ultralytics allows users to easily modify their settings. Changes can be performed in the following ways:
|
||||
|
||||
!!! Example "Update settings"
|
||||
|
||||
=== "Python"
|
||||
Within the Python environment, call the `update` method on the `settings` object to change your settings:
|
||||
```python
|
||||
from ultralytics import settings
|
||||
|
||||
# Disable analytics and crash reporting
|
||||
settings.update({'sync': False})
|
||||
|
||||
# Reset settings to default values
|
||||
settings.reset()
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
If you prefer using the command-line interface, the following commands will allow you to modify your settings:
|
||||
```bash
|
||||
# Disable analytics and crash reporting
|
||||
yolo settings sync=False
|
||||
|
||||
# Reset settings to default values
|
||||
yolo settings reset
|
||||
```
|
||||
|
||||
The `sync=False` setting will prevent any data from being sent to Google Analytics or Sentry. Your settings will be respected across all sessions using the Ultralytics package and saved to disk for future sessions.
|
||||
|
||||
## Commitment to Privacy
|
||||
|
||||
Ultralytics takes user privacy seriously. We design our data collection practices with the following principles:
|
||||
|
||||
- **Transparency**: We are open about the data we collect and how it is used.
|
||||
- **Control**: We give users full control over their data.
|
||||
- **Security**: We employ industry-standard security measures to protect the data we collect.
|
||||
|
||||
## Questions or Concerns
|
||||
|
||||
If you have any questions or concerns about our data collection practices, please reach out to us via our [contact form](https://ultralytics.com/contact) or via [support@ultralytics.com](mailto:support@ultralytics.com). We are dedicated to ensuring our users feel informed and confident in their privacy when using our package.
|
||||
|
|
@ -1,36 +0,0 @@
|
|||
---
|
||||
description: Explore Ultralytics' comprehensive security strategies safeguarding user data and systems. Learn about our diverse security tools, including Snyk, GitHub CodeQL, and Dependabot Alerts.
|
||||
keywords: Ultralytics, Comprehensive Security, user data protection, Snyk, GitHub CodeQL, Dependabot, vulnerability management, coding security practices
|
||||
---
|
||||
|
||||
# Ultralytics Security Policy
|
||||
|
||||
At [Ultralytics](https://ultralytics.com), the security of our users' data and systems is of utmost importance. To ensure the safety and security of our [open-source projects](https://github.com/ultralytics), we have implemented several measures to detect and prevent security vulnerabilities.
|
||||
|
||||
## Snyk Scanning
|
||||
|
||||
We utilize [Snyk](https://snyk.io/advisor/python/ultralytics) to conduct comprehensive security scans on Ultralytics repositories. Snyk's robust scanning capabilities extend beyond dependency checks; it also examines our code and Dockerfiles for various vulnerabilities. By identifying and addressing these issues proactively, we ensure a higher level of security and reliability for our users.
|
||||
|
||||
[](https://snyk.io/advisor/python/ultralytics)
|
||||
|
||||
## GitHub CodeQL Scanning
|
||||
|
||||
Our security strategy includes GitHub's [CodeQL](https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/about-code-scanning-with-codeql) scanning. CodeQL delves deep into our codebase, identifying complex vulnerabilities like SQL injection and XSS by analyzing the code's semantic structure. This advanced level of analysis ensures early detection and resolution of potential security risks.
|
||||
|
||||
[](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml)
|
||||
|
||||
## GitHub Dependabot Alerts
|
||||
|
||||
[Dependabot](https://docs.github.com/en/code-security/dependabot) is integrated into our workflow to monitor dependencies for known vulnerabilities. When a vulnerability is identified in one of our dependencies, Dependabot alerts us, allowing for swift and informed remediation actions.
|
||||
|
||||
## GitHub Secret Scanning Alerts
|
||||
|
||||
We employ GitHub [secret scanning](https://docs.github.com/en/code-security/secret-scanning/managing-alerts-from-secret-scanning) alerts to detect sensitive data, such as credentials and private keys, accidentally pushed to our repositories. This early detection mechanism helps prevent potential security breaches and data exposures.
|
||||
|
||||
## Private Vulnerability Reporting
|
||||
|
||||
We enable private vulnerability reporting, allowing users to discreetly report potential security issues. This approach facilitates responsible disclosure, ensuring vulnerabilities are handled securely and efficiently.
|
||||
|
||||
If you suspect or discover a security vulnerability in any of our repositories, please let us know immediately. You can reach out to us directly via our [contact form](https://ultralytics.com/contact) or via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon as possible.
|
||||
|
||||
We appreciate your help in keeping all Ultralytics open-source projects secure and safe for everyone 🙏.
|
||||
|
|
@ -1,89 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Learn about the Ultralytics Android App, enabling real-time object detection using YOLO models. Discover in-app features, quantization methods, and delegate options for optimal performance.
|
||||
keywords: Ultralytics, Android App, real-time object detection, YOLO models, TensorFlow Lite, FP16 quantization, INT8 quantization, CPU, GPU, Hexagon, NNAPI
|
||||
---
|
||||
|
||||
# Ultralytics Android App: Real-time Object Detection with YOLO Models
|
||||
|
||||
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://user-images.githubusercontent.com/26833433/281124469-6b3b0945-dbb1-44c8-80a9-ef6bc778b299.jpg" alt="Ultralytics HUB preview image"></a>
|
||||
<br>
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app" style="text-decoration:none;">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/google-play.svg" width="15%" alt="Google Play store"></a>
|
||||
</div>
|
||||
|
||||
The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
|
||||
|
||||
## Quantization and Acceleration
|
||||
|
||||
To achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
|
||||
|
||||
### FP16 Quantization
|
||||
|
||||
FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.
|
||||
|
||||
### INT8 Quantization
|
||||
|
||||
INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision.
|
||||
|
||||
!!! Tip "mAP Reduction in INT8 Models"
|
||||
|
||||
The reduced numerical precision in INT8 models can lead to some loss of information during the quantization process, which may result in a slight decrease in mAP. However, this trade-off is often acceptable considering the substantial performance gains offered by INT8 quantization.
|
||||
|
||||
## Delegates and Performance Variability
|
||||
|
||||
Different delegates are available on Android devices to accelerate model inference. These delegates include CPU, [GPU](https://www.tensorflow.org/lite/android/delegates/gpu), [Hexagon](https://www.tensorflow.org/lite/android/delegates/hexagon) and [NNAPI](https://www.tensorflow.org/lite/android/delegates/nnapi). The performance of these delegates varies depending on the device's hardware vendor, product line, and specific chipsets used in the device.
|
||||
|
||||
1. **CPU**: The default option, with reasonable performance on most devices.
|
||||
2. **GPU**: Utilizes the device's GPU for faster inference. It can provide a significant performance boost on devices with powerful GPUs.
|
||||
3. **Hexagon**: Leverages Qualcomm's Hexagon DSP for faster and more efficient processing. This option is available on devices with Qualcomm Snapdragon processors.
|
||||
4. **NNAPI**: The Android Neural Networks API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core).
|
||||
|
||||
Here's a table showing the primary vendors, their product lines, popular devices, and supported delegates:
|
||||
|
||||
| Vendor | Product Lines | Popular Devices | Delegates Supported |
|
||||
|-----------------------------------------|--------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|
|
||||
| [Qualcomm](https://www.qualcomm.com/) | [Snapdragon (e.g., 800 series)](https://www.qualcomm.com/snapdragon) | [Samsung Galaxy S21](https://www.samsung.com/global/galaxy/galaxy-s21-5g/), [OnePlus 9](https://www.oneplus.com/9), [Google Pixel 6](https://store.google.com/product/pixel_6) | CPU, GPU, Hexagon, NNAPI |
|
||||
| [Samsung](https://www.samsung.com/) | [Exynos (e.g., Exynos 2100)](https://www.samsung.com/semiconductor/minisite/exynos/) | [Samsung Galaxy S21 (Global version)](https://www.samsung.com/global/galaxy/galaxy-s21-5g/) | CPU, GPU, NNAPI |
|
||||
| [MediaTek](https://i.mediatek.com/) | [Dimensity (e.g., Dimensity 1200)](https://i.mediatek.com/dimensity-1200) | [Realme GT](https://www.realme.com/global/realme-gt), [Xiaomi Redmi Note](https://www.mi.com/en/phone/redmi/note-list) | CPU, GPU, NNAPI |
|
||||
| [HiSilicon](https://www.hisilicon.com/) | [Kirin (e.g., Kirin 990)](https://www.hisilicon.com/en/products/Kirin) | [Huawei P40 Pro](https://consumer.huawei.com/en/phones/p40-pro/), [Huawei Mate 30 Pro](https://consumer.huawei.com/en/phones/mate30-pro/) | CPU, GPU, NNAPI |
|
||||
| [NVIDIA](https://www.nvidia.com/) | [Tegra (e.g., Tegra X1)](https://developer.nvidia.com/content/tegra-x1) | [NVIDIA Shield TV](https://www.nvidia.com/en-us/shield/shield-tv/), [Nintendo Switch](https://www.nintendo.com/switch/) | CPU, GPU, NNAPI |
|
||||
|
||||
Please note that the list of devices mentioned is not exhaustive and may vary depending on the specific chipsets and device models. Always test your models on your target devices to ensure compatibility and optimal performance.
|
||||
|
||||
Keep in mind that the choice of delegate can affect performance and model compatibility. For example, some models may not work with certain delegates, or a delegate may not be available on a specific device. As such, it's essential to test your model and the chosen delegate on your target devices for the best results.
|
||||
|
||||
## Getting Started with the Ultralytics Android App
|
||||
|
||||
To get started with the Ultralytics Android App, follow these steps:
|
||||
|
||||
1. Download the Ultralytics App from the [Google Play Store](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app).
|
||||
|
||||
2. Launch the app on your Android device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).
|
||||
|
||||
3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.
|
||||
|
||||
4. Grant the app permission to access your device's camera.
|
||||
|
||||
5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.
|
||||
|
||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||
|
||||
With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
|
||||
|
|
@ -1,48 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Explore the Ultralytics HUB App, offering the ability to run YOLOv5 and YOLOv8 models on your iOS and Android devices with optimized performance.
|
||||
keywords: Ultralytics, HUB App, YOLOv5, YOLOv8, mobile AI, real-time object detection, image recognition, mobile device, hardware acceleration, Apple Neural Engine, Android GPU, NNAPI, custom model training
|
||||
---
|
||||
|
||||
# Ultralytics HUB App
|
||||
|
||||
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png" alt="Ultralytics HUB preview image"></a>
|
||||
<br>
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://apps.apple.com/xk/app/ultralytics/id1583935240" style="text-decoration:none;">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/app-store.svg" width="15%" alt="Apple App store"></a>
|
||||
<a href="https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app" style="text-decoration:none;">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/google-play.svg" width="15%" alt="Google Play store"></a>
|
||||
</div>
|
||||
|
||||
Welcome to the Ultralytics HUB App! We are excited to introduce this powerful mobile app that allows you to run YOLOv5 and YOLOv8 models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) and [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) devices. With the HUB App, you can utilize hardware acceleration features like Apple's Neural Engine (ANE) or Android GPU and Neural Network API (NNAPI) delegates to achieve impressive performance on your mobile device.
|
||||
|
||||
## Features
|
||||
|
||||
- **Run YOLOv5 and YOLOv8 models**: Experience the power of YOLO models on your mobile device for real-time object detection and image recognition tasks.
|
||||
- **Hardware Acceleration**: Benefit from Apple ANE on iOS devices or Android GPU and NNAPI delegates for optimized performance.
|
||||
- **Custom Model Training**: Train custom models with the Ultralytics HUB platform and preview them live using the HUB App.
|
||||
- **Mobile Compatibility**: The HUB App supports both iOS and Android devices, bringing the power of YOLO models to a wide range of users.
|
||||
|
||||
## App Documentation
|
||||
|
||||
- [**iOS**](ios.md): Learn about YOLO CoreML models accelerated on Apple's Neural Engine for iPhones and iPads.
|
||||
- [**Android**](android.md): Explore TFLite acceleration on Android mobile devices.
|
||||
|
||||
Get started today by downloading the Ultralytics HUB App on your mobile device and unlock the potential of YOLOv5 and YOLOv8 models on-the-go. Don't forget to check out our comprehensive [HUB Docs](../index.md) for more information on training, deploying, and using your custom models with the Ultralytics HUB platform.
|
||||
|
|
@ -1,79 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Execute object detection in real-time on your iOS devices utilizing YOLO models. Leverage the power of the Apple Neural Engine and Core ML for fast and efficient object detection.
|
||||
keywords: Ultralytics, iOS app, object detection, YOLO models, real time, Apple Neural Engine, Core ML, FP16, INT8, quantization
|
||||
---
|
||||
|
||||
# Ultralytics iOS App: Real-time Object Detection with YOLO Models
|
||||
|
||||
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://user-images.githubusercontent.com/26833433/281124469-6b3b0945-dbb1-44c8-80a9-ef6bc778b299.jpg" alt="Ultralytics HUB preview image"></a>
|
||||
<br>
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
||||
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://apps.apple.com/xk/app/ultralytics/id1583935240" style="text-decoration:none;">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/app-store.svg" width="15%" alt="Apple App store"></a>
|
||||
</div>
|
||||
|
||||
The Ultralytics iOS App is a powerful tool that allows you to run YOLO models directly on your iPhone or iPad for real-time object detection. This app utilizes the Apple Neural Engine and Core ML for model optimization and acceleration, enabling fast and efficient object detection.
|
||||
|
||||
## Quantization and Acceleration
|
||||
|
||||
To achieve real-time performance on your iOS device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
|
||||
|
||||
### FP16 Quantization
|
||||
|
||||
FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.
|
||||
|
||||
### INT8 Quantization
|
||||
|
||||
INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in accuracy.
|
||||
|
||||
## Apple Neural Engine
|
||||
|
||||
The Apple Neural Engine (ANE) is a dedicated hardware component integrated into Apple's A-series and M-series chips. It's designed to accelerate machine learning tasks, particularly for neural networks, allowing for faster and more efficient execution of your YOLO models.
|
||||
|
||||
By combining quantized YOLO models with the Apple Neural Engine, the Ultralytics iOS App achieves real-time object detection on your iOS device without compromising on accuracy or performance.
|
||||
|
||||
| Release Year | iPhone Name | Chipset Name | Node Size | ANE TOPs |
|
||||
|--------------|------------------------------------------------------|-------------------------------------------------------|-----------|----------|
|
||||
| 2017 | [iPhone X](https://en.wikipedia.org/wiki/IPhone_X) | [A11 Bionic](https://en.wikipedia.org/wiki/Apple_A11) | 10 nm | 0.6 |
|
||||
| 2018 | [iPhone XS](https://en.wikipedia.org/wiki/IPhone_XS) | [A12 Bionic](https://en.wikipedia.org/wiki/Apple_A12) | 7 nm | 5 |
|
||||
| 2019 | [iPhone 11](https://en.wikipedia.org/wiki/IPhone_11) | [A13 Bionic](https://en.wikipedia.org/wiki/Apple_A13) | 7 nm | 6 |
|
||||
| 2020 | [iPhone 12](https://en.wikipedia.org/wiki/IPhone_12) | [A14 Bionic](https://en.wikipedia.org/wiki/Apple_A14) | 5 nm | 11 |
|
||||
| 2021 | [iPhone 13](https://en.wikipedia.org/wiki/IPhone_13) | [A15 Bionic](https://en.wikipedia.org/wiki/Apple_A15) | 5 nm | 15.8 |
|
||||
| 2022 | [iPhone 14](https://en.wikipedia.org/wiki/IPhone_14) | [A16 Bionic](https://en.wikipedia.org/wiki/Apple_A16) | 4 nm | 17.0 |
|
||||
|
||||
Please note that this list only includes iPhone models from 2017 onwards, and the ANE TOPs values are approximate.
|
||||
|
||||
## Getting Started with the Ultralytics iOS App
|
||||
|
||||
To get started with the Ultralytics iOS App, follow these steps:
|
||||
|
||||
1. Download the Ultralytics App from the [App Store](https://apps.apple.com/xk/app/ultralytics/id1583935240).
|
||||
|
||||
2. Launch the app on your iOS device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).
|
||||
|
||||
3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.
|
||||
|
||||
4. Grant the app permission to access your device's camera.
|
||||
|
||||
5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.
|
||||
|
||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||
|
||||
With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
|
||||
|
|
@ -1,159 +0,0 @@
|
|||
---
|
||||
comments: true
|
||||
description: Learn how Ultralytics HUB datasets streamline your ML workflow. Upload, format, validate, access, share, edit or delete datasets for Ultralytics YOLO model training.
|
||||
keywords: Ultralytics, HUB datasets, YOLO model training, upload datasets, dataset validation, ML workflow, share datasets
|
||||
---
|
||||
|
||||
# HUB Datasets
|
||||
|
||||
[Ultralytics HUB](https://hub.ultralytics.com/) datasets are a practical solution for managing and leveraging your custom datasets.
|
||||
|
||||
Once uploaded, datasets can be immediately utilized for model training. This integrated approach facilitates a seamless transition from dataset management to model training, significantly simplifying the entire process.
|
||||
|
||||
## Upload Dataset
|
||||
|
||||
Ultralytics HUB datasets are just like YOLOv5 and YOLOv8 🚀 datasets. They use the same structure and the same label formats to keep everything simple.
|
||||
|
||||
Before you upload a dataset to Ultralytics HUB, make sure to **place your dataset YAML file inside the dataset root directory** and that **your dataset YAML, directory and ZIP have the same name**, as shown in the example below, and then zip the dataset directory.
|
||||
|
||||
For example, if your dataset is called "coco8", as our [COCO8](https://docs.ultralytics.com/datasets/detect/coco8) example dataset, then you should have a `coco8.yaml` inside your `coco8/` directory, which will create a `coco8.zip` when zipped:
|
||||
|
||||
```bash
|
||||
zip -r coco8.zip coco8
|
||||
```
|
||||
|
||||
You can download our [COCO8](https://github.com/ultralytics/hub/blob/main/example_datasets/coco8.zip) example dataset and unzip it to see exactly how to structure your dataset.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/ultralytics/assets/main/docs/hub/datasets/hub_upload_dataset_1.jpg" alt="COCO8 Dataset Structure" width="80%">
|
||||
</p>
|
||||
|
||||
The dataset YAML is the same standard YOLOv5 and YOLOv8 YAML format.
|
||||
|
||||
!!! Example "coco8.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/coco8.yaml"
|
||||
```
|
||||
|
||||
After zipping your dataset, you should validate it before uploading it to Ultralytics HUB. Ultralytics HUB conducts the dataset validation check post-upload, so by ensuring your dataset is correctly formatted and error-free ahead of time, you can forestall any setbacks due to dataset rejection.
|
||||
|
||||
```py
|
||||
from ultralytics.hub import check_dataset
|
||||
|
||||
check_dataset('path/to/coco8.zip')
|
||||
```
|
||||
|
||||
Once your dataset ZIP is ready, navigate to the [Datasets](https://hub.ultralytics.com/datasets) page by clicking on the **Datasets** button in the sidebar.
|
||||
|
||||
|
||||
|
||||
??? tip "Tip"
|
||||
|
||||
You can also upload a dataset directly from the [Home](https://hub.ultralytics.com/home) page.
|
||||
|
||||
|
||||
|
||||
Click on the **Upload Dataset** button on the top right of the page. This action will trigger the **Upload Dataset** dialog.
|
||||
|
||||
|
||||
|
||||
Upload your dataset in the _Dataset .zip file_ field.
|
||||
|
||||
You have the additional option to set a custom name and description for your Ultralytics HUB dataset.
|
||||
|
||||
When you're happy with your dataset configuration, click **Upload**.
|
||||
|
||||
|
||||
|
||||
After your dataset is uploaded and processed, you will be able to access it from the Datasets page.
|
||||
|
||||
|
||||
|
||||
You can view the images in your dataset grouped by splits (Train, Validation, Test).
|
||||
|
||||
|
||||
|
||||
??? tip "Tip"
|
||||
|
||||
Each image can be enlarged for better visualization.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Also, you can analyze your dataset by click on the **Overview** tab.
|
||||
|
||||

|
||||
|
||||
Next, [train a model](https://docs.ultralytics.com/hub/models/#train-model) on your dataset.
|
||||
|
||||

|
||||
|
||||
## Share Dataset
|
||||
|
||||
!!! Info "Info"
|
||||
|
||||
Ultralytics HUB's sharing functionality provides a convenient way to share datasets with others. This feature is designed to accommodate both existing Ultralytics HUB users and those who have yet to create an account.
|
||||
|
||||
??? note "Note"
|
||||
|
||||
You have control over the general access of your datasets.
|
||||
|
||||
You can choose to set the general access to "Private", in which case, only you will have access to it. Alternatively, you can set the general access to "Unlisted" which grants viewing access to anyone who has the direct link to the dataset, regardless of whether they have an Ultralytics HUB account or not.
|
||||
|
||||
Navigate to the Dataset page of the dataset you want to share, open the dataset actions dropdown and click on the **Share** option. This action will trigger the **Share Dataset** dialog.
|
||||
|
||||
|
||||
|
||||
??? tip "Tip"
|
||||
|
||||
You can also share a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
|
||||
|
||||
|
||||
|
||||
Set the general access to "Unlisted" and click **Save**.
|
||||
|
||||
|
||||
|
||||
Now, anyone who has the direct link to your dataset can view it.
|
||||
|
||||
??? tip "Tip"
|
||||
|
||||
You can easily click on the dataset's link shown in the **Share Dataset** dialog to copy it.
|
||||
|
||||
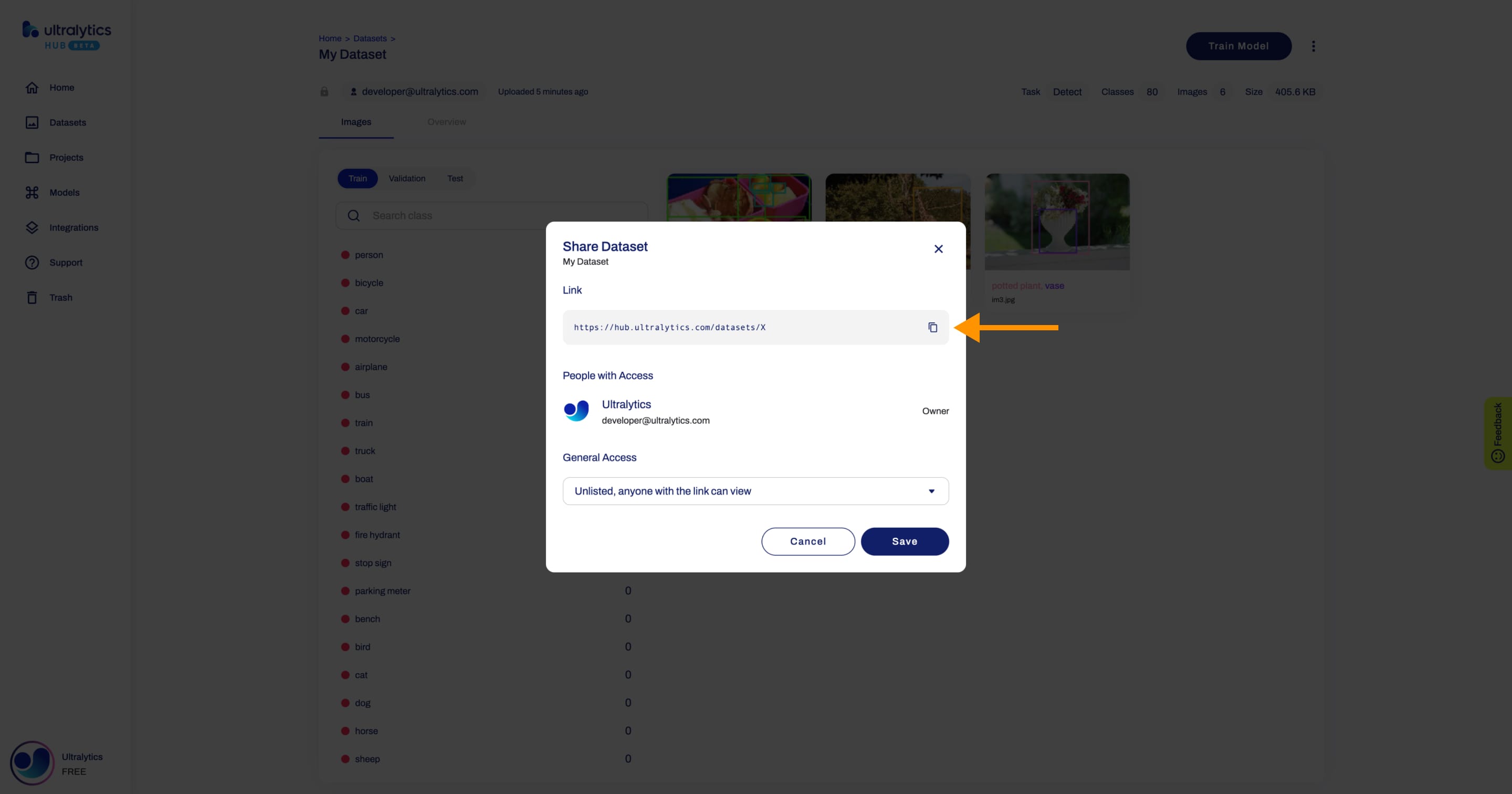
|
||||
|
||||
## Edit Dataset
|
||||
|
||||
Navigate to the Dataset page of the dataset you want to edit, open the dataset actions dropdown and click on the **Edit** option. This action will trigger the **Update Dataset** dialog.
|
||||
|
||||
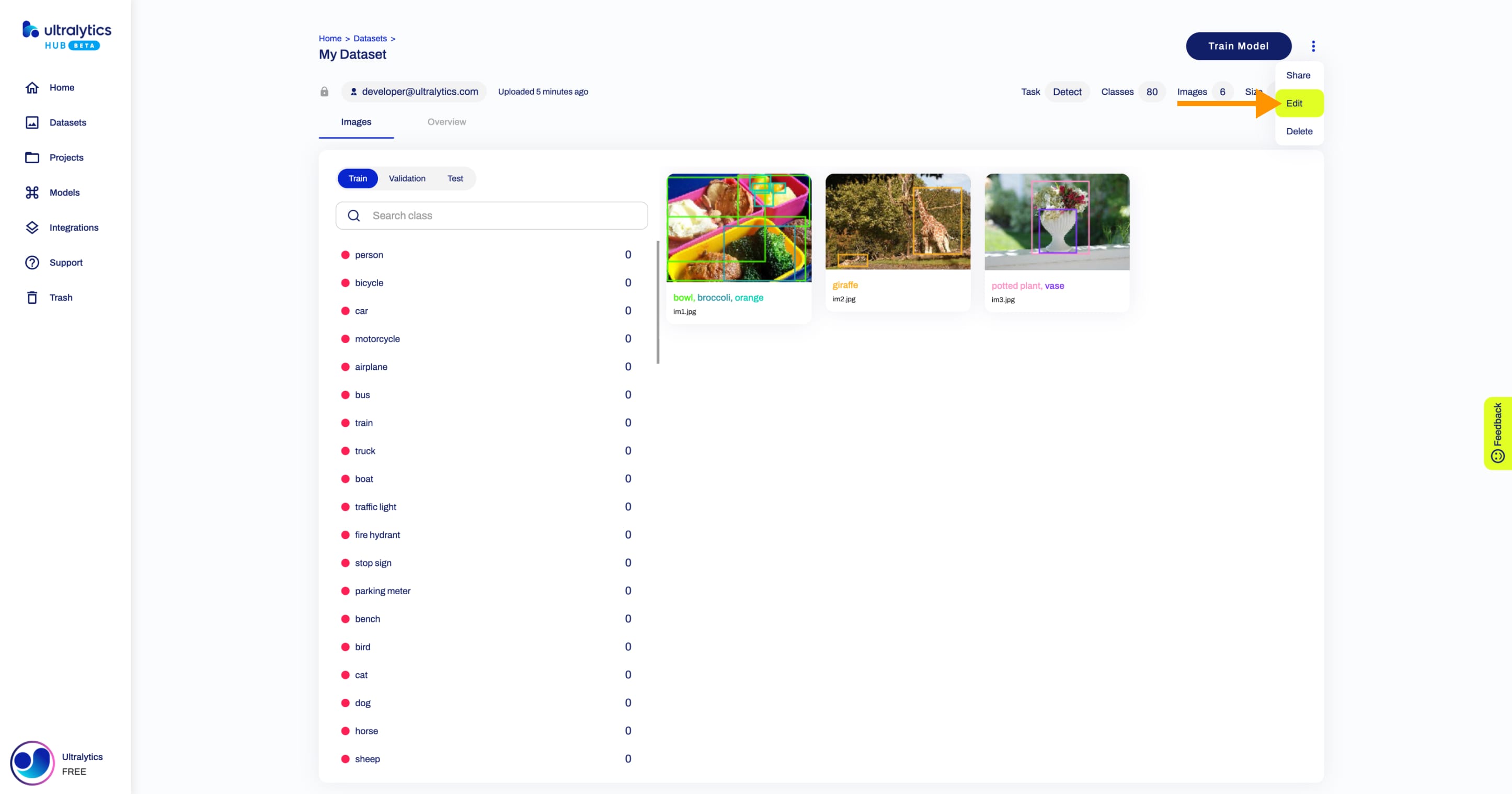
|
||||
|
||||
??? tip "Tip"
|
||||
|
||||
You can also edit a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
|
||||
|
||||
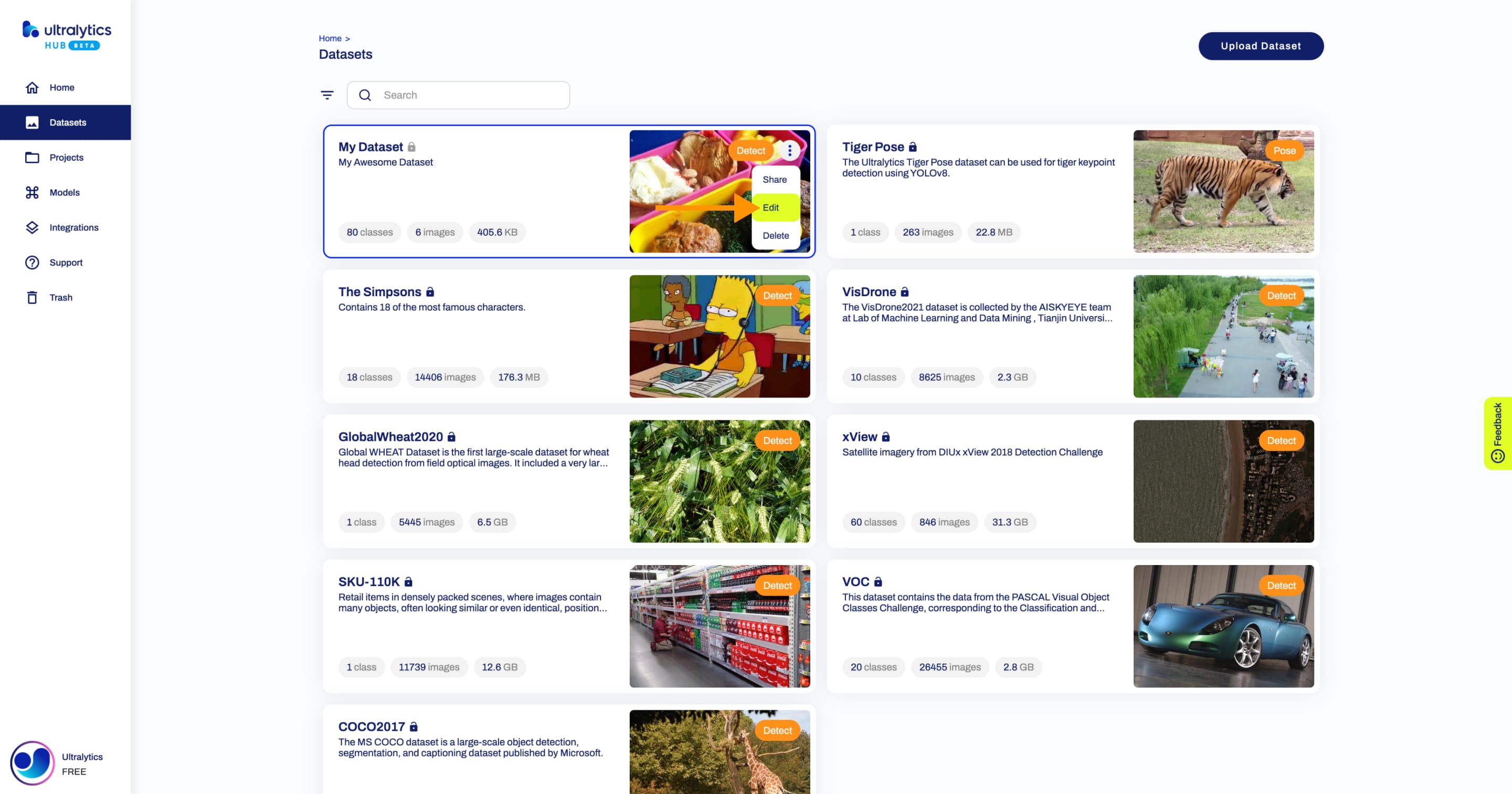
|
||||
|
||||
Apply the desired modifications to your dataset and then confirm the changes by clicking **Save**.
|
||||
|
||||
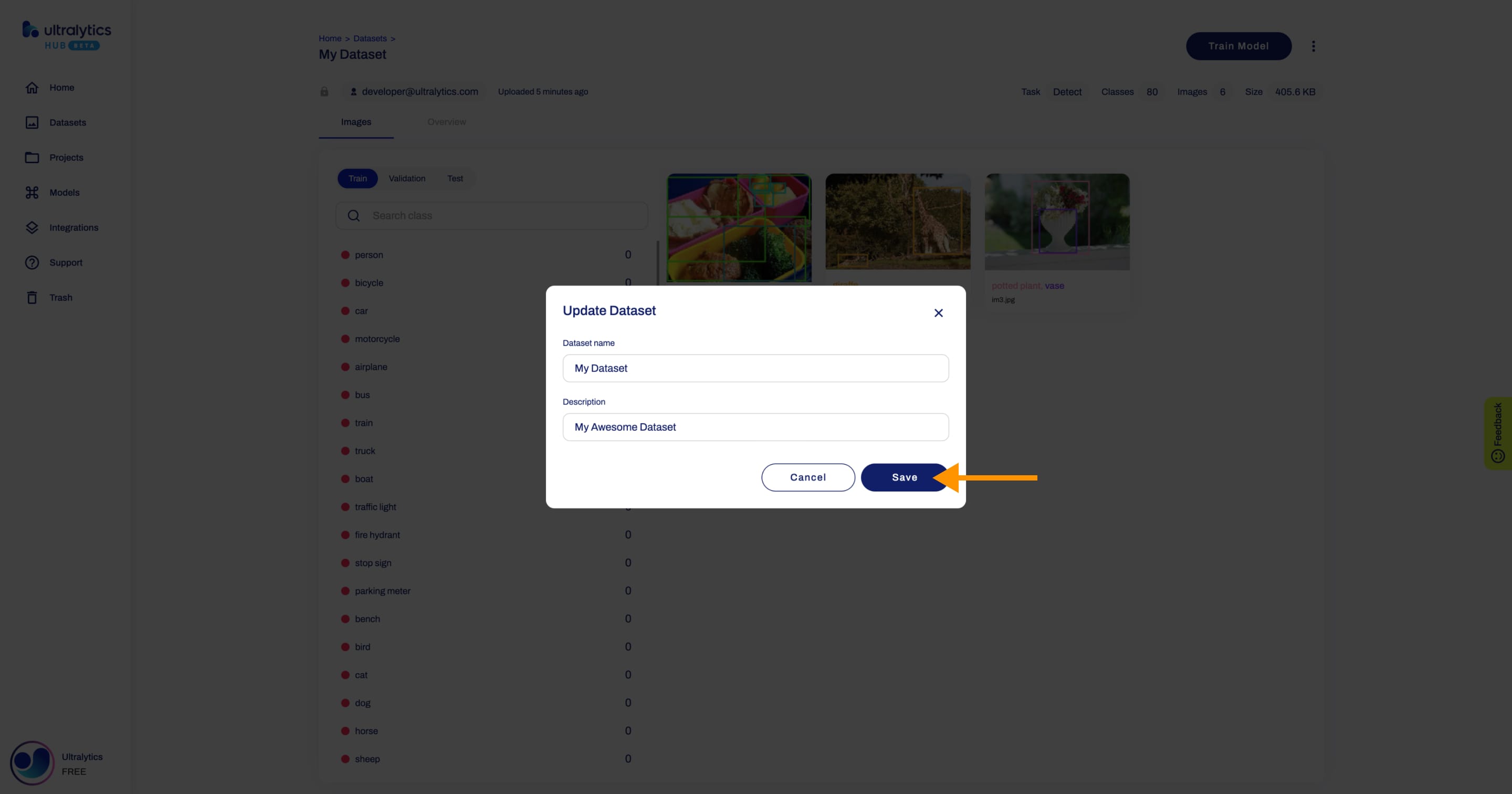
|
||||
|
||||
## Delete Dataset
|
||||
|
||||
Navigate to the Dataset page of the dataset you want to delete, open the dataset actions dropdown and click on the **Delete** option. This action will delete the dataset.
|
||||
|
||||
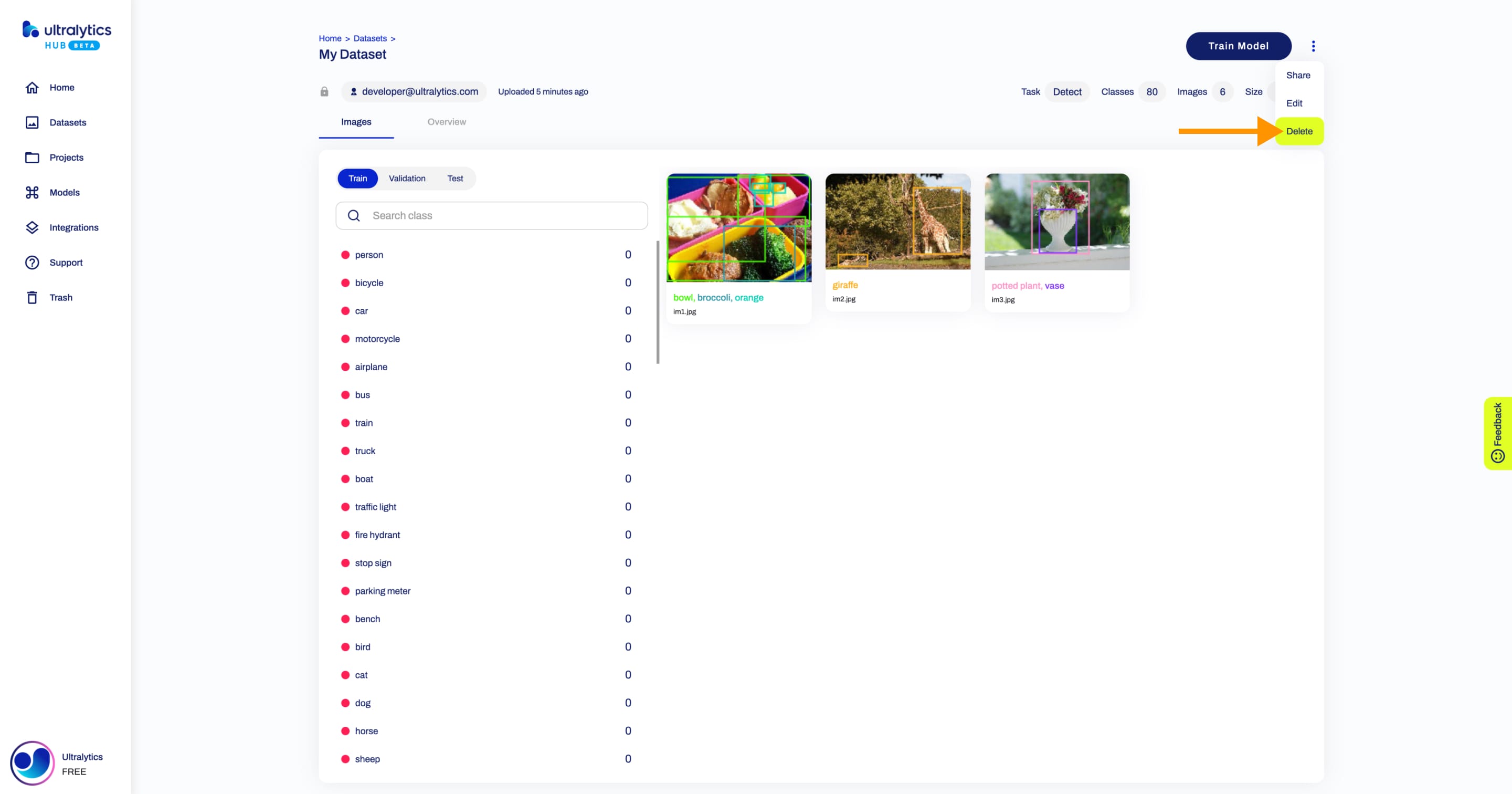
|
||||
|
||||
??? tip "Tip"
|
||||
|
||||
You can also delete a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
|
||||
|
||||
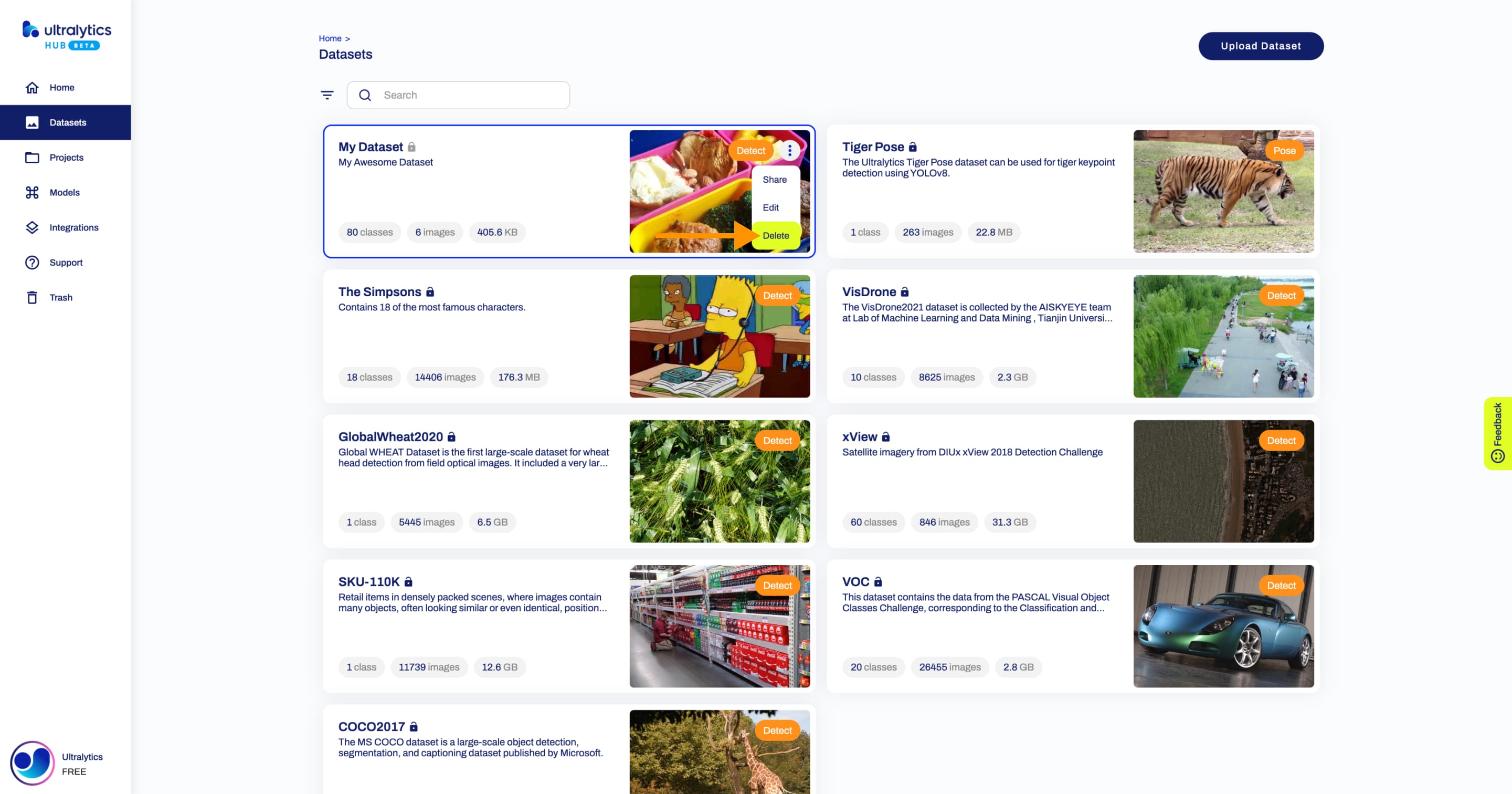
|
||||
|
||||
??? note "Note"
|
||||
|
||||
If you change your mind, you can restore the dataset from the [Trash](https://hub.ultralytics.com/trash) page.
|
||||
|
||||
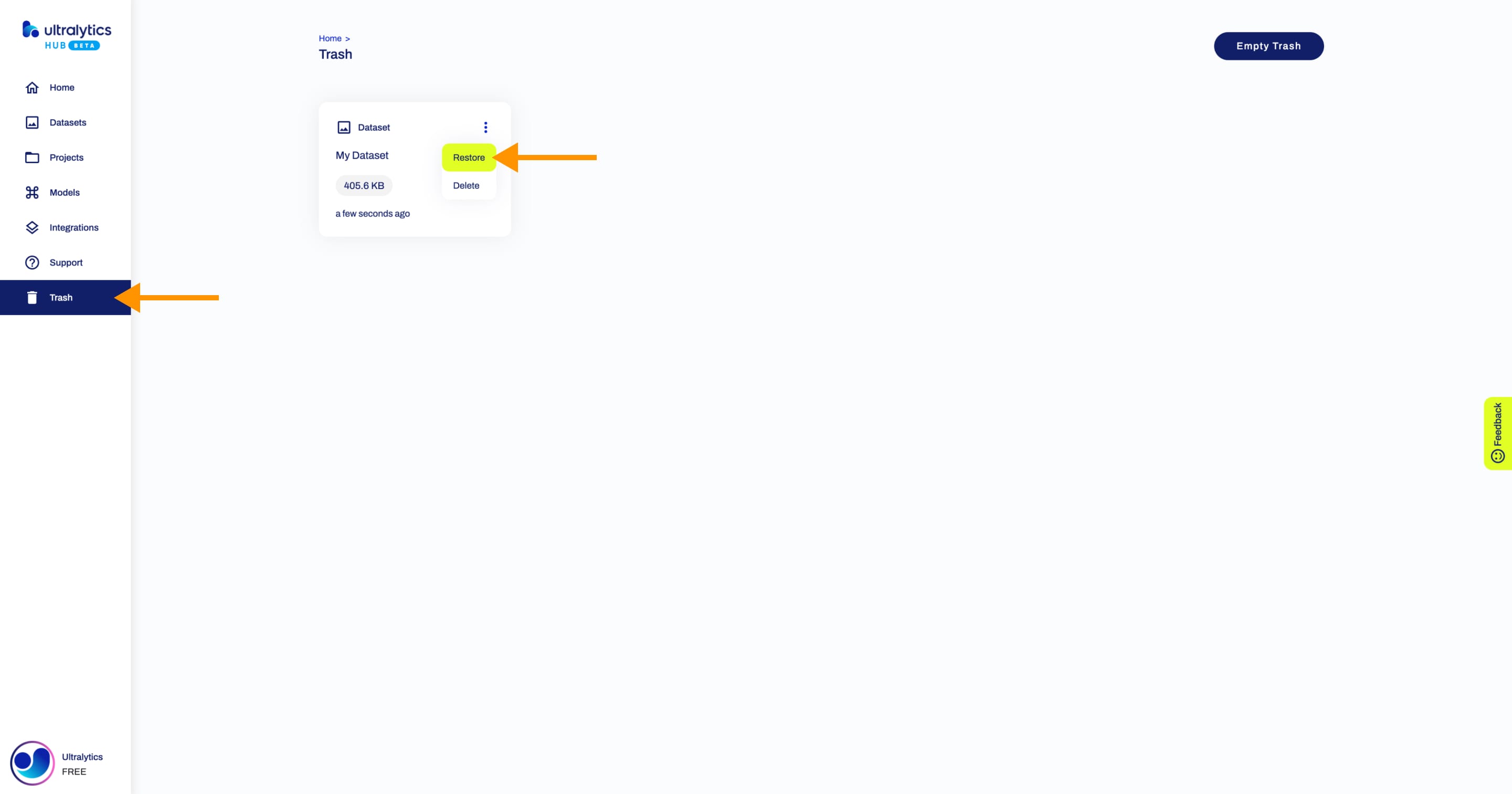
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue